https://arxiv.org/abs/2206.06488
Multimodal Learning with Transformers: A Survey
Transformer is a promising neural network learner, and has achieved great success in various machine learning tasks. Thanks to the recent prevalence of multimodal applications and big data, Transformer-based multimodal learning has become a hot topic in AI
arxiv.org
해당 논문을 보고 작성했습니다.
Multimodal Learning (MML)
최근 몇 년 사이에 MML 연구는 주목을 받았습니다. 1980년에는 audio-visual speech recognition에 대한 초기 multimodal application 연구가 진행되었었습니다. MML의 key는 human society입니다. 사람들이 살고 있는 세상이 multimodal environment입니다. 즉 우리가 보고 행동하는 것이 multimodal입니다. 예를 들어 ai navigation robot은 real-world environment를 인지하기 위해선 multimodal sensor (e.g., camera, LiDAR, radar, ... )가 필요합니다. 그리고 인간의 행동, 감정, 사건, 동작, 유머 등 역시 multimodal이며, 다양한 인간 중심의 MML task들이 널리 연구되어 왔으며 여기엔 multimodal 감정 인지, multimodal event representation 등이 있습니다.
최근 몇 년동안 internet이 발전하고 intelligent device가 널리 사용됨에 따라 점점 더 많은 multimodal data가 internet을 통해 전송되고 있으며, multimodal application scenario가 증가하고 있습니다. 현대에는 다양한 multimodal application을 볼 수 있으며 대표적으로 상업적 service (전자상 거래, vision and language navigation (VLN), ... )가 있습니다.
deep learning 시대에 들어서면서 deep neural network는 MML의 발전을 상당히 촉진시켰고 transformer는 상당히 경쟁력 있는 architecture로 사용되고 있습니다. 특히, 최근 large language model들의 성공과 그들의 multimodal로의 파생된 성공을 통해 transformer가 multimodal model에서 가진 잠재력을 입중하고 있습니다.
Transformer: a Brief History and Milestones
Vanilla Transformer는 self-attention mechanism을 활용하는데, 다양한 NLP task에서 사용되는 것을 목적으로 처음 개발되었으며 이는 sequence-specific representation을 학습하는 획기적인 model이었습니다. Vanilla Transformer의 큰 성공을 따라 다양한 파생된 model들이 등장했습니다 (e.g., BERT, BART, GPT, Longformer, Tranformer-XL, ...).
최근 Transformer는 NLP domain에서 지배적인 position에 위치하고 있으며, 연구자들은 transformer을 다른 modality에 적용하는 시도를 하고 있습니다. visual domain에 시도를 했었는데, CNN feature와 standard Transformer encoder를 결합한 일반적인 pipeline이었습니다. raw image를 low resolution으로 resize하고 1D sequence로 reshape하는 전처리를 통해 BERT 방식 pretraining을 수행하는 방식으로 연구가 진행되었습니다.
Vision Transformer (ViT)는 Transformer의 encoder를 image에 사용함으로써 end-to-end solution을 제공합니다. ViT와 ViT의 변형들은 다양한 computer vision task에서 사용되었으며, low-level task, recognition, detection 등 다양한 task에 사용되었습니다. 게다가 최근에 알려진 몇몇 연구들은 ViT에 대한 이론적인 이해를 더욱 제공해 주었습니다.
Transformer의 큰 성공에 영감을 받아 VideoBERT라는 Transformer를 multimodal task에 적용한 첫 연구가 등장했습니다. VideoBERT는 multimodal context에서의 Transformer의 잠재력을 입증하였습니다. VideoBERT를 따라 많은 Transformer 기반 multimodal pretraining model들(e.g., ViLBERT, LXMERT, VisualBERT, Oscar,...)이 machine learning분야에서 점점 더 많은 관심을 받고 있습니다.
2021년에 CLIP이 제안되었습니다. classification task에서 retrieval task로 변환하기 위해 pretrain된 multimodal model을 사용하여 zero-shot recognition을 다룰 수 있는 새로운 milestone입니다. CLIP은 large-scale multimodal pretraining을 사용하여 zero-shot learning을 가능하게 한 성공적인 사례입니다. 최근에는 CLIP의 idea를 사용하는 연구들이 등장하고 있습니다. 예를 들어 ALIGN, CLIP-TD, ALBEF, CoCa 등이 있습니다.
