https://arxiv.org/abs/2309.13664
VoiceLDM: Text-to-Speech with Environmental Context
This paper presents VoiceLDM, a model designed to produce audio that accurately follows two distinct natural language text prompts: the description prompt and the content prompt. The former provides information about the overall environmental context of th
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문은 VoiceLDM이라는 두 natural language text prompt를 통해 정확하게 audio를 생성하는 model을 제안합니다. 여기서 두 natural language text prompt란 description prompt와 content prompt입니다. description prompt는 audio의 전반적인 environmental context에 대한 정보를 제공하고, content prompt는 linguistic content를 포함합니다. 이를 위해 저자들은 latent diffusion model 기반 text-to-audio (TTA) model을 사용하고 이를 추가적인 content prompt를 conditional input으로 사용하기 위해 확장합니다. pretrained contrastvie language-audio pretraining (CLAP)과 Whisper를 사용하여, VoiceLDM은 manual annotation 또는 transcription 없이 대규모 real-world audio로 학습했습니다. 추가적으로 dual classifier-free guidance를 사용하여 VoiceLDM의 controllability를 향상시켰습니다.
Introduction
최근 text-to-audio (TTA)의 발전은 fidelity와 diversity에 있어 큰 성과를 보여주고 있습니다. 이 model들은 natural language prompt에 의해 제공되는 semantic context를 정확하게 반영하는 audio를 합성하는 능력을 보여주고 있습니다. 그럼에도 불구하고 이러한 model들은 speech를 생성할 때 일관된 linguistic output을 생성하는 대신 종종 일관되지 않은 중얼거리는 소리르 생성하기도 합니다.
이러한 한계를 해결하기 위해, 저자들은 언어적으로 이해할 수 있는 voice를 생성할 수 있는 TTA model을 사용하는 TTS model인 VoiceLDM을 제안합니다. VoiceLDM은 content prompt와 description prompt라는 2가지 natural language prompt를 가지고 control 됩니다. content prompt는 spken utterance의 linguistic content를 표현하고, description prompt는 audio의 environmental context를 characterize합니다. 이 연구는 TTS와 TTA의 교차점에 위치한다고 볼 수 있습니다. 저자들이 알기론, TTS model에서 발견되는 speech 이해도를 달성하면서 동시에 TTA model에서 발견되는 다양한 audio 생성 능력을 보이기 위한 첫 연구입니다. 결과적으로 저자들의 model은 sound effect, singing voice, whispering하는 speech를 생성하는 것과 같이 광범위한 sound를 생성할 수 있습니다.
생성된 audio의 style을 control 하기 위해 두 번째 text prompt를 사용하는 TTS 연구들이 등장했습니다. 하지만 성별, 감정, 볼륨과 같이 speech 관련 factor들만 다양하게 control 하다는 한계가 존재합니다.
latent diffusion model 기반 TTA system인 AudioLDM를 기반으로, 저자들은 content prompt를 conditional input으로 사용하도록 확장합니다. 저자들은 CLAP과 Whisper를 이용하여 real-world audio data로 model을 학습시켰습니다. 이를 통해 human annotation이 없는 large-scale dataset으로 학습을 수행할 수 있게 되었으며, 더 좋은 생성 결과를 얻을 수 있다고 합니다.
Method
Model Overview
VoiceLDM의 전체 framework는 다음과 같습니다.
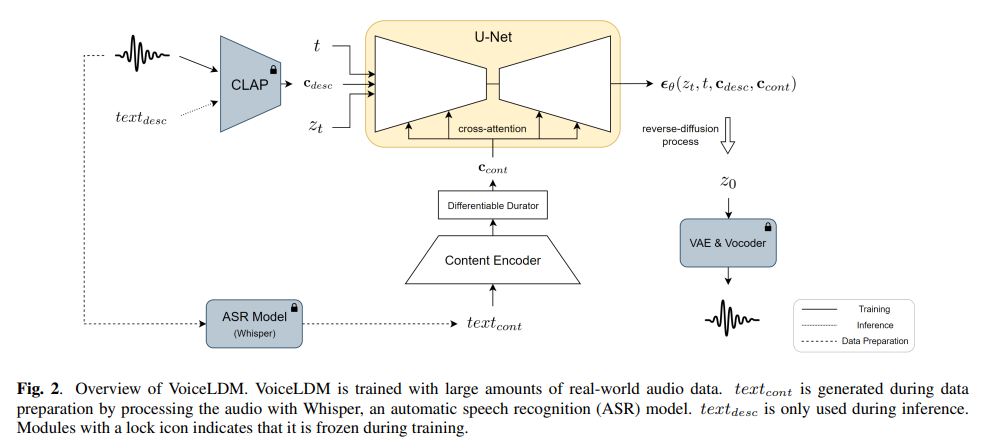
두 natural language text prompt text_{cont}와 text_{desc}가 주어지면, VoiceLDM은 두 input을 condition으로 하는 audio X를 생성합니다. description prompt text_{desc}는 pre-trained CLAP을 통해 512차원 vector c_{desc} ∈R^512로 변환됩니다. CLAP은 두 modality를 동일한 latent space로 project하도록 design 되었기 때문에, reference audio을 이용해 c_{desc}를 얻을 수도 있습니다. content prompt text_{cont}는 content encoder를 이용해 D차원이고 L 길이의 hidden sequence H_{cont} ∈ R^{L x D}로 encode됩니다. 미분가능한 durator는 hidden sequence를 c_{cont} ∈ R^{N x D}로 upsample합니다. θ를 parameter로 사용하는 U-Net backbone은 두 condition c_{desc}와 c_{cont}, 그리고 timestep embedding를 받아 diffusion score ε_θ를 예측합니다.
