https://arxiv.org/abs/2106.13043
AudioCLIP: Extending CLIP to Image, Text and Audio
In the past, the rapidly evolving field of sound classification greatly benefited from the application of methods from other domains. Today, we observe the trend to fuse domain-specific tasks and approaches together, which provides the community with new o
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
domain specific task와 approach를 서로 fuse하는 trend가 있고, 새로운 model이 개발되고 있습니다. 이 논문에서 저자들은 text와 image 뿐만 아니라 audio도 다루는 CLIP model의 확대 version을 제안합니다. AudioSet을 사용하여 ESResNeXT audio-model을 CLIP framework에 적용합니다. 이러한 combination은 model이 bimodal 또는 unimodal classification, querying을 수행할 수 있으며, CLIP의 unseen dataset에 대한 zero-shot infernce 성능도 보여줍니다. AudioCLIP은 Environmental Sound Classification (ESC) task에서 가장 좋은 성능을 보입니다. 그리고 cross-modal querying performance도 좋게 나옵니다.
Introduction
이전 연구들에서는 audible modality만 사용한 classification task에 집중했었습니다. 하지만 최근 몇 년 동안, audio관련 task에서 multimodal approach들이 증가되고 있습니다. sound 외에도 textual or visual modality를 사용하는 방식으로 이뤄지고 있습니다. audio와 추가적인 modality를 사용하는 것은 드문 일이 아니지만, two modality 이상의 combination은 audio domain에서는 여전히 흔치 않습니다. 하지만 질 좋은 labeled data의 양이 제한적이기 때문에, multimodal 및 unimodal 모두 발전의 제한을 받고 있습니다. 이러한 data 부족 때문에 textual description을 사용하는 contrastive learning 기반 zero-, few-shot learning approach들이 큰 성장을 이루었습니다.
저자들은 high-performance audio model인 ESResNeXt와 contrastive text-image model인 CLIP 결합한 tri-modal hybrid architecture를 제안합니다. base CLIP model은 성능이 좋고, zero-shot inference라 불리는 domain adaptation 성능이 입증되었습니다.
저자들의 방식처럼 학습 과정에서 three modality를 동시에 사용했을 때, environmental sound classification task에서 이전 model들보다 더 뛰어난 성능을 보였습니다. 그 뿐만 아니라 text, image, audio의 어떠한 combination이라도 cross-modal querying을 수행할 수 있으며, base architecture의 zero-shot capability를 확장시킨 모습입니다.
Model
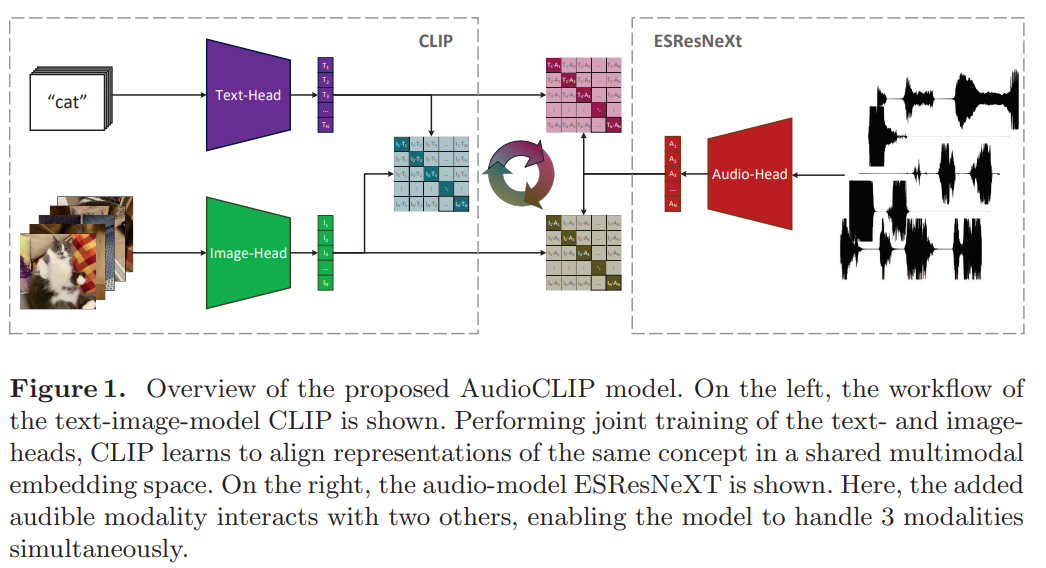
위 그림과 같이 저자들의 model을 표현할 수 있습니다.
