https://arxiv.org/abs/2306.03258
LipVoicer: Generating Speech from Silent Videos Guided by Lip Reading
Lip-to-speech involves generating a natural-sounding speech synchronized with a soundless video of a person talking. Despite recent advances, current methods still cannot produce high-quality speech with high levels of intelligibility for challenging and r
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Lip-to-Speech는 사람이 말하고 있는 soundless video를 가지고 자연스러운 합성된 speech를 생성하는 것을 포함합니다. 최근의 발전에도 불구하고, 현재의 방법들은 LRS3와 같은 도전적이고 현실적인 dataset에서 높은 수준의 명료성을 가진 high quality speech를 생성하지 못합니다. 이 논문에서 저자들은 LipVoicer라는 text modality도 사용함으로써 도전적이고 대규모 dataset에서도 high quality의 speech를 생성하는 새로운 method를 제안합니다. silent video가 주어졌을 때, 먼저 pre-trained lip-reading network를 사용하여 spoken text를 예측합니다. 그다음 video를 가지고 diffusion model에 condition을 부여하고 pre-trained automatic speech recognition (ASR)을 classifier로 사용하는 classifier-guidance mechanism을 통해 text를 추출하여 사용합니다. LipVoicer는 LRS2와 LRS3 dataset에서 lip-to-speech baseline method들보다 더 뛰어난 모습을 보입니다.
Introduction
lip-to-speech task는 사람이 말하고 있는 soundless video가 주어졌을 때, 정확하고 정밀하게 missing speech를 생성하는 것이 목표입니다. 이러한 task는 예를 들어 speech signal이 background noise 때문에 완전히 가려지는 경우에 필요할 수 있습니다. 이 task는 생성된 음성이 명료성, lip motion과의 synchronization, 자연스러움, 화자의 성별, 나이, 악센트 등과 같은 특성을 만족해야 하기 때문에 어려운 task입니다. Lip-to-Speech의 또 다른 어려움 중 하나는 lip motion의 내재된 모호성입니다. 서로 다른 phoneme들은 동일한 lip movement에서 발생될 수 있습니다. 이러한 모호성을 풀기 위해 video 내에서 lip movement를 더 넓은 contetx에서 분석해야만 합니다.
이 논문에서 저자들은 silent video에서 high-quality speech를 생성하는 새로운 approach인 LipVoicer를 제안합니다. LipVoicer는 inference 할 때 lip-reading model을 사용하여 우리가 생성하기 원하는 speech의 transcription을 추출합니다. 그 다음 video만 condition으로 하는 diffusion model을 학습하여 mel-spectrogram을 생성합니다. inference time에서 생성 과정은 video와 예측된 transcription에 의해 guide됩니다. 결과적으로 저자들의 model은 text modality에 의해 전달되는 information과 diffusion model에 의해 capture되는 speaker의 dynamic characteristic을 성공적으로 결합합니다. 추론된 text를 통합하면 lip motion의 모호성을 상당 부분 해소할 수 있다는 추가적 이점도 있습니다. 마지막으로 저자들은 DiffWave라는 neural vocoder를 사용하여 raw audio를 생성합니다. 이전 몇몇 연구들도 학습할 때 생성 과정에서 text를 guide로 사용했었습니다. 하지만 저자들은 inference할 때 text를 guide로 사용합니다.
저자들이 아는 한, LipVoicer가 lip-to-speech synthesis를 향상시키기 위해 lip-reading으로 text를 추론하여 사용한 첫 method입니다. 추론에서 text modality를 포함하는 것은 lip motion에 일치하는 후보 phoneme을 해독하는 불확실성을 제거할 수 있습니다. 추가적으로 diffusion model이 자언스러운 synced speech만 생성하는 데 focus할 수 있도록 만들어줍니다. LipVoicer에 의해 생성된 speech는 명료하고 video와 잘 sync가 맞으며 자연스럽게 들립니다. 마지막으로 LipVoicer는 실생활 dataset에서도 좋은 성능을 보여줍니다.