isotropic Gaussian distribution z ~ N(0, I)로부터 sample 된 random noise에서 시작하여 reverse diffusion process는 각 time step t마다 반복적으로 z_t를 predicted diffusion score를 사용하여 denoise하고 초기 audio prior z_0를 예측합니다. z_0는 pre-trained VAE를 통해 대응하는 mel-spectrogram으로 decode 될 수 있습니다. 마지막으로, pre-trained HiFi-GAN vocoder를 사용하여 mel-spectrogram을 원하는 audio X로 변환합니다.
Training
VoiceLDM의 학습 과정은 latent diffusion model 학습 과정을 대부분 따릅니다. 하지만 저자들의 model은 2가지 condition을 사용하는 diffusion model이라는 점이 다릅니다. audio X에서 시작해, pre-trained VAE는 audio를 latent representation z_0로 압축합니다. timestep t에서의 noisy representation z_t는 forward diffusion process를 통해 z_0에 noise를 추가하는 방식으로 얻어지며, noise schedule은 predefine되어 있습니다.
CLAP은 original audio x를 input으로 받아 descriptive condition c_{desc}를 얻을 수 있기 때문에, description prompt text_{desc}를 사용하지 않아도 됩니다. content encoder와 미분 가능한 durator는 speech transcription text_{cont}를 content condition c_{cont}로 encode합니다. 마지막으로 model은 추가된 noise ε를 예측하도록 학습됩니다.

U-Net의 parameter, content encoder, 미분 가능한 durator 모두 동시에 학습됩니다. pre-trained CLAP model, pre-trained VAE와 vocoder는 train 할 때 frozen된 상태를 유지합니다.
즉 pre-trained VAE를 사용하여 audio를 latent representation z_0를 구합니다. 그다음 forward process를 통해 z_0에 noise를 추가합니다. U-Net은 z_t와 두 condition을 사용하여 각 timestep에서 추가된 noise를 예측하도록 학습되는 구조입니다.
Dual Classifier-Free Guidance
VoiceLDM은 reverse diffusion process에서 각 condition에 대해 독립적으로 classifier-free guidance를 사용할 수 있습니다. 이를 통해 각 condition에 대해 mode coverage와 sample fidelity 사이 trade-off를 조정할 수 있게 되고, 생성 과정의 controllability를 향상시킬 수 있습니다. 두 condition (c_{desc}, c_{cont})을 하나의 condition으로 보면, classifier-free guidance는 다음과 같이 수행될 수 있습니다.

w는 guidance strength를 나타내고 ∅는 null condition을 나타냅니다. dual classifier-free guidance를 사용하여 추가적인 control이 가능합니다. diffusion score ε~은 다음과 같이 표현됩니다.
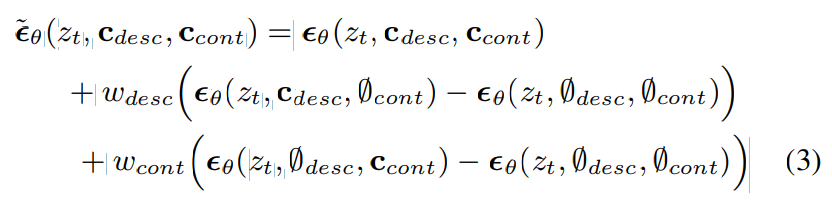
위 식에서 두 w가 같으면 (2) 식과 동일한 효과를 얻게 됩니다. 각 w를 적절히 조작함으로써, 각 condition의 strength를 조절할 수 있습니다. w_{cont}의 value를 높이고 w_{desc} value를 낮게 설정하면, style의 다양성이 증가하면서 linguistic accuracy가 높은 audio를 얻을 수 있습니다. inference 할 때 dual classifier-free guidance가 가능하게 하기 위해, 저자들은 학습 과정에서 condition을 독립적으로 random하게 drop 했습니다.