CLIP
CLIP은 text encoding head와 image encoding head인 두 subnetwork로 구성됩니다. CLIP model의 각 part는 natural language supervision을 사용하여 동시에 pre-train됩니다. 이러한 학습 방식은 model이 어떠한 추가적인 fine-tuninig 없이 unseen image dataset을 이전에 제공된 label을 가지고 분류할 수 있는 일반화 성능을 갖도록 만들어줍니다.
text encoding 부분의 경우, Transformer architecture를 약간 수정하여 사용합니다. 49,408 크기의 vocabulary를 가진 소문자 byte pair encoding을 사용하여 input text를 표현합니다. 연산량의 한계 때문에, maximum sequence length는 76으로 제한됩니다.
CLIP model의 image encoding 부분의 경우, 두가지 다른 architecture가 가능합니다. 하나는 text-head와 유사한 구조의 Vision Transformer (ViT)입니다. 다른 option은 ResNet-50을 수정한 것입니다. global average pooling layer를 QKV-attention layer로 대체한 ResNet-50입니다. 저자들은 ViT보다 ResNet-50을 사용하는 경우가 연산량이 더 적기 때문에 ResNet-50 기반 CLIP을 구현했다고 합니다.
N 크기의 input batch (text-image pair)가 주어지면, CLIP의 두 subnetwork는 대응하는 embedding을 만들고 둘 다 1024 크기의 multi-modal embedding space로 linear하게 mapping됩니다. 이러한 setup에서, CLIP은 일치하는 textual representation과 visual representation 사이 consine similarity를 maximize하고 다른 경우는 minimize하도록 학습됩니다. similarity에 cross entropy loss를 적용하여 학습됩니다.
ESResNeXt
audio encoding 부분에서, 저자들은 ResNeXt-50 architecture 기반이고 complex frequency B-spline wavelet 기반 time-frequency transformation으로 구성된 ESResNeXt model을 사용합니다. 이 구조는 학습해야 할 parameter 수가 많지는 않으며(30M), 대규모 audio dataset인 AudioSet에서 경쟁력있는 성능을 보여주고 UrbanSound8K나 ESC-50 dataset을 사용한 classification의 경우는 가장 뛰어난 모습을 보여줍니다. 추가적으로 ESResNeXt model은 multi-channel audio input을 암시적으로 처리하고 추가되는 white Gaussian noise나 sample rate 감소와 같은 문제에서는 강건한 모습을 보여줍니다.
Hybrid Model - AudioCLIP
저자들은 새로운 CLIP framework에 audible modality를 추가하여 기존 model을 자연스럽게 확장했습니다. 저자들의 AudioCLIP model은 text-, image-, audio-head라는 세 가지 subnetwork를 통합합니다. text-to-image similarity loss term 외에도 text-to-audio and image-to-audio similarity loss를 추가했습니다. 저자들이 제안한 model은 세 가지 mdoality 뿐만 아니라 이들 중 어느 두 쌍도 처리할 수 있습니다.
Experimental Setup
Datasets
저자들은 5가지 image, audio, mixed dataset을 사용합니다.
- Composite CLIP dataset
CLIP을 학습하기 위해, 만든 새로운 dataset입니다. 약 500k개의 text-based query로 구성된 400M text-image pair data로 구성됩니다. 이 논문에서는 text and image-head (CLIP model)의 weight initializer로써 간접적으로 CLIP dataset을 사용했습니다.
