https://arxiv.org/abs/2301.12503
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose Audio
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Text-to-audio (TTA) system은 text description을 기반으로 audio를 합성하는 task입니다. 하지만 이전 TTA 연구들은 연산량이 많고 quality가 떨어진다는 한계가 있습니다. 이 연구에서 AudioLDM라는 TTA system을 제안합니다. contrastive language-audio pretraining (CLAP) embedding으로부터 연속적인 audio representation을 학습하기 위해 latent space를 사용하는 TTA system을 제안합니다. pretrained CLAP model은 LDM이 audio embedding을 학습할 수 있게 만들어주고, sampling 할 때는 text embedding을 condition으로 제공합니다. cross-modal relationship을 modelling하지 않고 audio signal의 latent representation을 학습함으로써, AudioLDM은 generation quality와 연산 효율성 모두 향상시킬 수 있었습니다.
Introduction
sound effect, music 또는 개인이 원하는 speech를 생성하는 것은 augmented and virtual reality, game development, video editing과 같은 application에서 매우 중요합니다. 일반적인 audio generation은 신호 처리 기술을 통해 수행되었습니다. 최근 몇 년동안 생성 모델의 발전은 이 task의 혁신을 일으켰습니다. 이전 연구들은 주로 UrbanSound8K dataset의 10개 sound class와 같이 소수의 label을 사용하여 label-to-sound setting에서 진행되었습니다. label에 비해 자연어는 훨씬 flexible하고 더 세밀하게 audio signal을 묘사하는 description을 생성할 수 있습니다. 이러한 자연어 description을 prompt로 사용하여 audio를 생성하는 task를 text-to-audio (TTA) generation이라 부릅니다.
TTA system은 광범위한 고차원 augio signal을 생성하기 위해 design됩니다. data를 효율적으로 modelling하기 위해 저자들은 DiffSound처럼 고차원 audio signal을 효율적으로 modelling하는 학습된 discrete representation을 사용합니다. 그리고 저자들은 AudioGen과 같이, waveform에서 discrete representation을 autoregressive하게 modelling하는 것에서도 영감을 받았습니다. latent diffusion models (LDMs)를 사용하여 고품질의 image를 생성하는 StableDiffusion의 성공을 통해, 저자들은 discrete representation을 학습하던 이전 TTA 방식들을 변경하여 continuous latent representation을 학습하도록 만들었습니다.
이전 TTA 연구들의 경우, 대규모 high quality audio-text data pair가 있어야 generation quality를 보장할 수 있는데, 사용 가능한 audio-text data pair는 quality가 떨어집니다. low-quality data를 더 잘 활용하기 위해, 여러 text 전처리 method들이 등장했습니다. 하지만 전처리는 sound event의 관계를 간과하여 생성 성능의 제한을 만듭니다. 이에 비해 저자들의 method는 생성 모델을 학습할 때 audio data만 필요로 하고, text 전처리의 어려움을 피하고 audio-text paired data를 사용했을 때보다 더 좋은 quality를 보여줍니다.
이 논문에서 AudioLDM이라는 TTA system을 제안하며, 이는 continuous Latent Diffusion Model을 활용하여 high generation quality를 수행합니다. 그리고 연산 효율성이 좋고 text-conditional audio 조작이 가능합니다. TTA generation과 text-guided audio manipulation을 위한 AudioLDM design은 다음과 같습니다.
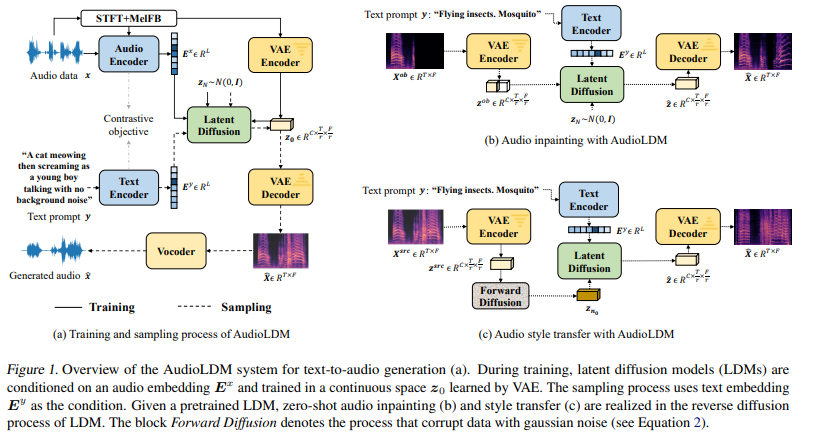
구체적으로 AudioLDM은 mel-spectrogram based VAE를 가지고 encode된 latent space에서 representation을 생성하도록 학습됩니다. contrastive language-audio pretraining (CLAP) embedding을 condition으로 하는 LDM은 VAE latent generation에 대해 개발되었습니다. CLAP의 audio-text aligned embedding space을 사용함으로써 LDM을 학습할 때 audio-text paired data가 필요함을 없앴습니다. VAE laten generation의 condition은 audio에서 바로 구할 수 있게 만들었습니다. 저자들은 LDM을 audio만 가지고 학습하는 것이 audio-text paired data를 사용했을 때보다 더 좋다는 것을 입증했습니다. 저자들의 contribution은 다음과 같습니다.
