https://arxiv.org/abs/2106.06103
Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech
Several recent end-to-end text-to-speech (TTS) models enabling single-stage training and parallel sampling have been proposed, but their sample quality does not match that of two-stage TTS systems. In this work, we present a parallel end-to-end TTS method
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 등장한 end-to-end TTS model들은 single-stage training이 가능하지만, two-stage TTS system과 비교하지 못할 정도로 quality가 떨어집니다. 이 논문에서 저자들은 parallel end-to-end TTS method를 제안합니다. 이 method는 현재 존재하는 two-stage model과 비교했을 때 더 자연스러운 audio를 생성할 수 있습니다. 저자들의 method는 variational inference augmented with normalizing flow와 adversarial training process를 사용합니다. 이를 통해 생성 model의 표현력을 향상시킬 수 있었습니다. 그리고 stochastic duration predictor를 사용하여 input text로부터 다양한 rhythm을 보이는 speech를 합성할 수 있었습니다. latent variable의 uncertainty modeling과 stochastic duration predictor를 통해, 저자들의 method는 자연스러운 one-to-many relationship (text input이 다양한 pitch와 rhythm을 보이는 다양한 방식으로 발음될 수 있음)을 표현합니다. LJSpeech dataset을 이용해 subjective human evaluation (mean opinion score, MOS)을 측정했으며, 저자들의 method는 공개되고 사용 가능한 TTS system보다 더 좋은 성능을 보였고 ground-truth와 비교 가능한 MOS 결과를 보였습니다.
Introduction
TTS system은 주어진 text를 여러 component로 처리해서 raw speech waveform을 생성합니다. deep neural network가 빠르게 발전하면서 TTS system pipeline은 text normalization, phonemization과 같은 text preprocssing을 제외한 two-stage generative modelling으로 간단하게 구현 가능합니다. first stage는 pre-processed text로 mel-spectrogram이나 linguistic feature와 같은 중간 speech representation을 생성하고, second stage는 중간 representation을 condition으로 하여 raw waveform을 생성합니다. 각 two-stage pipeline model들은 서로 독립적으로 개발됩니다.
Neural network-based autoregressive TTS system은 실제같은 speech를 합성할 수 있는 능력을 갖고 있지만, system의 sequential generative process 때문에 fully parallel processor를 이용하는 데 어려움이 존재합니다. 이러한 제한점을 해결하고 합성 속도를 높이기 위해, 여러 non-autoregressive method들이 제안되었습니다. text-to-speech generation step에서, pre-trained autoregressive teacher network로부터 attention map을 추출하는 것은 text와 spectrogram의 alignment를 학습하는 것에 대한 어려움을 줄일 수 있었습니다. 더 최근에는 external aligner의 의존성을 더 줄일 수 있는 likelihood based method가 등장했습니다. 이는 target mel-spectrogram에 대한 likelihood를 maximize하도록 alignment를 학습하는 방식입니다.
second stage model로는 GAN을 많이 사용했습니다. 서로 다른 scale과 period의 sample들에 대해 구별을 수행하는 여러 개의 discriminator를 사용하는 GAN-based feed-forward network들이 등장했으며, 이 model은 고품질의 raw waveform 합성이 가능했습니다.
parallel TTS system의 발전에도 불구하고, 이전 stage model의 generated sample로 학습된 latter stage model이 고품질의 output을 만들기 위해서 two-stage pipeline은 sequential training을 해야하고 fine-tuning이 필요하다는 문제가 존재했습니다. 추가적으로 사전 정의된 중간 feature에 대한 의존성 때문에, 학습된 hidden representation을 사용하여 performance를 향상시키는 것을 불가능했습니다. 최근에 몇몇 연구들은 효과적인 end-to-end training method를 제안하는데, 전체 waveform을 사용하는 대신 짧은 audio clip을 사용하여 학습하는 방법을 제안합니다. 그리고 text representation을 학습하기 위해 mel-spectrogram decoder를 사용하고 구체적으로 spectrogram loss를 design하는 것은 target speech와 생성된 speech 사이의 length mismatch를 해결할 수 있었습니다. 하지만, 학습된 representation을 이용하여 잠재적인 성능 향상에도 불구하고 two-stage system에 비해 합성 quality가 떨어집니다.