Background
Guidance
많은 diffusion model들의 주요 key feature는 conditional generation을 위해 guidance를 사용하는 것입니다. classifier가 있는 경우나 없는 경우 모두, guidance는 conditioning information에 더 충실한 output을 생성할 수 있게 guide 합니다. 예를 들어 text-to-image의 경우, 생성된 image가 prompt text와 일치하도록 강제하는 데 도움이 됩니다.
q(x_t | c)에서 sample을 한다고 가정했을 때, x_t는 현재 iteration에서의 sample이고 c는 context이며, p(c | x_t)는 pre-trained classifier입니다. 이 상태에서 우리의 goal은 x_(t-1)을 생성하는 것입니다. classifier guidance의 idea는 diffusion process가 올바른 context c를 가진 output을 생성할 수 있도록 classifier가 guide를 해주는 것입니다. 구체적으로 diffusion model은 ε_θ(x_t, t)를 return한다면, classifier guidance는 update에 사용되는 noise term을 변경합니다.
classifier-free guidance에서는 두개의 noise prediction을 수행합니다. 하나는 context information에 condition인 ε_θ(x_t, c, t)이고 다른 하나는 ε_θ(x_t, t)입니다. 그래서 ε_θ(x_t, c, t)에서 ε_θ(x_t, t)를 빼는 방식으로 guidance를 제공해 주는 방식입니다. 이를 통해 context c에 해당하는 update direction을 향상시킬 수 있습니다.
LipVoicer
silent talking-face video V가 주어졌을 때, LipVoicer는 speech signal이 주어졌을 때 likelihood가 높은 mel-spectrogram을 생성합니다. main component는 다음 세 가지 입니다.
- V로부터 얻어지는 mel-spectrogram image를 생성하도록 학습되는 mel-spectrogram generator (MelGen)
- silent video로부터 text를 추론하는 pre-trained lip-reading network
- MelGen에 의해 복원된 mel-spectrogram을 lip-reader network가 예측한 text에 고정시키는 ASR system
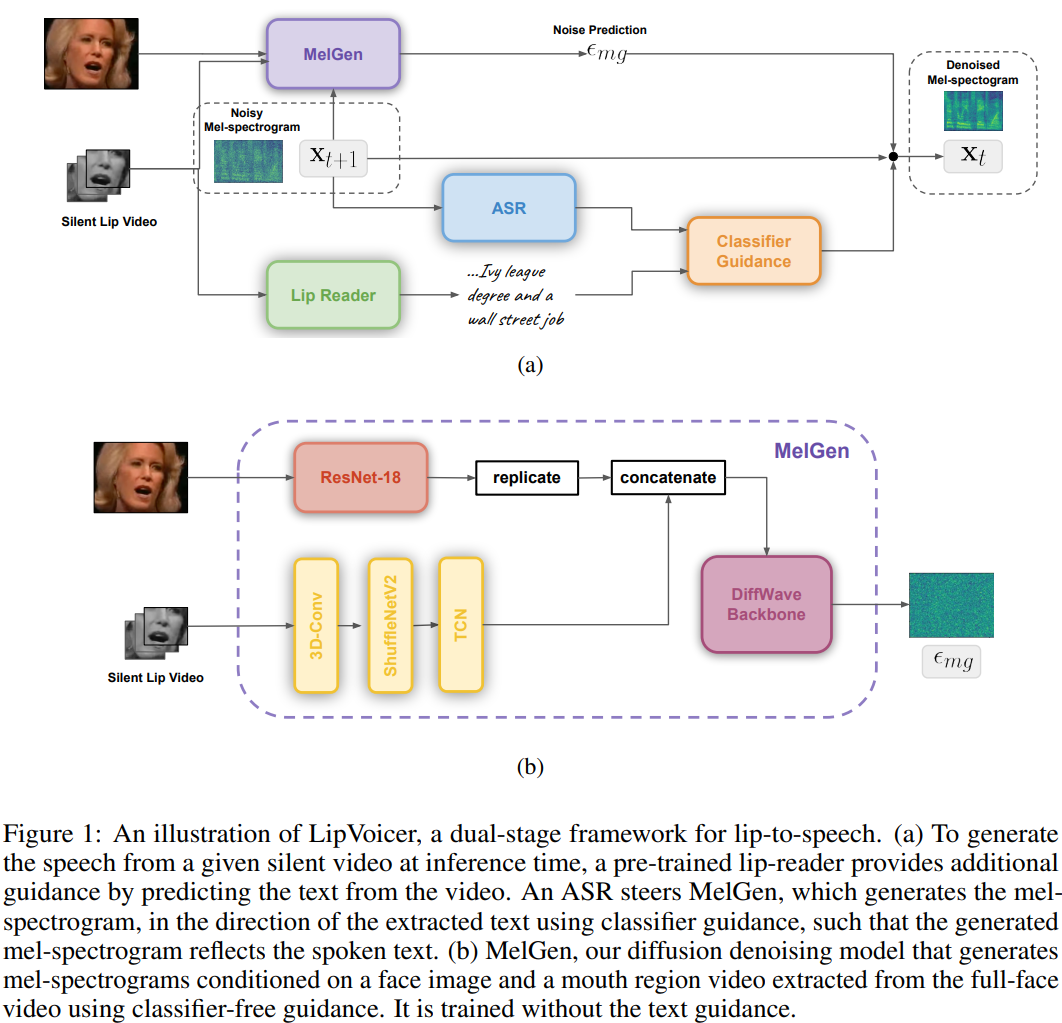
먼저 conditional denoising diffusion probabilistic models (DDPM)인 MelGen을 text modality없이 video V를 condition으로 하여 mel-spectrogram waveform x를 생성하도록 학습합니다. MelGen을 학습할 때 classifier-free guidance를 사용합니다. diffusion basesd TTS framework와 유사하게, 저자들은 MelGen에 DiffWave residual backbone을 사용합니다. V의 representation이 mel-spectrogram을 생성할 때 필요한 모든 information (i.e. content (spoken words) and dynamics (accent, intonation), timing of each part of speech, speaker identity)을 캡슐화하고자 합니다. 하지만 학습을 도와주지 않는 불필요한 정보는 전부 제거하고 불필요한 연산은 줄이고 싶습니다. 이를 위해 V를 입 영역만 crop하여 새로운 video V_L을 만들도록 전처리합니다. 그다음 random하게 single full face image L_F를 선택합니다. V는 content와 dynamic에 연관이 있으며, L_F는 speaker characteristic에 연관이 있습니다.