- TTA generation으로 continuous LDM을 개발한 첫 연구입니다. 저자들의 AudioLDM method는 subjective evaluation과 objective metric 모두에서 존재하는 method보다 더 뛰어난 성능을 보였습니다.
- CLAP embedding을 사용해 language-audio pair를 사용하지 않고 LDM을 학습시켜 TTA generation을 수행할 수 있었습니다.
- audio data만 사용하여 LDM을 학습시키는 것이 TTA system의 연산 효율성을 증가시켜주고 high quality generation을 수행할 수 있다는 것을 실험적으로 보였습니다.
- text-guided audio style manipulation을 수행할 수 있는 TTA system을 제안했습니다.
Related Work
Text-to-Audio Generation
최근 몇 년동안 큰 주목을 받았습니다. 주어진 자연어 description을 가지고 어떻게 discrete space에서 audio representation을 학습할지, 어떻게 representation을 audio waveform으로 decode 할지 연구되었습니다. 두 연구 모두 audio-text paired data를 사용하여 latent generation model을 학습하기 때문에, low quality & scarcity of paired data문제를 해결해야만 합니다.
DiffSound는 text encoder, decoder, vector-quantized variational autoencoder (VQ-VAE)와 vocoder로 구성됩니다. audio-text paired data가 부족하다는 문제를 완화시키기 위해, DiffSound 저자들은 mask-based text generation strategy(MBTG)를 사용하여 audio label로부터 text description을 생성했었습니다. 예를 들어 'dog bark, a man speaking'이라는 label이 '[M] [M] dog bark [M] man speaking [M]'로 변환됩니다. 여기서 [M]은 mask token입니다. 하지만 MBTG를 이용해 생성된 text는 여전히 label information만 담고 있으며, model의 성능을 저하시킵니다.
AudioGen은 waveform을 압축하여 바로 target discrete token을 생성할 수 있도록 학습시키기 위해 Transformer-based decoder를 사용합니다. AudioGen은 10개 dataset으로 학습되고, 학습 data의 다양성을 늘리기 위해 data augmentation도 수행했습니다. language-audio pair를 만들 때, 저자들은 language description을 label로 전처리하여 class-label annotation 분포에 더 잘 맞추고 task를 단순화하였습니다. 예를 들어 text description 'a dog is barking at the park'는 'dog bark park'로 변환되는 방식입니다. 저자들은 audio sample을 다양한 signal-to-noise ratio에 맞춰 섞고, transformed language description을 concatenate하여 data augmentation을 수행했습니다. 이는 공간적, 시간적 관계를 나타내는 detailed text description이 생략된다는 것을 의미하기도 합니다.
Text-Conditional Audio Generation
Contrastive Language-Audio Pretraining
Text-to-Image generation model은 Cotrastive Language-Image Pretraining (CLIP)을 사용하여 image prior를 생성하는 방식으로 놀라운 sample quality를 보여줍니다. 이러한 사실에서 영감을 받아, 저자들은 Language-Audio Pretraining (CLAP)을 TTA generation에 적용했습니다.
audio sample을 x로 나타내고 text description을 y로 나타내겠습니다. text encoder f_{text}()와 audio encoder f_{audio}()는 text embedding E^y와 audio embedding E^x를 추출하는 데 사용됩니다. 그리고 각 embedding은 L차원이며, L은 CLAP embedding의 차원입니다. 최근 연구에서는 CLAP model을 학습할 때, text encoder 와 audio encoder로 다양한 architecture들을 사용했습니다. 저자들은 그러한 실험 결과들을 바탕으로, audio encoder는 HT-SAT 기반 architecture를 사용했고, text encoder는 RoBERTa 기반 architecture를 사용했습니다. symmetric cross entropy loss를 사용하여 학습을 진행했습니다.