Vanilla Transformer
vanilla Transformer는 encoder-decoder 구조를 갖고 있으며 Transformer 기반 연구들의 시작점입니다. Transformer는 tokenized input을 받아서 처리합니다. encoder와 decoder 모두 Transformer layer/block을 stack하여 구현됩니다. 아래 그림과 같은 구조입니다.

각 block은 2개의 sub-layer (i.e., multi-head self-attention (MHSA) layer와 position-wise fully-connected feed-forward network (FFN))으로 구성됩니다. gradient의 back propagation을 위해 MHSA와 FFN은 residual connection을 사용합니다. 그 뒤에는 normalization layer가 붙습니다. 그래서 input tensor Z가 주어졌을 때 MHSA나 FFN sub-layer의 output을 다음과 같이 정의할 수 있습니다.

여기서 N은 normalization을 의미합니다.
여기에는 post-normalization과 pre-normalization에 대한 해결하지 못한 중요한 문제가 남아있습니다. original vanilla Transformer는 각 MHSA와 FFN sub-layer에서 post-normalization을 사용합니다. 하지만 수학적 관점에서 이를 생각해 보면, pre-normalization이 더 의미가 있습니다. matrix의 기초 이론과 유사하게 normalization은 projection 이전에 수행되는 것이 더 알맞습니다.
Input Tokenization
- Tokenization
Vanilla Transformer는 sequence-to-sequence model이며 machine translation을 목적으로 개발되었습니다. 그래서 vocabulary sequence를 input으로 받습니다. original self-attention은 임의의 input을 fully-connected graph로 model할 수 있으며, modality와 관계없이 수행할 수 있습니다. 구체적으로 Vanilla Transformer와 variant Transformer 모두 tokenized sequence를 input으로 받으며, 각 token을 graph의 node로 볼 수 있습니다.
- Special/Customized Tokens
Transformer에서 다양한 special/customized token들은 token sequemce에서 의미론적으로 place-holder로 정의될 수 있습니다. 예를 들어 mask token '[mask]'의 경우 해당 위치는 mask되어 있다는 것을 의미합니다. special token들은 uni-modal이든 multimodal이든 상관없이 사용될 수 있습니다.
- Position Embedding
position embedding은 position information을 얻기 위해 token embedding에 더해집니다. Vanilla Transformer는 position embedding을 생성하기 위해 sine, cosine function을 사용합니다. 다양한 position embedding들이 개발되었습니다.
- Discussion
input tokenization에 대한 주요 이점은 다음과 같습니다.
- Tokenization은 다른 modality여서 발생되는 constraint를 minmize함으로써 geometrically topological 관점에서 더 일반적인 접근 방식을 제공해 줍니다. 모든 modality는 modelling에 내재된 constraint가 존재합니다. 예를 들어 sequence는 RNN이 잘 맞는 순차적 구조를 가지고 있으며, 사진은 CNN이 잘 맞는 aligned grid matrice를 갖습니다. Tokenization은 다양한 modality를 불규칙한 희소 구조를 통해 (각 token들끼리 서로 상호작용할 수 있도록 설계되어 input data의 구조가 불규칙하고 희소성이 있어도 문제없이 처리할 수 있음) 보편적으로 처리할 수 있도록 도와줍니다. 따라서 Vanilla Transformer가 concatenate하거나 weighted sum을 하는 등 multimodal input을 flexible하게 encode할 수 있게 됩니다. 즉 multimodal에 맞춘 특별한 수정 없이도 사용 가능함을 의미합니다.
- Tokenization은 concatenation/stack, weighted summation과 같은 방법을 통해 input information을 조직하는 더 flexible한 방식을 제공합니다. Vanilla Transformer는 position embedding을 token embedding에 추가함으로써 temporal information을 주입합니다. 예를 들어 free-hand sketch drawing을 model할 때 Transformer를 사용하면, 각 input token은 다양한 drawing stroke pattern을 통합할 수 있습니다. 예를 들어 stroke coordinate, stroke ordering, pen state 등 정보를 통합할 수 있습니다.
