https://arxiv.org/abs/1803.09017
Style Tokens: Unsupervised Style Modeling, Control and Transfer in End-to-End Speech Synthesis
In this work, we propose "global style tokens" (GSTs), a bank of embeddings that are jointly trained within Tacotron, a state-of-the-art end-to-end speech synthesis system. The embeddings are trained with no explicit labels, yet learn to model a large rang
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문에서 저자들은 "global style tokens" (GSTs)를 제안하는데, 이는 end-to-end speech synthesis system인 Tacotron을 이용하여 학습되는 embedding bank입니다. 명시적인 label 없이 embedding은 학습될 수 있으며, 다양한 acoustic expressiveness를 학습할 수 있습니다. GST가 생성하는 soft interpretable label은 text context에 독립적으로 speed나 speaking style과 같은 특징을 포함하는 새로운 speech를 만들 수 있도록 control하는데 사용될 수 있습니다. noisy and unlabeled found data를 가지고 학습하면, GSTs는 noise와 speaker identity를 factorize하도록 학습되며 확장 가능하면서도 robust한 speech를 합성할 수 있습니다.
Introduction
사람과 같은 speech를 만들기 위해선, TTS system이 prosody를 modelling하는 것을 학습해야만 합니다. prosody는 paralinguistic information, intonation, stress, style과 같은 speech의 여러 현상이 결합된 것입니다. 저자들은 style modeling에 focus를 맞추며, 주어진 context에 맞춰 적절한 speaking style을 선택하는 능력을 model에게 제공하는 것이 goal입니다. 정확하게 정의하는 것은 어렵지만, style은 intention, emotion과 같은 여러 정보를 포함하고 있으며 speaker가 intonation과 flow를 선택하는데 영향을 줍니다. 적절한 stylistic rendering은 전체 perception에 영향을 주며 audiobook이나 newsreader와 같은 applicaiton에서 중요한 역할을 합니다.
style modelling은 여러 문제가 있습니다. 첫째, 올바른 prosodic style에 대한 객관적인 평가 metric이 없기 때문에 modelling과 평가 모두 어려움이 존재합니다. 그리고 사람마다 평가가 다를 수 있기 때문에, large dataset에 대한 annotation을 얻는 것도 cost가 많이 들 수 있습니다. 둘째, 표현력이 있는 voice의 high dynamic range는 modelling하기 어렵습니다. 최근 end-to-end system을 포함한 많은 TTS model들은 input data의 averaged prosodic distribution을 학습할 뿐이고, 특히 long-form phrase에 대해서는 표현력이 더 적은 speech를 생성합니다. 그리고 합성된 speech의 표현력을 control하는 능력이 부족하기도 합니다.
이 논문은 "global style tokens" (GSTs)를 최신 end-to-end TTS model인 Tacotron에 적용하는 방식으로 위 문제들을 해결합니다. GSTs는 어떠한 prosodic label없이도 학습되지만 다양한 expressive style을 발견합니다. GSTs의 내부 구조는 다양한 style control과 transfer task에 사용될 수 있는 soft interpretable label을 생성합니다. 그리고 GSTs는 long-form synthesis의 표현력을 크게 향상시킬 수 있습니다. GSTs는 noisy, unlabeled found data에서 바로 사용될 수 있으며, 매우 확장 가능하면서도 robust한 speech를 합성할 수 있습니다.
Model Architecture
저자들의 model은 grapheme 또는 phoneme input에서 mel spectrogram을 예측하는 sequence-to-sequence model인 Tacotron 기반입니다. 이 mel-spectrogram은 low-resource inversion algorithm이나 neural vocoder를 통해 waveform으로 변환될 수 있습니다. Tacotron의 경우, vocoder의 종류가 prosody에 영향을 미치지 않으며, prosody는 seq2seq model에 의해 modelling됩니다.
저자들의 GST model은 아래 그림과 같습니다.