- ImageNet
ImageNet은 1000개 class로 이루어진 1M개 이상의 image로 구성된 dataset입니다. ImageNet은 ESResNeXt model의 weight initializer로 사용되었고, zero-shot inference task의 target으로 사용되었습니다.
- AudioSet
AudioSet dataset은 527개 class로 구성된 대규모 audio dataset입니다. 각 sample들은 최대 10초 길이이며, YouTube-video에서 sample됩니다. 저자들은 audio track뿐만 아니라 video frame도 사용했습니다. 그래서 AudioSet dataset은 vainilla CLIP framework와 저자들의 tri-modal로의 확장을 연결시켜 주는 역할을 할 수 있었습니다. audio track과 그에 맞는 class label은 ESResNeXt model의 image-to-audio trasnfer learning에 사용되었으며, audio와 class에 맞춰 추출된 frame들은 hybrid AudioCLIP model의 input으로 사용되었습니다.
학습할 때, video recording에서 10개의 frame을 추출하고 그 중 하나를 random하게 선택해 AudioCLIP model에 feed했습니다. evaluation을 할 때는 동일한 추출 과정을 진행하되, 중심 frame을 model에 feed했습니다. performance metric은 AudioSet dataset의 evaluation set을 사용하여 측정했습니다.
- Urban Sound8K
UrbanSound8K dataset은 8732개 mono- and binaural-audio track으로 구성되고, sampling rate는 16~48kHz입니다. 각 track은 4초를 넘기지 않습니다. audio recording은 10개 class로 나눠집니다. air conditioner, car horn, children playing, dog bark, drilling, engine idling, gun shot, jackhammer, siren, street music 입니다. 평가 과정의 정확도를 보장하기 위해, UrbanSOund8K dataset은 10개의 non-overlapping fold로 나눠서 사용했습니다.
AudioSet으로 학습된 Audio CLIP의 zero-shot inference를 평가하기 위해 이 dataset을 사용했습니다. 또한 audio encoding head는 UrbanSound8K dataset으로 finetuning을 수행하여 평가를 진행했습니다.
- ESC-50
ESC-50 dataset은 sampling rate가 44.1kHz인 5초 길이의 2000개 single-channel audio로 구성됩니다. 이름에서 알 수 있듯이, dataset은 50개 class로 구성되고, 크게 5개 group으로 나눠질 수 있습니다: animal, natural, water, non-speech human, interior, exterior sound입니다. 평가의 정확성을 보장하기 위해, ESC-50 dataset은 5개 non-overlapping fold로 나누어 사용했습니다.
AudioSet으로 학습된 AUdioCLIP의 zero-shot inference 성능을 평가하기 위해 이 dataset을 사용했습니다. 그리고 audio encoding head는 이 dataset을 이용하여 finetuning 한 다음 평가를 진행했습니다.
Data Augmentation
composite CLIP dataset과 비교했을 때, audio dataset은 2배 정도 training sample이 부족합니다. 특히 UrbanSound8K, ESC-50 dataset이 sample이 부족하며 overfitting을 유발할 수도 있습니다. 이러한 문제를 해결하기 위해 여러 data augmentation technique을 사용했습니다.
- Time Scaling
time axis를 random scaling 하여track duration 뿐만 아니라 ptich도 동시에 변경했습니다. 이러한 augmenatation은 time scretching과 pitch shift라는 연산량이 많이 드는 두 방식을 결합한 방식입니다. 이전 기법들보다 더 빠르며, random factor는 [-1.5, 1.5] 사이로 설정하여 overfitting을 해결할 수 있었습니다.
- Time Inversion
time axis를 따라 track을 inverse 하는 것으로, visual domain에서 널리 사용되는 augmentation technique 중 하나인 image를 random flip 하는 것과 유사합니다. 이 논문에서 random time inversion 확률을 0.5로 설정하여 진행했습니다.