- Tokenization은 task-specific customized token과 통합할 수 있습니다. 예를 들어 Masked language modelling task에서 [MASK]라는 token을 사용하면 됩니다.
position embedding을 Transformer가 어떻게 이해하는지는 open problem입니다. feature space의 좌표계 축으로 여길 수 있습니다. 즉 좌표계 축들은 temporal information이나 spatial information을 Transformer에 제공합니다. cloud point나 sketch drawing stroke의 경우, token element는 이미 좌표이므로 position embedding은 필수가 아닌 선택이 됩니다. 그리고 position embedding을 일반적으로 추가적인 information으로 볼 수 있습니다. 즉 수학적인 관점에서 봤을 때 position embedding의 세부 사항과 같은 모든 종류의 추가적인 정보를 더할 수 있습니다. Transformer의 position information에 대한 포괄적인 연구를 진행한 논문도 있습니다. sentence structure (sequential)과 general graph structures (sparse, arbirary, irregular) 둘 다 position embedding이 Transformer가 구조에 대해 학습하거나 encoding하는 데 도움이 됩니다. self-attention의 수학적인 관점에서 봤을 때, position embedding이 없다면 attention는 단어나 text의 position 또는 graph에서의 node의 위치를 변화시키지 않습니다. self-attention mechanism에서 position embedding이 없다면, 각 token의 similarity는 구해지지만 위치 정보는 존재하지 않게 됩니다. 위치 정보가 존재하지 않게 된다면 input의 순서가 달라질 수도 있으며 구조를 무시하게 될 수도 있습니다. 그렇기 때문에 position embedidng이 Transformer에는 거의 필수적입니다.
- Self-Attention and Multi-Head Self-Attention
Vanilla Transformer의 core component는 Self-attention (SA) operation입니다. 이는 "scaled dot-product attention"으로 불리기도 합니다. X = [x_1, ... ,x_N] ∈ R^(Nxd)를 N개의 element/token으로 구성된 input sequence라 하겠습니다. optional preprocessing으로 position embedding을 point-wise summation 또는 concatenation할 수 있습니다.
self-attention (SA)는 preprocessing 후에, embedding z를 3개 projection matrice에 적용해 embedding Q (query), K (Key), V (Value)를 만들어냅니다.

self-attention의 output은 아래와 같이 정의됩니다.

input sequence가 주어졌을 때, self-attention은 각 element가 다른 모든 element에 attend할 수 있도록 만들어주며, 결과적으로 self-attention이 input을 fully-connected graph로 encode합니다. Vanilla Transformer의 encoder는 fullyconnected GNN encoder로 여길 수 있으며, Transformer family는 Non-Local Network와 유사하게 global 인식을 위한 non-local ability를 갖고 있습니다.
Masked Self-Attention (MSA)
Transformer의 decoder가 contextual dependence를 학습하는 데 도움을 주기 위해선 self-attention을 수정할 필요가 있습니다.
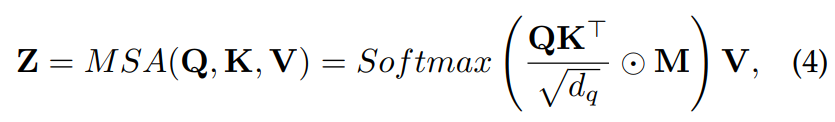
위 식에서 M은 masking matrix입니다. 예를 들어 GPT의 경우 각 token이 과거 token만 볼 수 있도록 하기 위해 upper-triangle mask를 사용하여 미래 token은 attention하지 않도록 만듭니다. Masking은 encoder와 decoder 모두에 사용할 수 있으며 0-1 hard mask, soft mask 등 상황에 맞춰 사용할 수 있습니다.
Multi-Head Self-Attention (MHSA)
multiple self-attention sub-layer는 병렬적으로 stack될 수 있으며 concatenated output을 projection matrix W로 fuse 하여 Multi-Head Self-Attention을 수행할 수 있습니다.
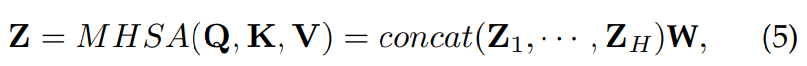
각 head Z_h = SA(Q_h, K_h, V_h)이고 W는 linear projection matrix입니다. MHSA의 idea는 ensemble입니다. MHSA는 model이 multiple representation sub-space로부터 정보를 동시에 attend할 수 있도록 도와줍니다.