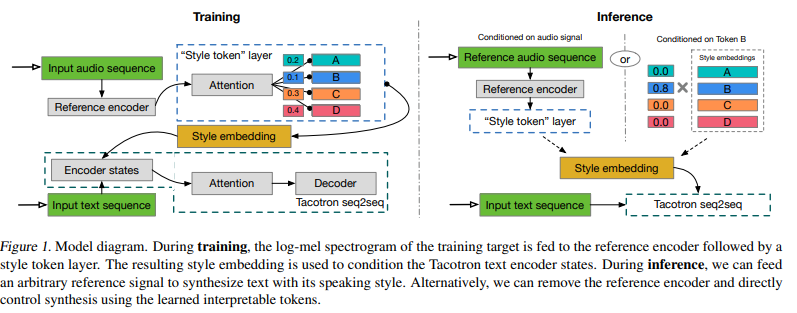
저자들의 GST model은 reference encoder, style attention, style embedding, sequence-to-sequence (Tacotron) model로 구성됩니다.
Training
학습 과정에서, model을 통한 informatoion flow는 다음과 같습니다.
- 가변 길이 audio signal의 prosody를 reference embedding이라 불리는 fixed-length vector로 압축하는 reference encoder입니다. 학습 과정에서 reference signal이 ground-truth audio로 사용됩니다.
- reference embedding은 style token layer로 들어가며, reference embedding을 attention module의 query vector로 사용됩니다. 여기서 attention은 alignment를 학습하는데 사용되지 않으며, reference embedding과 randomly initialized embedding bank에 있는 각 token의 similarity를 학습합니다. 이 global style token (GSTs)라 불리는 이 embedding set은 전체 학습 과정에서 공유됩니다.
- attention module은 encoding된 reference embedding에 각 style token이 얼마나 기여하는지 나타내주는 combination weight set을 output합니다. GST의 weighted sum은 style embedding이라 불리고, 이는 각 timestep에서 text encoder에게 condition으로 pass됩니다.
- style token layer는 model의 남은 부분들과 동시에 학습되며 Tacotron decoder의 reconstruction loss로만 학습됩니다. 그렇기 때문에 GST는 추가적인 explicit style 또는 prosody label이 필요로 하지 않습니다.
Inference
GST architecture는 inference model에서 powerful and flexible control을 위해 design되었습니다. 정보는 두 가지 방식으로 model을 통해 flow됩니다.
- text encoder를 특정 token을 condition으로 만들 수 있으며, 위 그림에서 inference-mode의 오른쪽 부분입니다.
- text가 일치할 필요가 없는 다른 audio signal을 feed하여 style transfer를 수행할 수도 있습니다. 위 그림에서 inference-mode의 왼쪽 부분입니다.
Model Details
Tacotron Architecture
GST-augmented Tacotron system을 위해, 저자들은 몇몇 detail을 제외하고는 나머지 구조와 hyperparameter는 그대로 사용했습니다. phoneme input을 사용하여 학습 속도를 향상시켰으며, decoder의 일부를 수정했습니다. GRU cell을 256-cell LSTM 2개 layer로 대체했습니다. 이때 확률을 0.1로 하는 zoneout을 사용했습니다(이전 timestep에서 10% 확률로 현재 timstep의 값을 무시하고 이전 timestep 값을 유지하는 방식). decoder는 한 번에 두 frame씩 80-channel log-mel spectrogram energy를 output하고, 이는 linear spectrogram을 output하는 dilated convolution network를 통해 수행됩니다. 그리고 저자들은 waveform을 빠르게 reconstruction하기 위해 Griffin-Lim algorithm을 사용했습니다. 이렇게 정의한 저자들의 baseline model은 4.0 MOS를 얻었습니다.
Style Token Architecture
- Reference Encoder
reference encoder는 convolutional stack과 뒤에 RNN을 붙여 design됩니다. log-mel spectrogram을 input으로 받으며, 이를 6개 3x3 kernel, 2x2 stride를 가진 2D convolutional layer와 batch normalization, ReLU activation function의 stack으로 feed합니다. 6개의 convolutional layer의 각 output channel은 32, 32, 64, 64, 128, 128로 설정했습니다. output tensor는 다시 3차원으로 reshape되고 single-layer 128 unit unidirectional GRU로 feed됩니다. 마지막 GRU state는 reference embedding으로 사용되고, 이 값이 style token layer의 input으로 사용됩니다.