그래서 이 논문에서 저자들은 최근 two-stage model보다 더 자연스럽게 들리는 audio를 생성하는 parallel end-to-end TTS method를 제안합니다. VAE를 사용하여 저자들은 TTS syetm의 두 module을 connect했고, latent variable을 이용하여 효과적으로 end-to-end learning이 가능했습니다. 저자들의 method의 expressive power를 향상시켜 high quality의 speech waveform을 합성하기 위해, 저자들은 conditional prior distribution에 normalizing flow를 적용하고 waveform domain에서 adversarial training을 진행합니다. 추가적으로 세밀한 audio를 생성하기 위해선 TTS system이 text input에 대해 다양한 variation (e.g., pitch and duration)을 포함하도록 one-to-many relationship을 표현하는 것이 중요합니다. one-to-many 문제를 풀기 위해, 저자들은 input text에 대해서 다양한 rhythm의 speech를 합성하기 위해서 stochatstic duration predictor를 제안합니다. latent variable과 stochastic duration predictor를 이용하여 uncerntainty를 modelling하는 방식으로 저자들의 method는 text로 표현할 수 없는 speech variation을 capture할 수 있습니다.
저자들의 method는 더 자연스럽게 들리는 speech를 생성하고 공개된 TTS system들(Glow-TTS, HiFiGAN)보다 더 좋은 sampling 효율성을 보여줍니다.
Method
Variational Inference
- Overview
Variational Inference with adversarial learning for end-to-end Text-to-Speech (VITS)는 풀 수 없는 data marginal log-likelihood log p_θ(x|c)에 대한 variational lower bound (evidence lower bound, ELBO라 불리기도 함)를 maximize하는 conditional VAE로 볼 수 있습니다.

식으로 나타내면 위와 같습니다. 여기서 p_θ(z|c)는 condition c가 주어졌을 때, latent variable z의 prior distribution을 나타냅니다. p_θ(x|z)는 data point x에 대한 likelihood function을 나타냅니다. q_θ(z|x)는 posterior distribution을 근사한 결과입니다. training loss는 negative ELBO 가 되며, reconstruction loss (-p_θ(x|z))와 KL divergence loss(log q_θ(z|x) - log p_θ(z|c))의 summation으로 볼 수 있습니다.
- Reconstruction loss
reconstruction loss에서 target data point로, 저자들은 raw waveform 대신 mel-spectrogram을 사용합니다. 저자들은 decoder를 이용해 latent variable z를 waveform domain y^으로 upsample하고 y^를 mel-spectrogram domain x^_mel로 transform합니다. 그렇게 해서 predicted mel-spectrogram과 target mel-spectrogram 사이의 L1 loss를 reconstruction loss로 사용합니다.

이는 data distribution에 대해 Laplace distribution로 가정하고 constant term을 무시하는 maximum likelihood estimation으로 볼 수 있습니다. reconstruction loss를 mel-spectrogram domain에 정의하여 perceptual quality를 향상시킬 수 있었습니다. 여기서 mel-scale을 사용했는데, mel-scale은 인간의 청각 기관을 근사했으며, mel-spectrogram domain에 reconstruction loss를 적용하는 것이 perceptual quality를 향상시킬 수 있다고 합니다. raw waveform으로부터 mel-spectrogram을 추정하는 것은 STFT와 mel-scale로의 linear projection만 사용하며 학습할 parameter가 없습니다. 그리고 estimation은 training할 때만 사용되며, inference할 때는 사용되지 않습니다. 모든 latent variable z를 upsample하지 않고 일부 sequence만 decoder의 input으로 사용합니다. 이와 같은 windowed generator training은 효과적으로 end-to-end 학습이 가능하다고 합니다.
- KL-Divergence
prior encoder c의 input condition은 text에서 추출된 phoneme c_text, phoneme과 latent variable 사이의 alignment A로 구성됩니다. alignment는 각 input phoneme이 target speech에 맞춰 시간별로 얼마나 확장되어 길어지는지를 나타내는 엄격한 단조적인 attention matrix 입니다. 이 matrix는 |c_text| x |z|차원입니다. alignment에 대한 ground-truth가 없기 때문에, 저자들은 각 training iteration마다 alignment를 추정해야만 합니다.
