https://arxiv.org/abs/2311.05609
What Do I Hear? Generating Sounds for Visuals with ChatGPT
This short paper introduces a workflow for generating realistic soundscapes for visual media. In contrast to prior work, which primarily focus on matching sounds for on-screen visuals, our approach extends to suggesting sounds that may not be immediately v
arxiv.org
해당 논문을 보고 작성했습니다.
Introduction
이 논문은 visual media로부터 real한 soundscape을 만들어내는 workflow를 제안합니다. on-screen visual에 맞는 sound를 생성하는 것에 주로 focus를 맞춘 이전 연구들과 다르게, 저자들은 당장 보이진 않을지라도 설득력 있고 몰입감 있는 청각적 환경을 만들기 위해서는 필수적인 소리들을 만들어 내는 연구를 진행했습니다. 저자들은 ChatGPT와 같은 language model의 성능을 사용하여 model을 구현했습니다.

Method
Creating a Scene Context
scene에 대해 실제같고 세밀한 소리를 만들기 위해, 먼저 scene을 detail하게 이해하는 것에 대한 연구를 진행했습니다. 저자들은 multi-level and multimodal 상황에서 scene에 대한 이해를 수행했습니다.

첫 layer는 visible object에 focus를 맞춥니다. Object365 dataset과 Open Image dataset을 이용하여 object detection을 수행했습니다. 두 번째 layer에서는 표지판의 text, speech의 text와 같은 environment cue에 focus를 맞췄습니다. Tesseract OCR을 사용해 visible 표지판으로부터 text를 추출했으며, 이 text에는 물건의 이름이나 지역명 등의 정보를 나타내기도 합니다. Whisper ASR을 사용하여 spoken word를 transcribe 했으며, BEAT를 사용해 소리를 식별했습니다. 그다음 세 번째 layer는 위치, 시간, 날씨와 같은 일반적인 context와 전반적인 scene의 context에 focus를 맞췄습니다. CLIP을 사용하여 scene이 야외인지, 실내인지 분류했습니다. scene이 실내로 분류되면, Places365 dataset을 이용한 CLIP으로 해당 장소를 분류했습니다. 만약 scene이 야외로 분류되었다면, CLIP을 이용해 날씨가 맑은지, 안개가 꼈는지, 바람이 부는지, 구름이 많은지, 번개가 치는지와 같이 분류했습니다. 그다음 BLIP을 사용해 전체 scene을 설명하는 긴 descriptive sentence를 생성했습니다. 마지막으로 다양한 scene을 이해한 결과를 ChatGPT의 scene context prompt 형태로 format 했습니다.

위 형태와 같이 GPT의 prompt 형태로 변환했습니다.
Brainstorming Sounds
그다음 저자들은 scene에 대한 context를 ChatGPT에 feed 한 다음 'what do I hear?'라는 prompt를 입력했습니다. ChatGPT의 성능을 이용하여, 저자들은 scene에 대한 묘사에 맞춰 세밀하고 다양한 소리를 상상할 수 있으며 풍경에 대한 audio, 지금 당장 보이지는 않지만 들릴 수 있는 소리들도 포함됩니다.
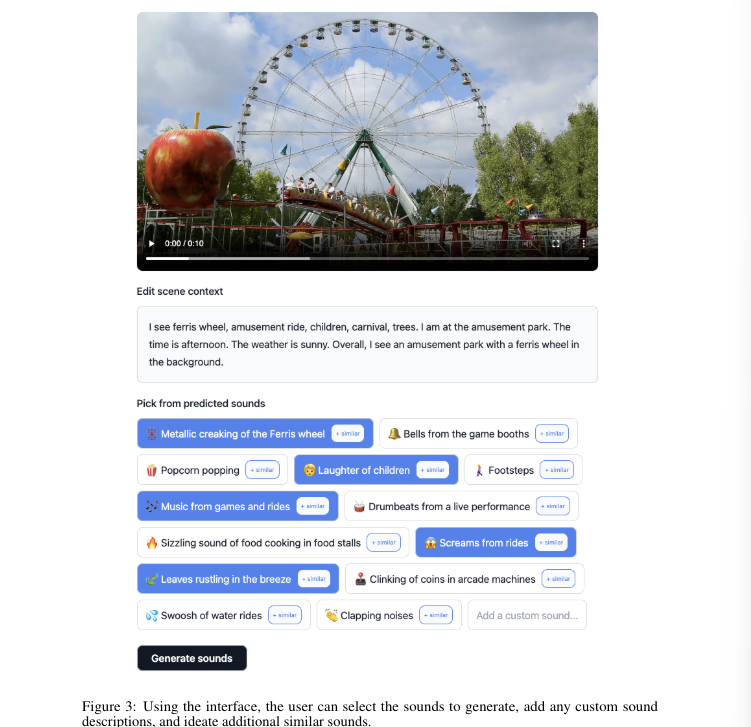
저자들은 위와 같이 interface를 구현했습니다. 사용자는 제안된 소리들 중 선택을 할 수 있으며 sound description을 직접 작성할 수도 있습니다. 그리고 저자들은 ChatGPT를 이용해 각 소리에 가장 의미적으로 유사한 emoji를 할당받아 사용했습니다. 그리고 similar button을 누르면, GPT를 이용해 제안된 소리와 유사한 추가적인 소리를 제안해 준다고 합니다.
Generating the Sounds
사용자가 여러 소리를 선택하면, AudioGen이라는 text-to-audio model을 이용하여 soundtrack을 합성합니다. 선택된 소리들에 맞춰 각각의 soundtrack을 만들고 난 후, 시각적 정보를 기반으로 각 soundtrack의 volume을 예측합니다. spaCy NLP library를 이용하여 각 제안된 소리의 주체를 추출합니다. 그다음 CLIP을 사용하여 소리의 주체가 시각적으로 video에 나타내는지 detect 합니다. 만약 소리의 주체가 감지되지 않는다면, background sound로 분류하고 volume을 7dB로 감소합니다. 만약 소리의 주체가 감지된다면, foreground sound로 분류합니다. foreground sound의 경우, Soundify와 유사하게 소리를 localize 합니다.
먼저 Grad-CAM을 사용하여 activation map을 시각화합니다. 그다음 activation map의 크기를 사용하여 주체의 크기를 추정하고, 그에 맞춰 volume을 조절합니다(가까이 있을수록 큰 소리). 저자들의 방식대로 구한 각 volume은 default로 설정하고, 사용자가 본인이 원하는 대로 각 soundtrack의 volume을 조절할 수 있도록 interface를 구현했습니다. 마지막으로 저자들은 최종 결과(visual + combined soundtracks)와 각 soundtrack 또는 combined soundtrack을 export 할 수 있도록 option을 구현했습니다.
Conclusion and Future Work
이 논문에서는 시각적 media로부터 soundscape를 생성하는 workflow를 제안합니다. 앞으로는 움직임과 객체에 대한 이해와 같은 풍부한 scene context를 더 풍부하게 포함하는 연구를 수행할 것이라고 합니다.



