https://arxiv.org/abs/1911.09338
Voice-Face Cross-modal Matching and Retrieval: A Benchmark
Cross-modal associations between voice and face from a person can be learnt algorithmically, which can benefit a lot of applications. The problem can be defined as voice-face matching and retrieval tasks. Much research attention has been paid on these task
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
voice와 face 사이의 cross-modal association은 algorithm을 통해 학습할 수 있으며, 많은 application에서 사용될 수 있습니다. 이 문제는 voice-face matching하는 것과 retrieval task로 정의할 수 있습니다. 많은 연구들이 이 task를 해결하기 위해 진행되고 있지만, 여전히 초기 단계입니다. random tuple mininig 기반 test 방식은 낮은 test 신뢰성을 보이는 경향이 있습니다. model의 일반화 성능은 small scale dataset으로는 평가할 수 없습니다. 다양한 task에 대한 performance metric도 드뭅니다. 그렇기 때문에 이 task에 대한 benchmark가 정의되어야만 합니다. 이 논문에서, voice-face matching 및 retrieval을 위한 종합적인 연구를 바탕으로 하는 framework를 제안합니다. 다양한 성능 지표를 통해 최신 기술들과 유사항 성능을 보여주어 larget scale datset에서도 높은 test 신뢰도를 보입니다. 그리고 앞으로 등장할 연구의 baseline으로 사용될 수 있습니다. 이 framework는 voice 기반 L2-norm constrained metric space를 제안하고 cross-modal embedding은 CNN기반 network이며 triplet loss를 사용하여 학습됩니다.
Introduction
생물학 및 신경학 분야의 연구들에서 사람의 생김새는 목소리와 연관있다는 것이 증명되었습니다. 개인의 얼굴 특성과 voice controlling 구조는 호르몬과 유전적 정보에 의해 영향을 받습니다. 그리고 인간은 이러한 연관성을 인지할 능력을 가지고 있습니다. 예를 들어 전화를 통해 목소리를 들었을 때, 성별을 예측할 수 있으며 대략적인 나이도 예측할 수 있습니다. 목소리가 없는 TV show를 볼 때, 주인공의 얼굴 움직임을 관찰하여 대략적인 목소리를 상상할 수도 있습니다.
최근 몇 년동안, 대부분의 연구들은 voice-face cross modal learning task에 focus를 맞추고 있으며, voice-face association 인식의 가능성을 보여주었습니다. 일반적으로 voice-face matching task와 voice-face retrieval task로 구성되며 아래와 같습니다.
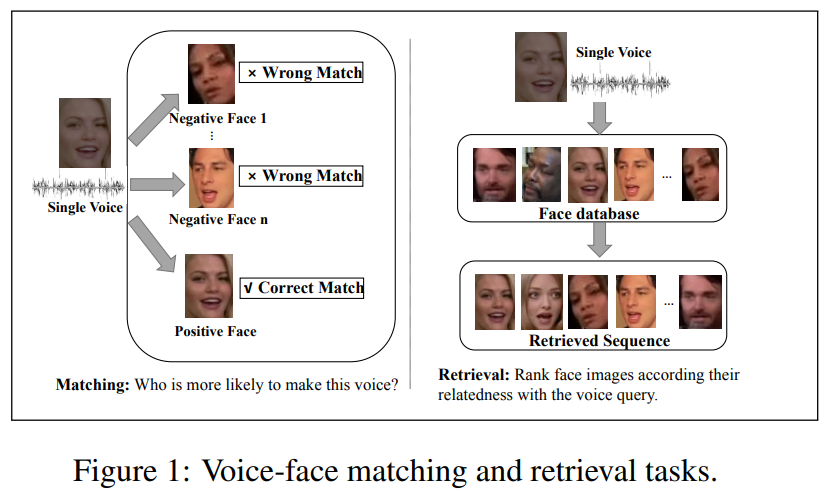
voice audio와 face set이 주어지면, voice-face matching은 어떤 face가 해당 voice를 말했는지 기계가 voice audio를 듣고 판단합니다. Voice-face retrieval은 voice recording query로부터 추정된 matching 순서대로 정렬된 face sequence를 제시합니다.