CLAP model을 학습한 후, audio sample x는 audio text embedding space에 있는 embedding E^x로 변환됩니다. CLAP model의 일반화 성능을 다양한 downstream task에서 증명되었습니다. 그래서 unseen language or audio sample에 대한 CLAP embedding은 cross-modal information을 제공할 수 있습니다.
Conditional Latent Diffusion Models
TTA system은 주어진 text description y에 맞는 audio sample x^를 생성할 수 있습니다. probabilistic generative model LDMs을 사용하여, 저자들은 true conditional data distribution q(z_0 | E^y)를 model distribution p_θ(z_0 | E^y)로 추정할 수 있습니다. 여기서 z_0 ∈ R^(C x T/r x F/r)는 audio sample x의 prior를 의미하고, z_0는 mel spectrogram X의 압축된 representation으로부터 형성된 space에 존재하고, E^y는 CLAP에 있는 pretrained text encoder f_{text}()에 의해 얻어진 text embedding입니다. r은 compression leveld을 나타내고, C는 compressed representation의 channel을 의미하고 T는 mel-spectrogram X의 time dimension, F는 frequency dimension을 나타냅니다. pretrained CLAP을 가지고 audio와 text information을 동시에 embed 할 때, audio embedding E^x와 text embedding E^y는 공통 cross-modal space를 사용합니다. 이는 LDMs을 학습할 때 E^x를 사용하지만, TTA generation에서는 E^y를 사용하는 것을 가능하게 만들어줍니다.
Diffusion model은 두 가지 과정으로 구성됩니다. 1) 정해진 noise schedule을 사용해 data 분포를 standard Gaussian distribution으로 변환하는 forward process, 2) inference noise schedule에 맞춰 noise로부터 data sample을 점진적으로 생성하는 reverse process로 구성됩니다.
forward process에서, 각 time step n ∈ [1, ... , N]의 transition probability는 다음과 같이 정의됩니다.
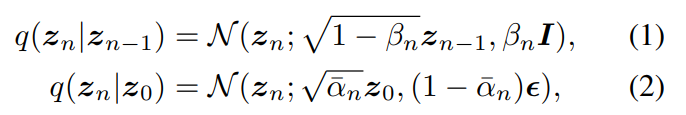
위 식에서 ε ~ N(0, I)는 injected noise를 나타내며, α_n은 1 - β_n의 reparameterization을 나타내고, α_n^는 모든 α_n의 곱을 나타냅니다. 최종 final time step N에서, z_N ~ N(0, I)는 standard isotropic Gaussian distribution이 됩니다. model 최적화를 위해, 저자들은 reweighted noise estimation training 방식을 사용했습니다. 식은 다음과 같습니다.
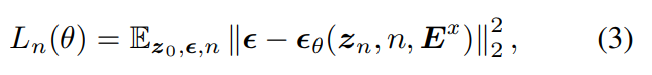
위 식에서 E^x는 CLAP에 있는 pretrained audio encoder f_{audio}()로부터 생성된 audio waveform x의 embedding입니다. reverse process에서는 Gaussian noise distribution p(z_N) ~ N(0, I)와 text embedding E^y에서 시작을 하며, E^y를 condition으로 하는 denoising process는 전짐적으로 audio prior z_0를 생성합니다. 식은 다음과 같습니다.
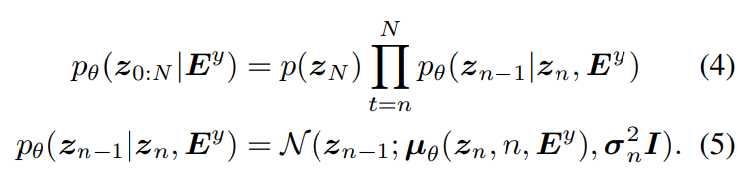
평균과 분산은 parameterize됩니다. 식은 다음과 같습니다.
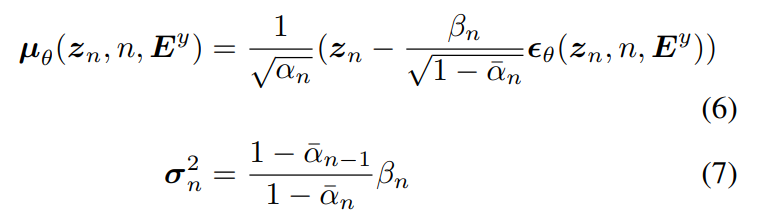
위 식에서 ε_θ는 predicted generation noise이고 σ^2 = β_1입니다. 학습 과정에서 주어진 audio sample x의 cross modal representation E^x를 가지고 audio prior z_0의 generation을 학습합니다. TTA generation에선, text embedding E^y를 사용해 noise를 예측합니다. CLAP embedding을 사용하여, 학습 과정에서 text supervision을 사용하지 않습니다.