이러한 실험 setting에서 저자들은 posterior encoder에 더 많은 high-resolution information을 제공하는 것을 목표로 합니다. 그래서 저자들은 target speech x_lin의 linear-scale spectrogram을 input으로 사용합니다(mel-spectrogram 사용x). linear-scale spectrogram을 사용하는 것이 variational inference의 특성을 위반하지 않습니다. 이를 통해 KL divergence 식은 다음과 같습니다.

prior encoder와 posterior encoder를 parameterize하기 위해 normal distribution factorize를 사용합니다. realistic sample을 생성하기 위해 prior distribution의 표현력을 향상시키는 것이 중요하다 합니다. 그러므로 저자들은 normalizing flow를 사용합니다. normalizing flow는 variable을 변환하는 rule을 따라 단순한 distribution을 더 복잡한 distribution으로 변환시키는 기술입니다. 여기서 변환은 invertible해야 합니다. 이 변환의 마지막에는 factorized normal prior distribution이 되도록 normalizing flow를 구현하면 됩니다.

Alignment Estimation
- Monotonic Alignment Search
input text와 target speech 사이의 alignmen A를 추정하기 위해, 저자들은 Monotonic Alignment Search (MAS)를 사용합니다. 이는 normalizing flow f에 의해 parameterize된 data의 likelihood를 maximize하는 alignment를 찾는 method입니다.
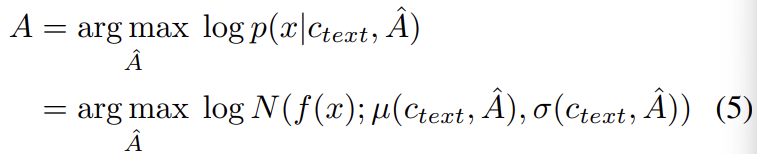
후보 alignment들은 monotonic하도록 제약되며, 인간은 단어를 생략하지 않으며 text를 읽는다는 사실을 따라 skip하지 못하도록 제약이 됩니다. optimal alignment를 찾기 위해 dynamic programming을 사용합니다. 저자들의 method에 MAS를 바로 적용하는 것은 어렵습니다. 왜냐하면 저자들의 model은 ELBO를 사용하는데, 이는 정확한 log-likelihood가 아니기 때문입니다. 그래서 저자들은 ELBO를 maximize하는 alignment를 찾아주는 MAS를 새로 정의했으며, 이는 latent variable z의 log-likelihood를 maximize하는 alignment를 찾는 방식입니다.
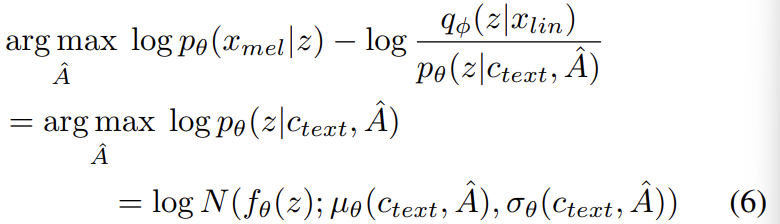
위 식과 original MAS와 유사하기 때문에, 저자들은 위 식을 구현할 때 original MAS를 그대로 사용했다고 합니다
- Duration Prediction from Text
저자들은 추정된 alignment A에 대해서 각 row에서 모든 column을 summation하여 각 input token d_i에 대한 duration을 구할 수 있습니다. alignment A_{i, j}는 i번째 phoneme이 j번째 frame에서 어떻게 대응하는지 나타냅니다. 그렇기 때문에 column을 summation하면 해당 audio에서 phoneme의 duration을 구할 수 있게 됩니다. 하지만, 이 방식은 사람이 다른 속도로 발음하는 것에 대한 표현은 할 수 없습니다. 사람처럼 speech의 rhythm을 생성하기 위해 저자들은 shotchastic duration predictor를 구현했으며, 주어진 phoneme에 대한 duration distribution에서 duration을 sample하는 방식입니다. stochastic duration predictor는 flow-based generative model인데, 이는 MLE 방식으로 학습됩니다. 하지만 MLE을 직접적으로 적용하는 것은 어렵습니다. 왜냐하면 각 input phoneme의 duration은 discrete integer이기 때문에 continuous normalizing flow를 사용하기 위해선 dequantized를 해야 합니다. 그리고 input phoneme의 duration은 scalar이며 invertibility 때문에 고차원 transformation을 방지합니다(scalar가 아니라 더 고차원이었다면, 고차원으로 transformation을 할 수 있음). 그래서 저자들은 variational dequantization과 variational data augmentation을 사용하여 이 문제를 해결했습니다. 구체적으로 저자들은 random variable u, v를 사용하는데, 둘 다 duration sequence d와 동일한 resolution과 dimension을 갖고 u는 variational dequantization에 사용되고 v는 variational data augmentation에 사용됩니다. u는 [0, 1)로 제약을 두었으며 d-u는 positive real number sequence가 됩니다. 그리고 v와 d를 channel-wise하게 concatenate하여 더 고차원의 latent representation을 만들었습니다. 저자들은 근사 posterior distribution q_Θ(u, v | d, c_text)에서 두 variable을 sample했습니다. phoneme duration의 log-likelihood의 variational lower-bound는 다음과 같습니다.