- Feed-Forward Network
multi-head attention sub-layer의 output은 position-wise Feed-Forward Network (FFN)으로 feed됩니다. 예를 들어 two-layer FFN의 경우 다음과 같이 정의할 수 있습니다.

여기서 W_1, b_1, W_2, b_2는 두 linear transformation의 weight와 bias입니다. σ는 non-linear activation을 의미합니다. 몇몇 Transformer 논문들은 FFN을 Multi-Layer Perceptron이라 부르기도 합니다.
Vision Transformer
Vision Transformer (ViT)는 image-specific input pipeline을 가지고 있으며, input image는 고정된 크기 (e.g., 16x16, 32x32) patch로 split되어야만 합니다. linearly embedded layer를 거친 후 position embedding을 더한 다음 모든 patch-wise sequence는 standard Transformer encoder에 의해 encoding됩니다. image X ∈ R^(HxWxC)가 주어졌을 때, ViT는 X를 flattened 2D patch로 reshape하여 사용합니다. classificaiton을 수행할 때, 일반적인 방법은 추가 학습 가능한 embedding "classification token" [CLASS]를 embedded patch sequence 앞에 추가하는 것입니다.

여기서 W는 projection을 의미합니다.
Multimodal Transformers
최근에 다양한 multimodal task에서 Transformer을 사용하는 연구들이 많이 등장했으며, discriminative task와 generative task 모두에서 좋은 성능을 보여주고 있습니다.
Multimodal Input
Transformer family는 일반적인 graph neural network type으로 공식화할 수 있는 architecture를 사용합니다. 구체적으로 self-attention은 global (non-local) pattern에 attend함으로써 각 input을 fully connected graph로 처리할 수 있습니다. 그래서 이러한 본질적인 특성은 Transformer가 모든 token의 embedding을 graph의 node로 처리함으로써 다양한 modality에서 호환되는 modality에 무관한 pipeline에서 동작할 수 있도록 도와줍니다.
- Tokenization and Embedding Processing
임의의 modality에서 input이 주어졌을 때, 사용자는 2가지 main step을 거쳐야 합니다. input을 tokenize한 다음 token을 표현하는 embedding space를 선택해야 합니다. 이 과정을 거친 후에 data를 Transformer에 feed합니다. 실제로 input을 tokenize하고 token에 대한 embedding을 선택하는 것 둘 다 매우 중요하지만, 많은 대안이 있어 매우 유연합니다. 예를 들어 image가 주어졌을 때 tokenizing하고 embedding하는 것의 solution은 unique하지 않습니다. 사용자는 다양한 수준의 세분화에서 tokenization을 선택하고 design할 수 있습니다. 예를 들어, object detector로부터 얻은 ROI와 CNN feature를 token과 token embedding으로 사용하거나, patch와 linear projection을 token과 token embedding으로 사용할 수도 있습니다. 또는 object detector와 graph generator를 통해 얻은 graph node와 GNN feature를 token과 token embedding으로 사용할 수도 있습니다. tokenization plan이 주어지면 이후의 embedding 방식도 다양합니다. 예를 들어 video input의 경우, tokenization으로 non-overlapping window를 사용하는 것입니다. non-overlapping window를 token으로 사용하고 다양한 3D CNNs을 거쳐서 embedding을 추출할 수 있습니다. 아래 표는 Transformer에 사용할 수 있는 RGB, video, audio/speech/music, text, graph 등의 multimodal input의 일반적인 사례들을 정리해 놨습니다.