Conditioning Augmentation
text-to-image generation에서, diffusion-based model은 object와 background 사이의 세밀한 detail을 capture할 수 있다고 입증되었습니다. 이러한 성공의 원인 중 하나는 대규모 language-image training pair입니다. LAION의 경우 400 million image-text pair가 존재합니다. TTA generation의 경우, 자연어 description과 일관성 있는 관계를 보이는 audio signal을 생성할 수 있어야 합니다. 하지만 사용 가능한 language-audio dataset이 language-image dataset에 비해 현저히 적습니다. AudioGen의 경우 data augmentation을 하기 위해, audio sample들을 mix하고 해당하는 text caption을 concatenate하여 새로운 paired data를 생성하는 mixup strategy를 사용합니다. 이 연구에서는 LDMs을 학습할 때 audio embedding E^x만 condition information으로 제공하기 때문에, language-audio pair를 augmentation 하는 대신 audio signal만 augmentation을 수행합니다. 구체적으로 audio x1, x2를 이용한 저자들의 mixup augmentation은 다음과 같습니다.
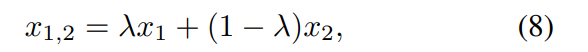
위 식에서 λ는 Beta distribution β(5, 5)에서 sample된 [0, 1] 사이의 scaling factor입니다. text description은 고려할 필요가 없습니다. audio pair를 mixing 하는 방식으로, 저자들은 training data pair(z_0, E^x)를 증가시켜 LDMs이 더 robust하게 만들었습니다. sampling 과정에서 unseen language description으로부터 text embedding E^y가 주어진다면, LDMs는 그에 대응하는 audio prior z_0를 생성할 수 있습니다.
Classifier-free Guidance
diffusion model의 경우, 각 sampling step마다 guidance를 적용하여 controllable generation을 수행할 수 있습니다. classifier guidance 이후에, classifier-free guidance (CFG)가 guiding diffusion model의 최신 기술로 등장했습니다. 학습과정에서, 고정된 확률로 condition인 E^x를 없앱니다. 예를 들어 10% 확률로 LDM은 unconditional하게 학습이 됩니다. 생성할 때는, 저자들은 text embedding E^y를 condition으로 사용하기 때문에, noise estimation을 E^y로 수정하여 사용했습니다.
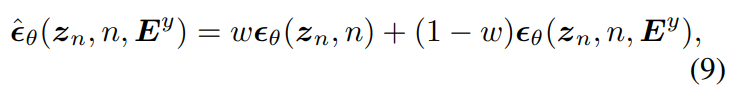
위 식에서 w는 guidance scale입니다. AudioGen과 비교했을 때, 두가지 차이점이 있습니다. AudioGen은 transformer-based auto-regressive model에 CFG를 적용했었지만, 저자들은 LDM에 적용하여 이론적인 공식을 유지했습니다. 그리고 저자들의 text embedding E^y는 처리되지 않은 natural language로부터 추출되기 때문에, CFG가 audio generation에 있어 더 detail 한 text description을 guidance로 사용할 수 있습니다. 하지만 AudioGen은 text 전처리 과정을 통해 공간적 또는 시간적 정보와 같은 detail을 제거한 text를 사용합니다.
Decoder
VAE를 사용하여 mel-spectrogram X를 small latent space z ∈ R^(C x T/r x F/r)로 압축하며, r은 latent space의 compression level입니다. 저자들은 VAE의 encoder와 decoder를 convolutional module을 stack하여 구현했습니다. training objective로 reconstruction loss, aadversarial loss, Gaussian constraint loss를 사용했습니다. sampling 과정에서, decoder를 사용하여 LDMs이 생성한 audio prior z_0^로부터 mel-spectrogram X^를 reconstruct합니다. r = 4를 default setting으로 설정했습니다. 이 경우 가장 높은 연산 효율성과 생성 quality를 보였다고 합니다. 그리고 VAE가 생성된 sample의 reconstruction quality를 보장하기 위해, 위 식 (9)과 함께 data augmentation을 수행했습니다. vocoder로 저자들은 HiFi-GAN을 사용하였으며, vocoder는 reconstructed mel-spectrogram X^로부터 audio sample x^를 생성합니다.