- Random Crop and Padding
model을 통해 처리하기 전에, track duration을 align 해야 하기 때문에, 저자들은 sample에 random cropping이나 padding을 수행하였습니다. 긴 sample들은 random cropping을 진행했으며, 짧은 sample들은 padding을 수행했습니다. evaluation을 수행할 때는, random cropping이 아니라 center cropping을 수행했습니다.
- Random Noise
visual-related task에서 random noise를 추가하는 것은 overfitting을 해결할 수 있도록 도움을 줍니다. 또한 ESResNeXt model의 robustness를 평가할 때, additive white Gaussian noise (AWGN)에 대해 audio encoding model이 상당히 강건하다는 것이 입증되었습니다. 그래서 이 논문에서는 AWGN을 사용하여 data augmentation을 수행합니다. sound-to-noise ratio를 10.0dB ~ 120dB 사이로 random하게 설정했습니다. noise의 확률은 0.25로 설정했다고 합니다.
Training
전체 학습 과정은 subsequence로 나누어 진행했으며, 최종 AudioCLIP이 신뢰성 있고 높은 성능을 보장할 수 있게 만들었습니다. pre-trained ResNet-based CLIP text-image model은 ESResNeXt audio model과 combination되었습니다. ESResNeXt audio model은 ImageNet weight을 사용해 초기화되고, AudioSet dataset으로 pretrain 되어 사용했습니다.
CLIP model이 text-image pair에 대해서는 이미 pre-train되었기 때문에, ESResNeXt model의 성능 향상을 위해 audio-head를 AudioSet에서 먼저 pre-train하기로 결정했습니다. 그다음 두 다른 head를 포함하여 tri-modal setting에서 학습을 수행했습니다.
여기서 전체 AudioCLIP model은 AudioSet의 audio snippet과 그에 대응하는 video frame과 textual label을 사용하여 학습되었습니다. 마지막으로 학습된 AudioCLIP model의 audio-head는 UrbanSound8K와 ESC-50 dataset으로 fine-tune 됩니다. 이때 sound recording과 그에 대응하는 textual label을 사용하여 bimodal (audio and text)로 학습합니다.
학습된 AudioCLIP model과 audio encoding head는 ImageNet dataset 뿐만 아니라 3가지 audio-dataset (AudioSet, UrbanSound8K, ESC-50)을 가지고 평가됩니다.
- Audio-Head Pre-Training
audio head의 parameter는 두 step으로 나누어 초기화됩니다. 먼저, ImageNet-initialized ESResNeXt model을 standalone fashion으로 AudioSet dataset을 활용하여 학습합니다. 그다음 pre-trained audio-head를 AudioCLIP model과 결합하고 text- and image- head의 cooperative supervision을 사용하여 학습하는 방식입니다.
- Standalone
pre-training step은 AudioSet을 이용해 weight initializer로 사용합니다. 저자들은 ESResNeXt model의 학습 시간을 늘려 성능을 향상시켰습니다.
- Cooperative
audio-head의 pre-training은 text- and image- head와 같이 학습됩니다. standalone 상태로 pre-train 된 audio-head의 마지막 classification layer를 random하게 초기화된 다른 layer로 수정했습니다. 해당 layer는 CLIP으 embedding space size와 동일한 output neuron 수를 갖도록 수정했습니다.
이러한 방식으로 audio-head는 AudioCLIP model의 일부분으로 학습되었습니다. 기본 CLIP model의 embedding과 비교할 수 있는 output을 생성할 수 있게 audio-head를 학습시켰습니다. text-head와 image-head의 parameter들은 cooperative pre-training 과정에서는 froze시키며, 두 head는 multi-modal knowledge를 distillation하는 teacher 역할을 수행하게 됩니다.
- AudioCLIP Training
audio-head를 vanilla CLIP model과 동시에 학습되게 만들었지만, AudioSet dataset의 image와 textual description의 분포는 CLIP dataset의 분포와는 다릅니다. 그래서 AudioCLIP model이 target dataset에 대한 성능이 optimal하지는 않으며, downstream task에서도 최적의 성능을 보여주지는 않습니다.