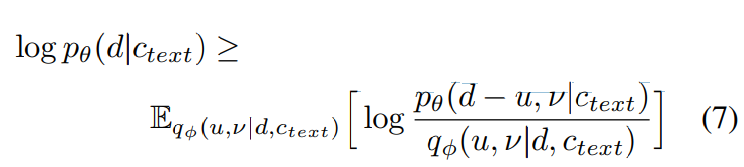
training loss L_dur는 negative variational lower bound가 됩니다. 저자들은 stop gradient operator를 사용하는데, 이는 input의 gradient가 back-propagation하는 것을 막으며 이를 통해 duration predictor의 학습이 다른 module에 영향을 주지 못하게 만들었습니다.
sampling과정은 간단합니다. phoneme duration은 stochastic duration predictor의 inverse transformation을 통해 random noise로부터 구해지며, 이를 integer로 변환하면 됩니다.
Adversarial Training
저자들은 adversarial training을 진행합니다. discriminator D를 추가하여 decoder G의 generated output과 ground truth waveform y를 구분합니다. 이 논문에서 저자들은 speech synthesis에서 성곡적으로 사용되었던 두 loss를 사용합니다. least-square loss funciton을 이용한 adversarial training과 additional feature matching loss를 이용한 geneartor training입니다. 식은 다음과 같습니다.
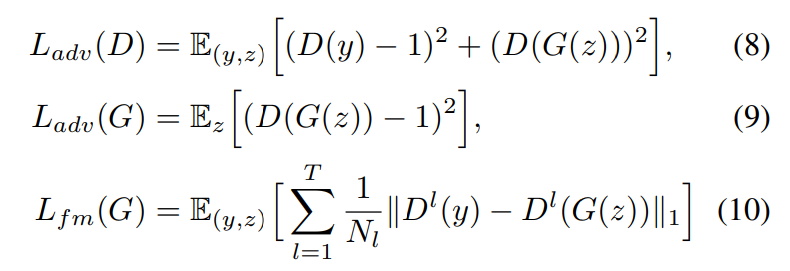
여기서 T는 discriminator에 존재하는 총 layer 수를 의미하고 D^l은 discriminator의 l번째 layer의 feature map을 의미하고 총 N_l개 feature가 존재합니다. feature matching loss는 reconstruction loss처럼 볼 수 있는데, 이는 VAE의 element-wise reconstruction loss의 대안책으로 discriminator의 hidden layer에 적용한 모습입니다.
Final Loss
저자들은 VAE와 GAN training을 결합하여 최종 conditional VAE 학습을 위한 loss를 정의했습니다.

Model Architecture
저자들의 model은 posterior encoder, prior encoder, decoder, discriminator, stochastic duration predictor로 구성됩니다. posterior encoder와 discriminator는 training할 때만 사용되며, inference 시에는 사용되지 않습니다. 전체 구조는 다음과 같습니다.