V_L과 L_F에서 feature를 추출하기 위해, 저자들은 VisualVoice 논문에서 소개한 구조와 비슷한 audio-visual speech separation model 구조를 사용합니다. L_F의 경우, face embedding f ∈ R^(D_f)는 ResNet-18의 마지막 두 layer를 폐기하여 구해집니다. lip video V_L은 lip-reading architecture를 이용해 encode됩니다. lip-reading architecture는 3D convolutional layer, ShuffleNet v2와 temporal convolutional network (TCN)으로 구성되며, 결과적으로 lip video embedding m ∈R^(N x D_M)을 output하며, N은 frame 수를 의미하고 D_m은 channel 수를 의미합니다. face embedding과 lip video embedding을 merge하기 위해, f를 N번 반복한 다음 m에 concatenate합니다. video embedding v ∈ R^(N x D) 일 때, D = D_f + D_M입니다. 그다음 DDPM은 classifier-free mechanism에 맞춰 video embedding v를 condition으로 하거나 condition으로 하지 않는 mel-spectrogram을 생성하도록 학습됩니다.
MelGen이 제약 없는 vocabulary라는 scenario에서도 잘 동작하기 위해서, inference time에 text modality를 추가적인 guidance의 source로 사용합니다. 일반적으로, silent talking-face video에서 발음된 음절은 모호할 수 있으며 결과적으로 일관적이지 않은 reconstructed speech를 생성할 수도 있습니다. 그러므로 최신 lip-reading technique을 활용하고 pre-trained lip reading network가 예측한 text에 생성된 mel-spectrogram을 맞추는 것이 도움을 줄 수 있습니다. 이 text information을 어떻게 해야 저자들의 network에 가장 잘 포함시킬 것인지가 문제가 됩니다. 간단한 방법으로 L_F와 같이 global condition으로 text information을 추가하는 것입니다. 하지만 text의 temporal information을 무시하게 됩니다. 또 다른 하나는 text와 video의 align을 시도하여 text information을 적용하는 것입니다. 이는 복잡하고 추가적인 error를 발생시킬 수도 있습니다.
text와 video content를 align하는 것에 대한 어려움을 피하기 위해, 저자들은 classifier guidance approach를 활용하여 text guidance를 사용합니다. powerful ASR model을 사용하여 저자들은 guidance에 필요한 다음 식을 계산할 수 있게 됩니다.

이 식에서 t_LR은 lip-reader에 의해 예측된 text입니다. diffusion model의 inference update tstep에서 사용되는 추론된 noise ε^는 classifier guidance와 classifier-free guidance에 의해 다음과 같이 수정될 수 있습니다.

위 식에서 x_t는 diffusion inference process의 t번째 time step의 mel-spectrogram을 의미합니다.