Text-Guided Audio Manipulation
Style Transfer
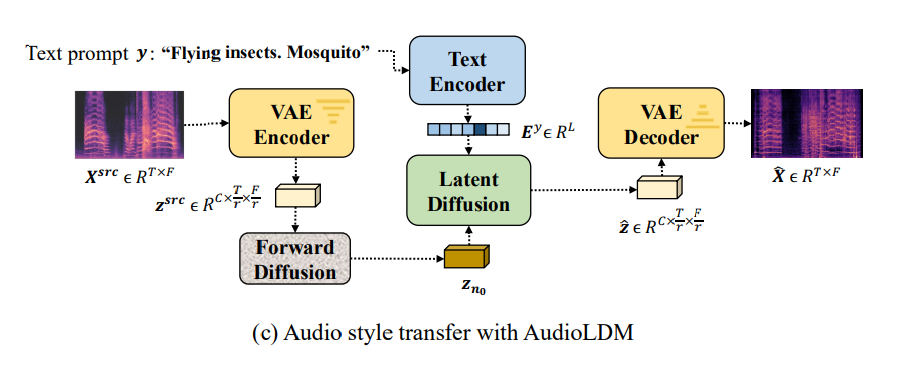
source audio sample x^{src}가 주어졌을 때, predefined time step n0에 맞춰 forward process를 수행하여 latent representation z_n0를 계산할 수 있습니다. z_n0를 pretrained AudioLDM model의 reverse process starting point로 사용함으로써, text input y으로 audio x^{src}를 조작할 수 있습니다.
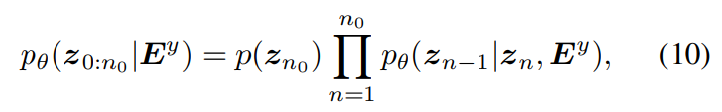
n_0는 manipulation result를 control합니다. n_0가 N에 가깝다면, source audio에서 제공되는 정보가 포함되지 않을 것이고 TTA generation과 유사하게 됩니다 n_0의 영향은 아래와 같습니다.

위 실험을 통해 저자들은 n_0 = 3N/4일 때 더 큰 manipulation을 확인할 수 있었습니다.
Inpainting and Super-Resolution
audio inpainting과 audio super-resolution 둘 다 관찰된 x^{ob}을 가지고 생략된 부분을 생성하는 task입니다. latent representation z^{ob}와 생성된 latent representation z를 통합하는 방식으로 task를 수행합니다. 구체적으로 p(z_N) ~ N(0, I)에서 시작하는 reverse process에서 각 inference step을 수행한 후 생성된 z_{n-1}을 수정합니다.
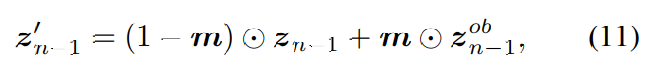
위 식과 같이 수정합니다. z'는 수정된 latent representation이고 m은 latent space에서의 observation mask를 나타냅니다. z_{n-1}^{ob}는 z^{ob}에 forward process로 noise를 추가하여 구해집니다.
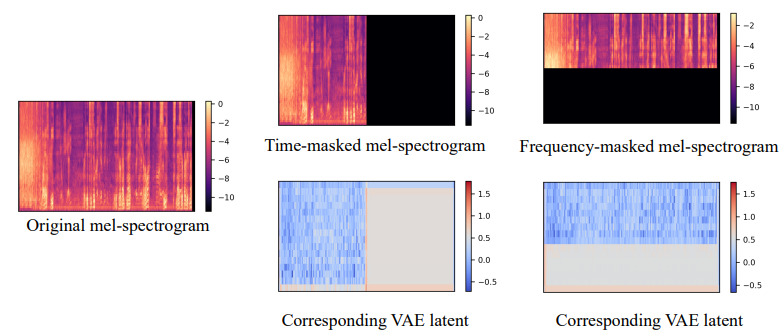
observation mask m의 값은 mel-spectrogram X의 관측된 부분에 의존합니다. VAE로 convolutional structure를 사용하여 latent representation z를 학습하면, 위 그림과 같이 mel-spectrogram에서 공간성을 대략적으로 유지할 수 있습니다. 그러므로 만약 time-frequency bin X_{t, f}가 관측된다면, 해당 위치의 observation mask m을 1로 설정합니다. m을 사용하여 생성할 부분과 관측된 부분을 나타내고, TTA model을 가지고 text prompt를 condition으로 하여 손실된 정보를 생성할 수 있습니다.