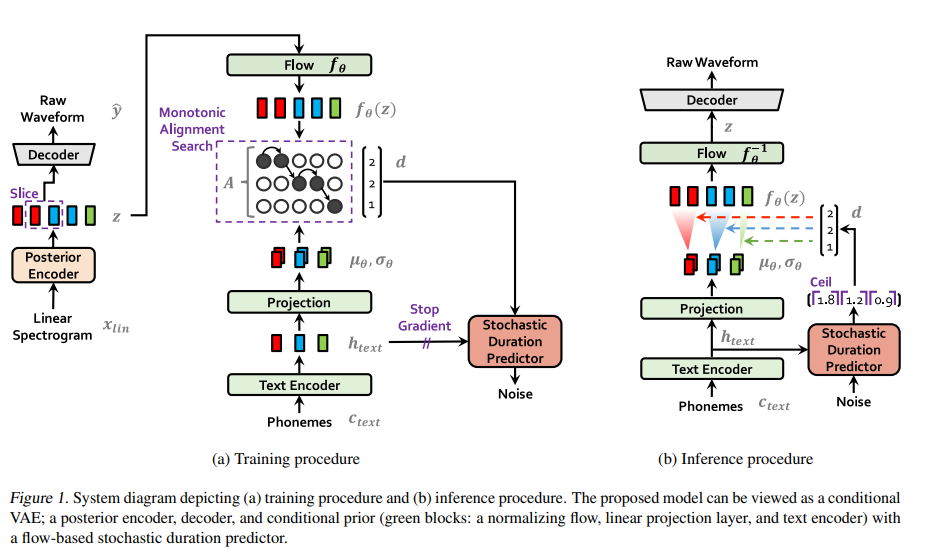
- Posterior Encoder
저자들은 posterior encoder로 WaveGlow와 Glow-TTS에서 사용되는 non-causal WaveNet residual block을 사용했습니다. WaveNet의 residual block은 gated activation unit과 skip connection이 있는 dilated convoluation layer로 구성됩니다.
block 위에 존재하는 linear projection은 normal posterior distribution의 평균과 분산을 구해줍니다. multi-speaker의 경우, residual block에 speaker embedding을 더하기 위해 global conditioning을 사용합니다.
- Prior Encoder
prior encoder는 input phoneme c_text를 처리하는 text encoder와 prior distribution의 flexibility를 향상시켜주는 normalizing flow f_θ로 구성됩니다. text encoder는 absolute positional encoding 대신 relative positional representation을 사용하는 transformer encoder를 사용합니다. text encoder와 그 위에 존재하는 linear projection layer를 이용해 c_text로부터 h_text라는 hidden represntation을 얻을 수 있습니다. 여기서 linear projection layer는 prior distribution의 mean과 variance를 생성해주고, 이를 통해 prior distribution을 construct 할 수 있습니다. WaveNet residual block stack으로 구성된 affine coulping layer stack으로 normalizing flow를 구현했습니다. 단순화를 위해 저자들은 Jacobian determinant가 1인 volume-preserving transformation을 가지는 normalizing flow를 design했습니다. multi-speaker setting의 경우, 저자들은 global conditioning을 통해 normalizing flow에 있는 residual block에 speaker embedding을 더해줍니다.
- Decoder
저자들의 decoder는 무조건 HiFi-GAN v1 generator여야 한다고 합니다. 이는 transposed convolution stack으로 구성되며, 각각 뒤에 receptive field fusion module (MRF)가 붙습니다. MFR의 output은 residual block의 output의 합인데, 여기서 residual block들은 다양한 receptive field size를 갖습니다. multi-speaker setting을 위해, 저자들은 speaker embedding을 변환하는 linear layer를 추가하고 이 값을 input latent variable z에 더합니다.
- Discriminator
HiFi-GAN에서 제안하는 multi-period discriminator architecture를 사용합니다. multi-period discriminator는 Markovian window-based sub-discriminator의 mixture입니다. 각 sub-discriminator는 input waveform의 다양한 주기적 pattern을 연산합니다.
- Stochastic Duration Predictor
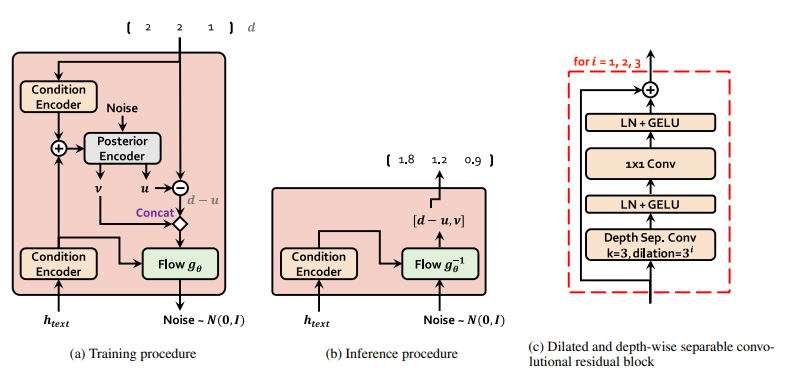
stochastic duration predictor는 conditional input h_text로부터 phoneme duration 분포를 추정합니다. stochastic duration predictor의 효과적인 parameterization을 위해, 저자들은 dilated and depth-separable convolutional layer를 가진 residual block을 stack합니다. 그리고 저자들은 monotonic rational quadratic spline을 사용하는 invertible nonlinear transformation 형태인 neural spline flow를 coupling layer에 사용합니다. nueral spline flow는 일반적으로 사용되는 affine coupling layer와 비교했을 때 비슷한 수의 parameter로 transformation의 표현력을 향상시켜줍니다. multi-speaker setting에서는 저자들이 speaker embedidng을 transform하는 linear layer를 추가한 다음 이를 input h_text에 더했습니다.