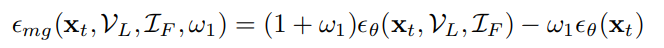
MelGen의 output의 추정된 diffusion noise이고 w_1, w_2는 hyperparameter입니다. 저자들은 model이 audio generation에 foucs하도록 만들기 위해 audio-video ASR 대신 ASR을 사용했습니다.
실험에서 저자들은 generation process에서 ε_mg의 크기가 위 delta 식의 크기보다 훨씬 크다는 것을 알아냈으며, 이는 w_2를 정확하게 setting하기 어렵게 만들며 mel-spectrogram을 추정하는데 어려움을 줍니다. 이를 해결하기 위해 저자들은 gradient normalization factor를 사용합니다. 식은 다음과 같습니다.

위 식에서 || ||는 Frobenius norm입니다.
Classifier guidance는 MelGen을 V만 condition으로 하여 학습할 수 있게 만들어주고, pre-trained ASR을 사용하여 speech match t_LR을 생성할 수 있었습니다. 결과적으로 ASR은 추정된 speech의 정확한 단어를 구하는 데 사용되었고, MelGen은 voice characteristic, V와 x의 synchronization, speech의 연속성을 제공해 줍니다. 이러한 approach의 또 다른 이점은 modularity이며, 이를 통해 lip-to-text module과 ASR module를 쉽게 변경할 수 있습니다. 만약 어떤 module을 변경하고 싶다면, 추가적인 재학습이 필요 없이 바로 적용 가능합니다. 마지막으로 DiffWave vocoder는 reconstructed mel-spectrogram을 time-domain speech signal로 변경하는 데 사용됩니다.
Experiments
Metrics
저자들의 model이 생성한 speech와 baseline method의 speech를 비교하기 위해 quality와 intelligibility를 평가하는 여러 metric을 사용했습니다. speech generation의 goal은 사람이 듣기에 자연스럽고 명료한 speech signal을 생성하는 것이고, 저자들은 MOS를 이용한 human evaluation 측정에 초점을 맞추었습니다. 그리고 저자들은 speech recognition model을 사용하여 WER를 평가했습니다. 그리고 저자들은 generated speech와 matching video 사이의 synchronization을 SyncNet으로 점수를 측정했습니다. 구체적으로 audio와 video 사이의 시간적 거리(LSE-D) 신뢰도 점수 (LSE-C)를 평가했습니다. 저자들은 pre-trained SyncNet model을 사용하여 LSE-C와 LSE-D를 측정했습니다.
객관적으로 quality와 명료성을 평가하기 위해, 저자들은 DNSMOS와 STOI-Net을 사용했습니다. lip-to-speech synthesis 관련 이전 연구들에서 이러한 metric이 적합하지 않다는 것을 보였으며, 그래서 저자들은 주요 report로는 포함시키지 않았습니다. 구체적으로 해당 metric들은 short-time objective intelligibility (STOI)와 perceptual evaluation of speech quality (PESQ)를 사용합니다. 두 metric 모두 clean raw audio signal과의 비교를 통해 점수를 측정합니다. 음성 향상 및 화자 분리에는 유용한 metric이지만, original audio를 recreate하는 task에서는 완벽한 model이라고 볼 수 없습니다. 예를 들어, 원본 음성과 reconstructed speech 간의 pitch 차이에 따라 평가 점수가 많이 달라집니다. 저자들의 목표는 video와 match하는 speech signal을 생성하는 것이지 원본 speech를 복원하는 것이 아닙니다.
Human Evaluation Results
각각 LRS2와 LRS3 test dataset에서 random하게 50개 sample이 주어졌을 때, 저자들은 Amazon Mechanical Turk을 이용해 ground truth와 다른 approach 사이의 차이를 평가했습니다. listener들은 1-5 scale로 Intelligibility, Naturalness, Quality와 Synchronization을 평가했습니다. 이 human evaluator의 score에는 무시할 수 없는 수준의 noise가 있다는 것을 발견했습니다. 저자들은 이 noise를 완화시키기 위해, 각 sample 당 16명의 서로 다른 추가적인 평가자들을 이용했으며, 각 평가자들은 특정 sample에 대해 모든 method를 평가했습니다. 그리고 video 평가에 4점 미만을 준 평가자들은 제외하여 모든 method들이 동일한 신뢰할 수 있는 평가자들에 의해 평가되도록 만들었습니다.