Experiments
Training dataset
저자들은 AudioSet (AS), Audio-Caps(AC), Freesound (FS), BBC Sound Effect library (SFX)를 사용했습니다. AS는 5000시간의 527개 label로 구성된 audio dataset입니다. AC는 49000개 text description이 있는 audio clip입니다. AudioSet과 AudioCAP은 YouTube에서 구해지기 때문에, audio quality가 보장되지 않습니다. 고품질 audio data을 포함하도록 확장하기 위해, 저자들은 FreeeSound와 BBC SFX datsaet을 사용했습니다.
Evaluation methods
저자들은 objective evaluation과 human subjective evaluation 모두 수행했습니다. objective evaluation으로 frechet distance (FD), inception score (IS), Kull-back-leibler (KL) divergence를 수행했습니다. FD는 생성된 sample과 target sample 사이의 유사도를 측정해 줍니다. IS는 sample quality와 diversity 둘 다 측정할 수 있는 효율적인 방법입니다. KL은 paired sample을 가지고 수행되고, 최종 결과로 평균치를 output합니다. 그리고 frechet audio distance (FAD)도 수행하였습니다. generation quality를 좀 더 잘 평가하기 위해, 저자들은 FD를 main evaluation으로 사용했습니다.
subjective evaluation으로 저자들은 overall quality (OVL), relevance to the input text (REL)을 측정했습니다.
Results
AC test 결과는 다음과 같습니다.
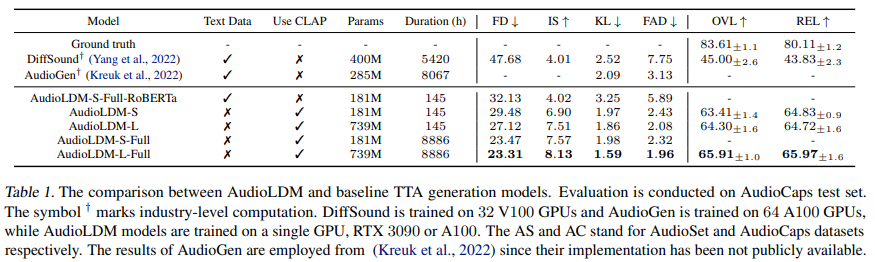
single training dataset AC가 주어졌을 때, AudioLDM-S는 baseline model보다 더 작은 model size를 가지면서도 objective and subjective evaluation 모두 더 뛰어난 결과를 보여줍니다. model capacity를 확장한 AudioLDM-L의 경우, 전체적인 성능이 크게 향상되었습니다. 저자들은 AS와 다른 두 dataset을 합쳐서 training set으로 사용했을 때, AudioLDM-L-Full의 성능이 가장 좋았다고 합니다. RoBERTa와 CLAP은 동일한 text encoder structure를 가지고, CLAP은 생성 model 학습과 audio-text relationship learning을 분리하기 때문에 이점이 있습니다. CLAP은 audio와 text를 embedding space에서 align 함으로써 둘 사이의 relationship을 modelling할 수 있기 때문에 decoupling이 가능합니다. 하지만 text encoder가 textual information만 표현하는 AudioLDM-S-Full-RoBERTa는 model이 text-audio relationship과 audio generation process를 동시에 학습해야 합니다. 추가적으로 저자들의 CLAP-based method는 model이 audio만 사용하여 학습됩니다. 그러므로 pretraining CLAP 없이 Roberta를 사용하는 것은 학습 어려움을 증가시킬 수 있습니다.
Conclusions
저자들은 TTA generation을 수행하 수 있는 AudioLDM을 제안합니다. 이는 contrastive language audio pretraining (CLAP) model과 latent diffusion models(LDMs)를 사용합니다. 저자들의 method은 생성 quality, 연산 효율성, audio manipulation에 이점이 있습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Soundify: Matching Sound Effect to Video (0) | 2024.06.24 |
|---|---|
| [논문] AudioCLIP: Extending CLIP to Image, Text and Audio (0) | 2024.06.23 |
| [논문] Generating Realistic Images from In-the-wild Sounds (0) | 2024.06.20 |
| [논문] What Do I Hear? Generating Sounds for Visual with ChatGPT (0) | 2024.06.19 |
| [논문] VoiceLDM: Text-to-Speech with Environmental Context (0) | 2024.06.19 |