Experiments
Datasets
LJ Speech dataset와 VCTK를 사용했습니다. LJ Speech는 single speaker가 녹음한 13,100 short audio clip으로 구성되며 총 length는 약 24시간 입니다. VCTK dataset은 109명의 native English speaker가 다양한 accent로 녹음했으며 총 44,000개의 short audio clip으로 구성됩니다. 총 약 44시간 길이입니다. 그리고 International Phonetic Alphabet (IPA) sequence를 사용하여 phoneme을 구했습니다.
Results
Speech Synthesis Quality
저자들은 MOS test를 진행해 quality를 평가했습니다.

자연스러움을 1~5 scale로 평가했습니다. 결과는 위와 같습니다. VITS(DDP)는 Glow-TTS에서 사용되는 deterministic duration predictor를 사용한 VITS입니다. stochastic duration predictor를 사용한 VITS가 가장 좋은 결과를 보입니다. 즉 stochastic duration predictor가 더 실제 같은 phoneme duration을 생성한다는 것을 의미합니다. 그리고 저자들의 end-to-end training method가 다른 TTS model들과 비슷한 duration predictor를 사용하더라도 더 좋은 sample을 만들 수 있는 효과적인 방법임을 의미합니다.
Generalization to Multi-Speaker Text-to-Speech
저자들의 model은 다양한 speech characteristic을 학습하고 표현할 수 있음을 입증하기 위해, multi-speaker speech synthesis에서 저자들의 model을 Tacotron 2, Glow-TTS, HiFi-GAN과 비교합니다. 저자들은 VCTK dataset에서 model을 학습했습니다. speaker embedding을 추가하는 방식으로 multi-speaker를 구현했습니다. 실험 결과는 다음과 같습니다.
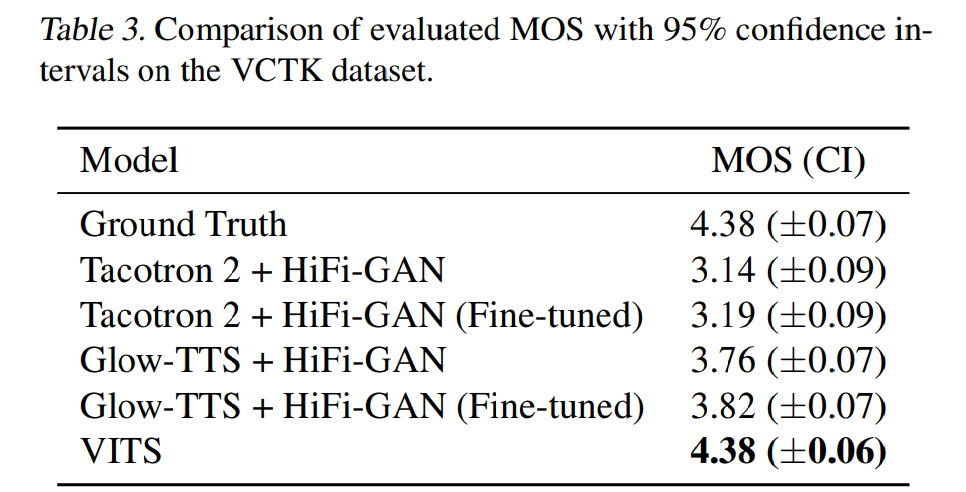
위 결과와 같이 저자들의 model이 가장 높은 MOS를 보였습니다. 저자들의 model이 end-to-end 방식으로 다양한 speech characteristic을 배우고 표현할 수 있음을 입증하는 모습입니다.