Experiment Settings
Data Preparation
저자들은 공개된 real-world audio dataset인 AudioSet, CommonVoice 13.0 corpus, VoxCeleb1, DEMAND를 사용해 학습했습니다. 저자들은 이 dataset들을 English speech segment 또는 non-speech segment로 나눴습니다. Common Voice와 VoxCeleb에 있는 audio들은 speech segment로 사용하고, DEMAND에서 얻은 audio들은 non-speech segment로 사용했습니다. AudioSet을 처리하기 위해, 저자들은 automatic speech recognition model인 Whisper를 사용했습니다. audio를 speech segment와 non-speech segment로 나눈 후, 저자들은 speech segment의 transcription인 text_{cont}를 만들었습니다.
저자들은 최종적으로 2.43M speech segment와 824k non-speech segment를 만들었습니다. 모든 audio file을 16kHz sampling rate, mono format으로 resample했습니다. speech segment에 있는 모든 audio는 10초 duration로 맞췄습니다.
Model Configuration
저자들은 VoiceLDM-S와 VoiceLDM-M을 학습했습니다. 두 model은 U-Net backbone의 size 차이만 존재합니다. U-Net backbone이 2개 condition을 condition으로 사용하기 위해, 저자들은 U-Net의 self-attention component를 cross-attention으로 대체하여 c_{cont}를 condition으로 사용했습니다. c_{desc}는 timestep embedding에 concatenate하는 방식으로 condition으로 만들었습니다.
저자들은 pre-trained VAE와 pre-trained vocoder를 사용했습니다. pre-trained CLAP model도 사용했습니다. content encoder로 저자들은 Transformer encoder를 사용했으며, 처음부터 쭉 학습시킬 수 있었지만, TTS에 사용하기 위해 학습된 SpeechT5의 Transformer encoder를 사용했다고 합니다.
Results
Main Result
저자들은 AudioCaps test set을 이용하여 VoiceLDM의 성능을 평가했습니다. English speech를 포함하고 있는 segment들을 모으고, 그에 대응하는 transcription들도 만들었습니다. 저자들은 w_{desc}, w_{cont} 둘 다 7로 설정했습니다.
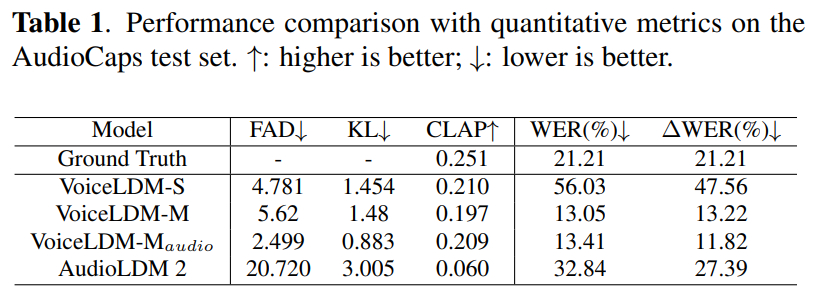
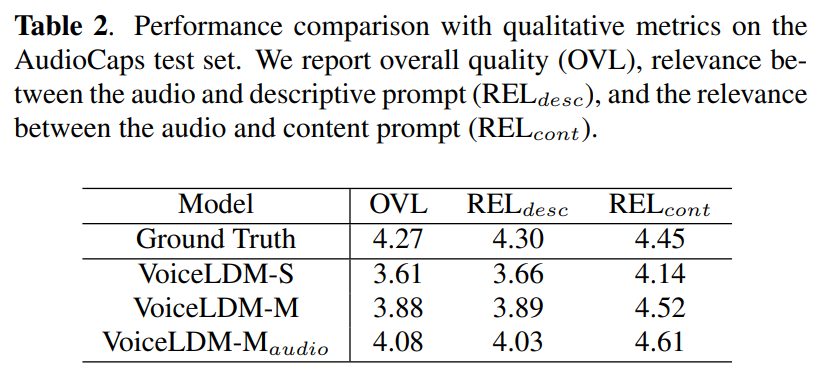
실험 결과는 위와 같습니다. VoiceLDM은 두 input condition을 동시에 만족하는 audio를 생성할 수 있습니다. 가장 큰 model인 VoiceLDM-M은 ground-truth의 speech intelligibility를 뛰어넘으면서도 경쟁력 있는 audio quality를 보여줍니다.