- Style Token Layer
style token layer는 style token embedding bank와 attention module로 구성됩니다. 별도의 언급이 없는 한 저자들은 10개 token을 사용했으며, 이를 통해 풍부한 다양한 prosodic dimension을 나타내기에 충분하다는 것을 발견했다고 합니다. text encoder state의 각 차원을 맞추기 위해, 각 token embedidng은 256 dimension으로 맞췄습니다. text encoder state는 tanh activation을 사용했으며, attention을 수행하기 전에 tanh을 GSTs에 수행하는 것이 더 큰 token diversity를 보장한다고 합니다. content-based tanh attention은 softmax activation을 사용하여 token에 대한 combination weight set을 output합니다. GSTs의 weighted combination은 condition으로 사용됩니다. 저자들은 다양한 조합들에 대해 실험을 진행했으며, style embedding을 복제하여 모든 text encoder state에 단순히 더해주는 것이 가장 효과적이라는 것을 알아냈습니다.
content-based attention을 simiarity를 측정하기 위해 사용하지만, dot-product attention, location-based attention, 또는 attention mechanism의 combination으로 대체할 수 있으며, 각각은 다양한 style token을 학습할 수 있습니다. 저자들은 multi-head attention이 style transfer performance를 향상시킨다는 것을 실험을 통해 알아냈으며, 단순히 token 수를 증가시키는 것보다도 더 좋은 성능을 보였다고 합니다. h개의 attention head를 사용할 때, token embedding size는 256/h가 되고, attention output을 concatenate 합니다. 그래서 최종 style embedding size는 유지됩니다.
Model interpretation
End-to-End Clustering/Quantization
직관적으로 GST model은 reference embedding을 일련의 basis vector 또는 soft cluster(즉, style token)로 분해하는 end-to-end method로 생각할 수 있습니다. 각 style token의 contribution은 attention score로 표현되지만, 이는 similarity로 대체될 수 있습니다. GST layer는 VQ-VAE encoder와 개념적으로 유사하며, input은 양자화된 representation을 학습합니다. 저자들은 또한 GST layer를 discrete VQ와 같은 lookup table layer로 대체해 봤지만, 비교 가능한 결과를 얻지 못했다고 합니다.
Experiments: Style Control and Transfer
저자들은 147시간 American English audiobook data를 사용하여 학습했습니다. 몇몇 data들은 상당히 동적이며 표현력 있는 character voice를 포함하고 있기 때문에, model에 있어 challenge가 됩니다.
Style Control
- Style Selection
control하는 것의 가장 간단한 method는 각 token에 model을 conditioning하는 것입니다. inference 할 때, 저자들은 style embedding을 특정 token으로 교체합니다. 이러한 방식의 conditioning은 몇 가지 이점이 존재합니다. 첫째, 각 token이 어떤 style attribute를 encode하는 지 확인할 수 있습니다. 각 token이 pitch와 intensity 뿐만 아니라 speaking rate나 emotion과 같은 다른 attribute들도 나타낼 수 있습니다.
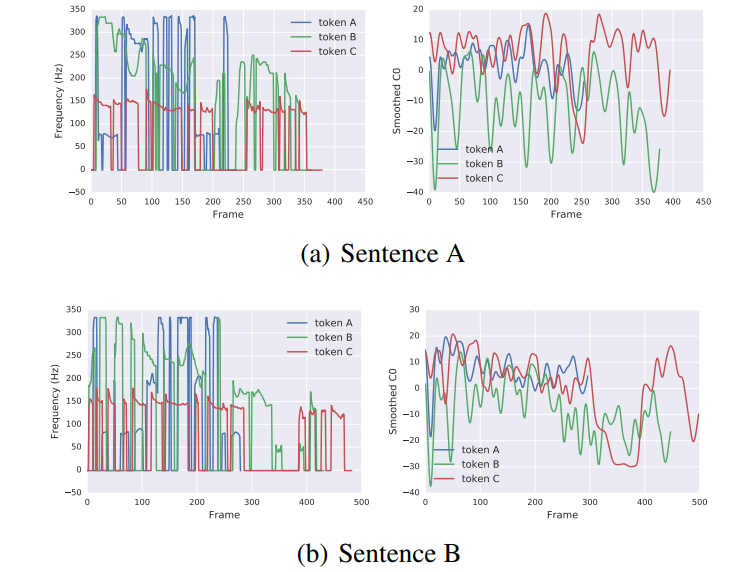
위 그림은 서로 다른 style token (scale = 0.3)을 이용하여 두 문장을 합성한 결과입니다. 위 기름은 F0와 C0(energy) curve를 보여주며 style token별로 다른 것을 볼 수 있습니다. 하지만 sentence A와 sentence B는 명확히 다름에도 불구하고 F0와 C0는 명확한 상대적 경향을 따릅니다. 사람이 인지하기에, red token은 lower pitch voice를 보여주며, green token은 decreasing pitch를 보여주고, blue token은 faster speaking rate를 보여줍니다.