다양한 연구가 있는데, 그중 DIMNet은 성별, 국적과 같이 face과 voice의 공분산과의 관계를 활용하여 얼굴과 음성에 대한 공통 representation을 학습합니다. DIMNet은 1:2 matching에서 84.12% 정확도를 보이며 이는 인간 수준을 넘긴 결과입니다.
하지만 이 분야 연구들은 여전히 초기 단계에 있습니다. 이전 연구들에서 사용되었던 dataset은 항상 매우 작았으며, model의 일반화 성능을 평가하기엔 충분하지 않았습니다. 그리고 random tumple mining을 기반으로 하는 전통적인 test 방식은 낮은 신뢰도를 보이는 경향이 있습니다. 이 분야의 benchmark가 필요한 상황입니다. 이 논문에서 voice-face cross-modal matching & retireval framework를 제안합니다. 저자들의 cross-modal embedding은 L2-norm 제약이 있는 voice anchored metric space에서 triplet loss를 사용하는 CNN-based network입니다.
Voice-Face Matching and Retrieval (VFMR)
Dataset
이전 연구들은 Vox-VGG-1이라는 1251명 English speaker로 구성된 dataset을 사용하는데, 이는 VoxCeleb1 dataset과 VggFace1을 결합하여 구성된 dataset입니다. cross-modal learning의 일반화 성능을 평가하기 위해선 더 많은 evaluation datset이 필요합니다. 이 논문에서는 VoxVGG-2 dataset을 사용합니다. 이 dataset은 Vox-Celeb2와 VGGFace2의 교집합들로 구성된 dataset이며 총 5994명 speaker를 포함합니다.
Learning Voice Anchored Embedding in L2-constrained Metric Space
voice와 face의 representation을 학습하는 것은 voice-face matching & retrieval의 기초입니다. cross-modal learning을 위해 존재하는 embedding learning은 classification based method와 pair-wise loss based method로 나눌 수 있습니다.

multi-stream CNN architecture로 구한 feature embedding은 concatenate된 다음 multiple softmax classifier로 feed되어 1:n matching task를 수행합니다. pair-wise los based method의 경우, vector의 pair 또는 vector의 triple은 voice network와 face network를 통해 구해지며, contrastive loss 또는 triplet loss를 사용하여 embedding을 학습시킵니다. pair-wise loss based method는 positive pair embedding들은 가깝게 만들고 negative pair embedding들은 멀게 만드는 것이 목표입니다. classification based method는 embedding의 class를 잘 구분하는 것이 목표입니다. classification based method와 비교했을 때 pair-wise loss based method는 구분하기 어려운 example들도 잘 구분할 수 있습니다. classification based method에 성별 정보와 같은 추가적인 supervised information을 제공할 수도 있습니다. 이 논문에서는 새로운 voice anchored embedding learning method를 제안하는데, 이는 l2-constrained metric space에서 동작하며 pair-wise loss based method입니다. 제안된 method는 기존의 method의 성능을 크게 향상시켰습니다.
- Network Structure
LResNet50은 face recognition task에서 좋은 성능을 보이고 NetVLAD를 사용하는 Thin ResNet34는 speaker recognition task에서 좋은 성능을 보입니다. 이 두 network는 다음과 같습니다.

여기서 LResNet50으로 face feature를 추출했으며, Thin ResNet34로 voice feature extraction을 진행했습니다. embedding network의 input은 triplet set입니다. <v_i, f_i, f_j>가 있을 때, v_i와 f_i는 동일한 identity에서 구해지는 input이고, v_i와 f_j는 서로 다른 identity에서 구해지는 input입니다. voice로부터 feature를 추출하는 function은 Feature_v(v)이고 face로부터 feature를 추출하는 function은 Feature_f(f)입니다. full connected layer는 embedding vector emb_v(v) = s x ||W_v x Feature_v(v) + B_v||, emb_f(f) = s x ||W_f x Feature_f(f) + B_f||을 구하기 위해 사용되며, 여기서 L2 constraint와 scale variable s를 fully connected layer의 output에 적용한 형태입니다.