Speech Variation
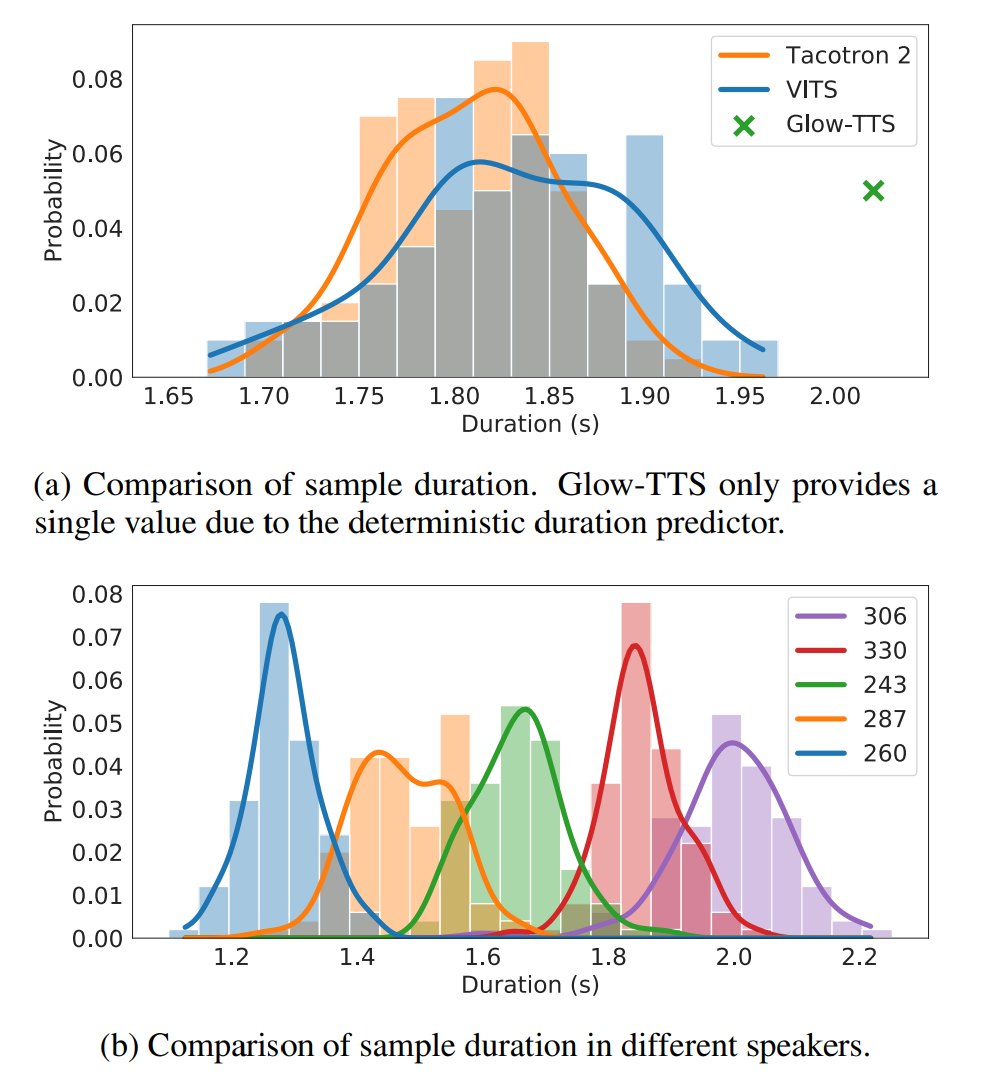
stochastic duration predictor가 얼마나 다양한 길이의 speech를 생성하는지 그리고 합성된 sample들이 얼마나 다양한 speech characteristic를 가지고 있는지 위와 같이 보였습니다.
Conclusion
이 연구에서 저자들은 parallel TTSsystem인 VITS를 제안했으며, 이 model은 end-to-end 방식으로 학습하고 생성할 수 있습니다. 그리고 stochastic duration predictor를 제안했는데, 이는 speech의 다양한 rhytm을 표현할 수 있습니다. 실험 결과는 text로부터 자연스러운 waveform을 바로 합성할 수 있습니다. 실험을 통해 저자들의 method가 two-stage TTS system보다 더 좋은 성능을 보이고 ground-truth와 매우 유사한 성능을 보인다는 것을 증명했습니다.