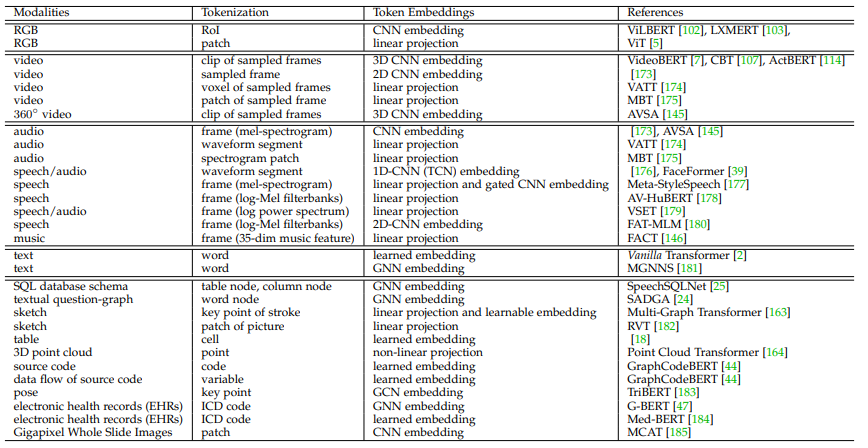
- Discussion
geometric topology 관점에서 볼 때, 위 표에 등장하는 각 modality를 graph로 볼 수 있습니다. RGB image는 pixel space에서 깔끔한 grid graph가 됩니다. video와 audio 모두 clip/segment based graph이며 이는 temporal and semantic pattern을 포함하는 복잡한 space에서 그려집니다. 2D와 3D drawing sketches의 경우, drawing stroke를 key point로 여긴다면 drawing sketch를 sparse graph로 볼 수 있습니다. sketch와 유사하게 human pose 또한 graph의 종류입니다. 3D point cloud는 각 좌표계가 node인 graph입니다. 다른 추상적인 modality들은 graph로 여겨질 수 있습니다.
- Token Embedding Fusion
실제로 Transformer는 각 token position에 여러 embedding을 포함할 수 있습니다. 이는 본질적으로 uni-modal과 multimodal Transformer model 모두 embedding의 early fusion입니다. 가장 흔한 fusion은 multiple embedding을 token-wise summing하는 것입니다. tokenization가 유연한 것과 같이 token embedding fusion 또한 유연하며 uni-modal Transformer와 multimodal Transformer 둘 다에 널리 사용되고 있습니다. token embedding fusion은 multimodal Transformer application에서 중요한 역할을 하는데, 다양한 embedding들이 token-wise operator로 인해 fusion될 수 있기 때문입니다. 예를 들어 VisualBERT와 Unicoder-VL에서 segment embedding은 각 token이 어떤 modality (vision or language)에서 왔는지 나타내기 위해 token-wise로 더했으며, VL-BERT는 language token embedding과 full image visual feature embedding을 token-wise summation을 진행하여 global visual context를 linguistic domain에 inject했었습니다. ImageBERT의 경우 5가지 embedding을 fusion했었습니다(image embedding, position embedding, linguistic embedding, segment embedding, sequence position embedding).
- Self-Attention Variation in Multimodal Context
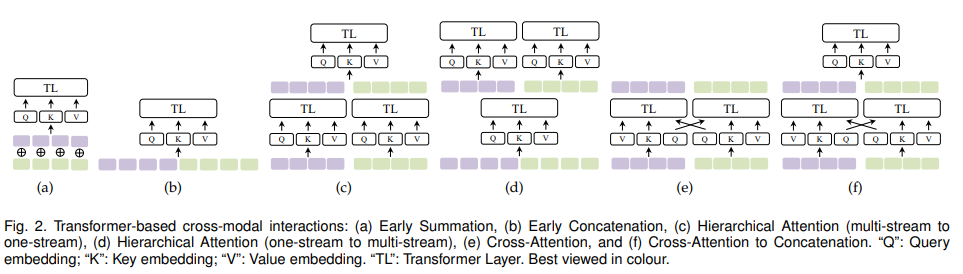
Transformer에 사용되는 self-attention에 대해서 1) early summation (token-wise, weighted), 2) early concatenation, 3) hierarchical attention (multi-stream to one-stream), 4) hierarchical attention (one-stream to multi-stream), 5) cross-attention, 6) cross-attention to concatenation에 대해 알아보겠습니다.
input X_A와 X_B가 두 임의의 modality에서 주어지면, Z_A와 Z_B가 각 input에 대한 token embedding을 의미합니다. Z는 multimodal interaction에 의해 생성된 token embeddidng을 나타냅니다. Tf()는 transformer layer/block 과정을 나타냅니다.
1) Early Summation
early summation은 간단하면서 효과적인 multimodal interaction인데, 이는 multiple modality에서 얻은 token embedding을 각 token 위치에서 weighted sum을 한 후에 Transformer layer에 feed합니다. 식으로 나타내면 다음과 같습니다.