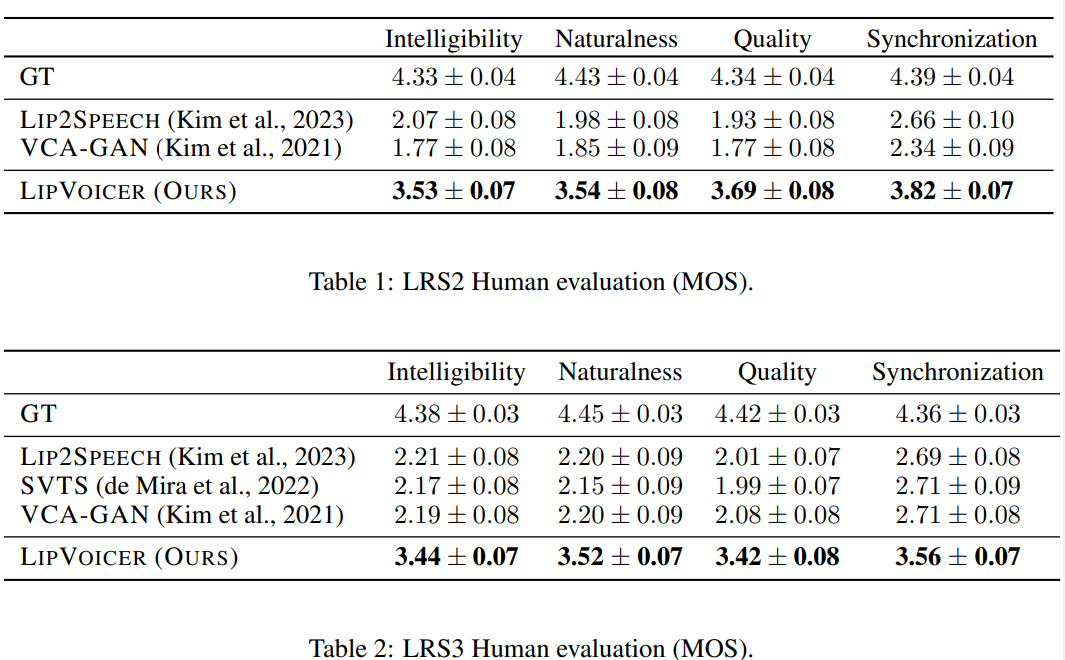
실험 결과는 위와 같습니다. LipVoicer는 baseline method인 Lip2Speech, SVTS, VCA-GAN보다 모든 기준에서 뛰어난 성과를 보여줍니다. 그리고 놀랍게도 ground-truth와 가까운 수치를 보입니다.
Objective Evaluation Results
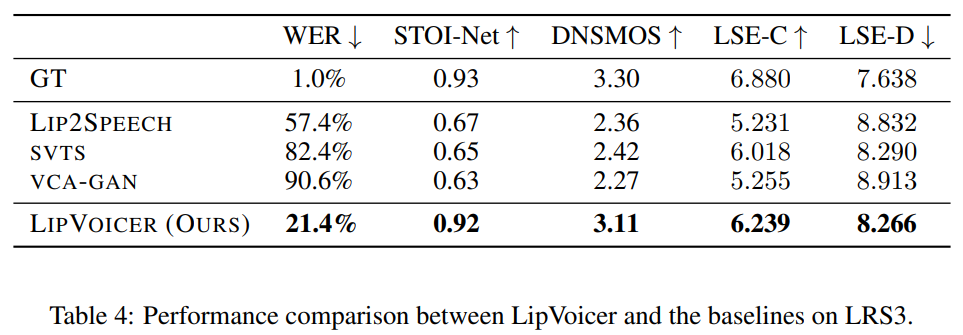
SVTS의 경우, 저자들은 LRS3를 이용하여 WER과 synchronization metric을 평가했습니다. WER score을 보면, 저자들의 method가 뛰어나다는 것을 볼 수 있습니다. STOI-Net과 DNSMOS metric을 보면, LipVoicer가 다른 method들에 비해 더 명확하고 더 높은 quality의 speech를 생성한다는 것을 명확히 볼 수 있습니다.
Conclusion
이 논문에서 저자들은 silent video에서 high quality의 speech를 생성할 수 있는 유망한 새로운 method인 LipVoicer를 제안합니다. LipVoicer는 lip-reading model로부터 text inferred를 얻어서 사용함으로써 자연스러운 audio를 생성할 수 있었습니다. 저자들은 LipVoicer를 실생활 video로 구성된 여러 dataset을 가지고 학습하고 평가했습니다.