Text-to-Speech Capability
VoiceLDM은 "clean speech"라고 text_{desc} prompt를 설정하면 일반적인 TTS model로 동작할 수 있습니다. 저자들은 VoiceLDM의 TTS 성능을 Common Voice test set으로 평가했습니다. Common Voice test set의 transcription을 text_{cont}로 사용했습니다. w_{desc} = 1, w_{cont} = 9로 설정하고 실험을 진행했습니다. 실험 결과는 다음과 같습니다.
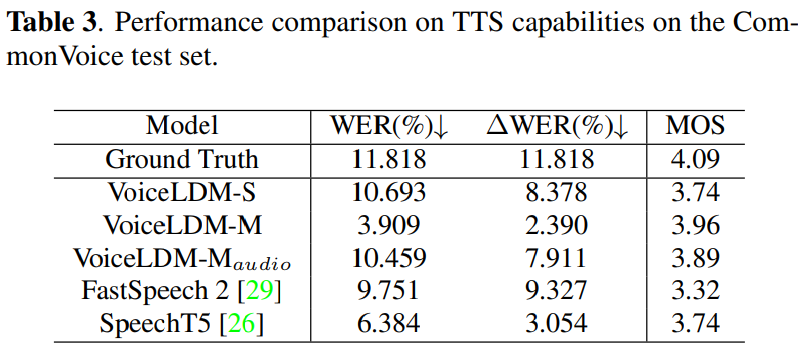
TTS 평가 결과입니다. VoiceLDM-M은 가장 좋은 성능을 보여줍니다.
Text-to-Audio Capability
VoiceLDM이 human voice로 이루어진 audio sample로 학습되었음에도 불구하고 일반적인 zero-shot TTA task를 수행할 수 있는 능력을 보여줍니다. 저자들은 AudioCap test set을 가지고 VoiceLDM의 zero-shot TTA 성능을 평가했습니다. AudioCap test set에서 제공되는 caption은 text_{desc}로 사용하고 text_{cont}는 empty string을 사용했습니다. w_{desc} = 9, w_{cont} = 1로 설정했습니다. 실험 결과는 다음과 같습니다.
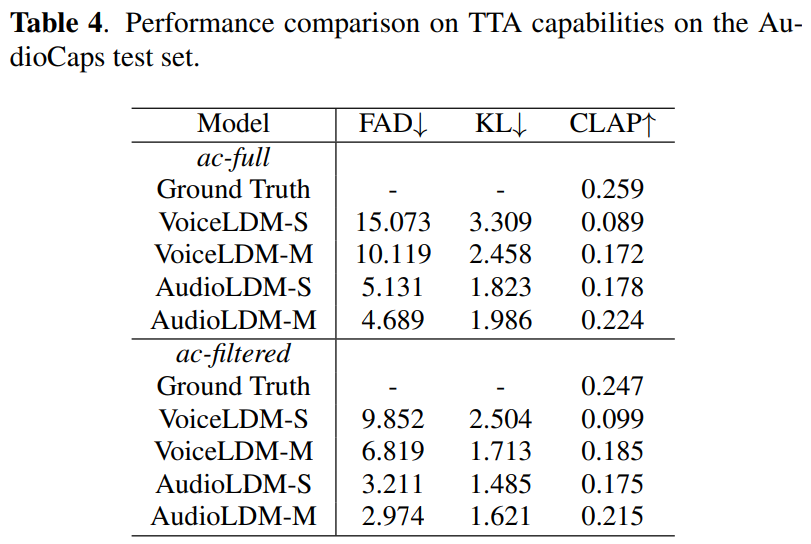
VoiceLDM의 KL 및 CLAP score가 TTA에 특화된 AudioLDM-S와 비교 가능한 정도의 결과를 보여줍니다.
Conclusion
이 논문은 VoiceLDM이라는 environmental context를 control 할 수 있는 TTS model을 제안합니다. VoiceLDM은 CLAP과 Whisper를 이용하여 많은 양의 real-audio data로 학습되었습니다. model controllability를 dual classifier-free guidance로 향상시켰습니다. VoiceLDM은 기본적인 TTS 뿐만 아니라 TTA model 역할도 수행할 수 있습니다.