위 식에서 더하기는 element-wise sum을 의미하고 α, β는 weight를 의미합니다. 즉 각 modality에서 얻은 embedding을 transformer에 feed하기 전에 weighted sum을 수행하는 방식이며 연산량이 복잡하지 않다는 장점이 있습니다. 하지만 weight는 직접 정해줘야 한다는 단점이 있습니다. 이 외에도 summing position embedding도 있는데, 이것도 early summation의 종류 중 하나입니다.
2) Early Concatenation
multiple modality에서 얻은 token embedding sequence를 concatenate한 다음 transformer layer로 feed하는 방식입니다.

모든 multimodal token position을 하나의 sequence로 볼 수 있기 때문에, 각 modality의 position은 다른 modality의 context를 condition으로 하여 encode될 수 있습니다. VideoBERTY는 video와 text를 early concatenation 방식으로 fuse하는 transformer model입니다. 하지만 concatenation을 한 후에 sequence가 더 길어지기 때문에 연산량이 증가된다는 단점이 있습니다.
3) Hierarchical Attention (multi-stream to one-stream)
Transformer layer는 cross-modal interaction을 attend하기 위해 계층적으로 combine될 수 있습니다. 보통 multimodal input들을 독립적으로 Transformer stream을 이용해 encode한 다음 output을 concatenate하여 또 다른 Transformer에 넣어주는 방식입니다.

식으로 보면 위와 같습니다. 이러한 hierarchical attention은 late interaction/fusion을 구현한 모습이며, early concatenation의 특수한 경우로 볼 수 있습니다.
4) Hierarchical Attention (one-stream to multi-stream)
InterBERT에서 concatenated multimodal input을 shared single-stream Transformer을 이용해 encode한 다음 두 개의 별도 transformer에 적용합니다. 식으로 표현하면 다음과 같습니다.

cross modal interaction을 얻으면서 각 modal의 representation의 독립성은 보존시켜 주는 형태입니다.
5) Cross-Attention
two-stream Transformer의 경우, Q(Query) embedding을 cross stream 방식으로 교환/swap 하면 cross-modal interaction을 인식할 수 있습니다. cross-attetion 또는 co-attention이라고 불리며 VilBERT에서 처음 등장했습니다. 식으로 나타내면 다음과 같습니다.
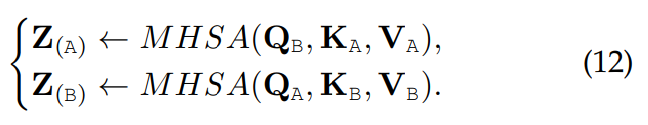
Cross-attention은 다른 modality에 condition되어 각 modality를 attend할 수 있으며 높은 연산량을 필요로 하지 않습니다. 하지만 각 modality별로 고려하면 이 방식은 cross-modal attention을 전역적으로 수행할 수 없으며 전체 문맥을 잃게 될 수 있습니다.
6) Cross-attention to Concatenation
cross attention의 two stream은 추가적으로 concatenate되어 다른 Transformer를 이용해 global context를 model할 수 있습니다. 식으로 나타내면 다음과 같습니다.
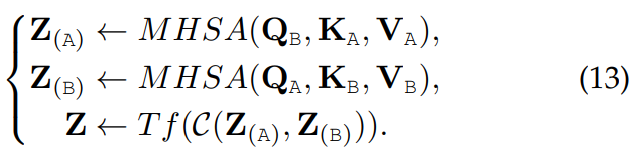
이러한 계층적 cross-modal interaction은 널리 연구되고 cross-attention의 단점을 완화하기 위해 연구되고 있습니다.
- Discussion
앞서 말한 multi-modal interaction에 사용되는 self-attention variation들은 일반적인 방식들이므로, 유동적으로 multi-granular task에 적용될 수 있습니다. 구체적으로 이러한 interaction들은 유동적으로 결합되거나 중첩될 수 있습니다. 나아가 3개 이상의 modality에 대한 확장도 진행되고 있습니다. TriBERT의 경우 tri-modal cross-attention (co-attention)이 있습니다. 이는 vision, pose, audio라는 세 가지 modality에 대한 연구이며, 각 modality에서 주어진 Query embedding과 그에 대응하는 Key, Value embedding을 concate합니다. concatenation을 통해 세가지 modality를 사용할 수 있게 되었습니다.