- Triplet loss upon l2-constrained metric space
이 논문에서 Triplet loss를 사용하여 embedding을 학습합니다. Euclidean space에서 동일한 사람으로부터 구해지는 embedding vector들은 학습이 된 후에는 가까워지게 됩니다. 수십억 개의 input triplet이 존재하기 때문에, 거대한 Euclidean space에서 직접 training하여 만족스러운 결과를 얻는 것은 어렵습니다.
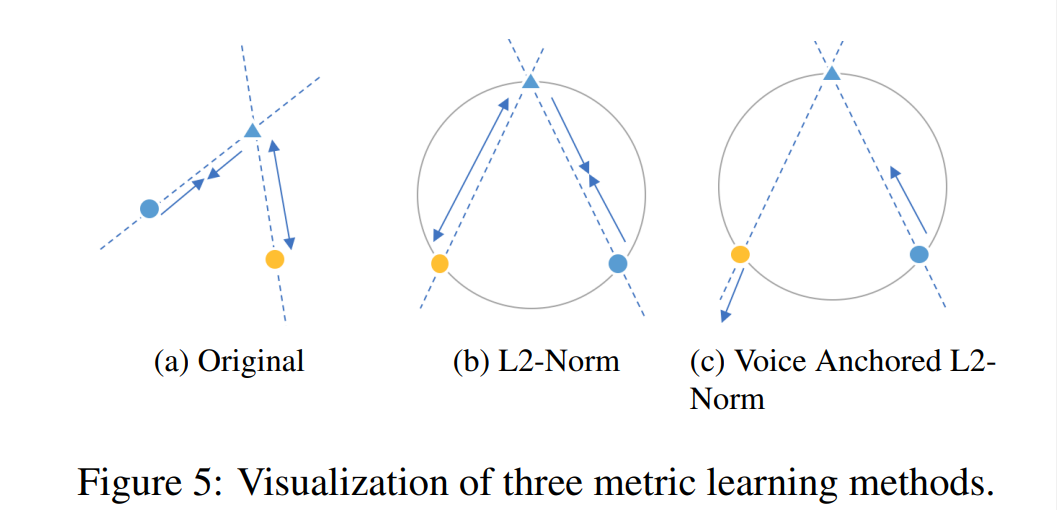
그래서 이 논문에서는 2가지 strategy를 사용합니다. 먼저 L2 normalization을 사용하여 embedding vector가 spherical space에 존재하도록 제약합니다(위 그림 (b)). 그다음으로 voice anchored embedding learning을 하는 것입니다. pre-trained voice embedding network를 freeze하고, voice로부터 구해지는 feature vector들을 anchor로 사용하여 positive pair를 가깝게 만들고 negative pair는 멀게 만듭니다(위 그림 (c)). Voice anchor L2 norm을 사용했을 때 학습이 더 빠르고 잘 동작합니다. d(x)를 Euclidean distance라고 할 때, loss function은 다음과 같이 정의됩니다.

여기서 m은 positive pair와 negative pair 사이의 distance를 조절하는 margin입니다.
Effect of voice anchored embedding learninig
pre-trained voice embedding network를 freeze 함으로써, anchored embedding learning이 수행됩니다. face embedding network를 freezing하는 것은 성능 저하를 유발하며, voice embedding network를 freezing 했을 때는 약간 성능이 향상됩니다. 사람의 목소리는 인간 얼굴의 일부 local feature에 연관이 있습니다. 비슷한 얼굴이라고 무조건 비슷한 목소리를 생성할 필요는 없습니다. 그렇기 때문에 voice anchored embedding learning은 face anchored embedding learning보다 성능이 좋습니다. voice network를 고정함으로써 학습 효율을 향상시킬 수 있습니다.
저자들은 다양한 실험들을 보였습니다.