single toen conditioning은 모든 token이 single attribute를 capture하는 것이 아니라는 걸 보여줍니다: 한 token이 speaking rate을 학습한다면, 다른 token들은 training data에 존재하는 stylitic co-occurrence를 반영하는 mixture attribute를 학습할 수 있습니다(예를 들어 low-pitched token이 slower speaking rate도 encode할 수도 있습니다). 더 independent style attribute learning은 앞으로의 연구의 중요한 초점입니다.
해석 가능성을 제공하는 것 외에도, style token conditioning은 합성 quality를 향상시킬 수도 있습니다. 많은 prosodic variation을 가진 long-form synthesis를 합성하는 것에 대해 생각해보겠습니다. 많은 TTS model들은 평균 prosodic style을 학습하는데, 이는 표현력이 풍부한 dataset의 경우 문제가 될 수 있습니다. 왜냐하면 각 표현의 character를 반영하지 못하고 오직 평균치만 반영하기 때문입니다. 이는 또한 문장이 끝으로 갈수록 pitch가 연속적으로 감소하는 것과 같은 부작용을 초래할 수 있습니다. 저자들의 method가 이 두 가지 문제를 모두 해결하고 prosodic variation을 크게 향상시킬 수 있다는 것을 실험을 통해 발견했습니다.
- Style Scaling
style token output을 control하는 다른 방법 중 하나는 scaling입니다. token embedding이 scalar value를 곱하면 style effect가 강해지는 것을 알아냈습니다(scaling value를 크게 설정한 경우, 이해할 수 없는 말을 생성하기도 함). 서로 다른 두 token을 가지고 합성된 발화의 spectrogram을 visualize한 결과가 다음과 같습니다.

(a)의 경우 더 빠른 speaking rate를 나타내고, (b)는 더 animate된 speech를 나타냅니다. (a)는 faster speaking rate token의 scaling factor를 증가시켰을 때 spectrogram의 time domain이 점진적으로 압축되는 것을 볼 수 있습니다. (b)는 animated speech token의 scaling factor를 증가시키는 것이 pitch variation을 증가시키는 것을 보여줍니다. 이러한 style scaling effect는 negative value도 가능합니다.
- Style Sampling
style token layer 내부의 attention module weight를 수정하여 inference 중 synthesis를 control 할 수 있습니다. GST attention이 combination weight를 생성하기 때문에, 이를 수동으로 조정하여 원하는 interpolation을 얻을 수 있습니다.
- Text-side Style Control / Morphing
학습 과정에서 동일한 style embedding이 모든 text encoder state에 더해지지만 inference 시에는 그럴 필요는 없습니다. input text의 다른 segment에 하나 이상의 token을 condition으로 적용하여 부분적인 style을 제어하거나 morphing 할 수 있습니다.
Conclusions and Discussions
이 논문에서 저자들은 Global Style Tokens이라는 end-to-end TTS system에서 modling style에 대한 powerful method를 제안합니다. GSTs는 직관적이며 사용하기 쉽고 명시적인 label 없이도 학습가능합니다. expressive speech data로 학습될 때, GST model은 style을 control하고 변환할 수 있는 해석 가능한 embedding을 만듭니다. GST는 원래 speaking style을 modelling하기 위해 고안되었지만, GSTs는 data의 latent variation을 발견하는 general technique이라는 것도 입증했습니다. 실험을 통해 GST model이 다양한 noise와 speaker factor를 별도의 style token으로 분해하는 것을 학습한다는 것을 보였습니다.