이러한 문제를 해결하기 위해, 저자들은 AudioSet dataset을 이용하여 tri-modal model을 학습하였습니다. 세 가지 modality에 대한 head를 동시에 tuning하여, image와 textual description (video frame과 해당 audio의 AudioSet class를 사용) 분포뿐만 아니라 audio sample의 분포도 동시에 고려하게 만들었습니다.
- Audio-Head Fine-Tuning
학습된 AudioCIP model은 일반화된 multimodal classification, querying ability 성능을 보여줍니다. 하지만 몇몇 condition에서는 domain-specific model을 필요로 하는 경우가 있습니다.
이러한 요구에 맞춰, 저자들은 audio encoding head를 두 target dataset (UrbanSound8K, ESC-50)에 맞춰 tuning하는 실험을 진행했습니다.
- Standalone
audio-head로 사용되는 ESResNeXt model은 강력한 classification 성능을 입증했었습니다. AudioSet으로 pre-training 했기 때문에, UrbanSound8K와 ESC-50 dataset을 사용하여 fine-tune하였으며, 이를 통해 classification accuracy의 변화를 측정했습니다. fine-tuning을 수행할 때, classification layer의 output 수는 downstream task의 target 수에 맞춰 변경했습니다.
- Cooperative
AudioCLIP model을 downstream task에 맞춰 fine-tuning을 수행할 때 audio-head의 parameter만 update되었으며, text- and image-head는 frozen됩니다.
Performance Evaluation
model 성능을 classification과 querying이라는 두 가지 task로 측정했습니다. classification의 경우 audio-head만 사용하거나 AudioCLIP model을 사용한 경우 모두 수행 가능합니다. 하지만 querying은 multimodal network에서만 수행 가능합니다.
- Classification
classification 성능을 평가하는 것은 AudioCLIP model 뿐만 아니라 ESResNeXt인 audio-head로도 수행했습니다. audio-head를 가지고 평가한 경우, target dataset의 수에 맞춰 output을 정하는 방식으로 class label을 바로 예측할 수 있습니다. AudioCLIP model의 경우, textual label로 target을 구성하는 중간 단계를 거쳐 수행합니다.
저자들이 제안한 model의 성능은 AudioSet의 audio and / or image를 input으로 하여 학습된 후 평가되었습니다. UrbanSound8K와 ESC-50 dataset은 두 downstream task를 평가할 때 사용되었습니다: target dataset으로 학습한 후 classification, target dataset으로 학습하지 않고 classification입니다.
- Querying
multimodal 특성과 AudioCLIP의 대칭성 덕분에 다른 modality로 표현되는 asmple의 querying이 가능합니다. classification은 querying의 sub-task로 볼 수도 있습니다. querying은 image 또는 audio를 input으로 받아서 결과를 text로 표현하는 방식이 됩니다. 저자들은 ImageNet, Audioset, UrbanSound8K, ESC-50 dataset을 가지고 학습된 AudioCLIP을 가지고 querying 성능을 평가했습니다.
Results
Classification
- Audio-Head Only
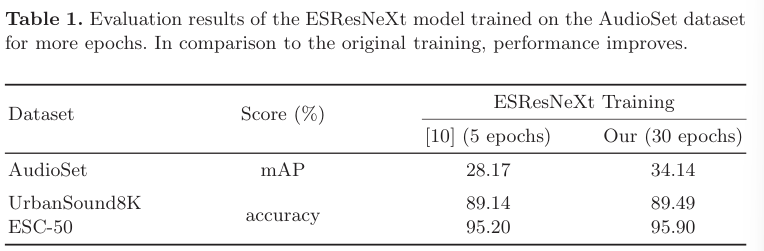
AudioSet dataset으로 확장된 pre-training (5 epoch 대신 30 epoch)을 수행하면 audio encoding head가 original training보다 더 좋은 성능을 보여줍니다 (mAP가 28.17%에서 34.14%로 상승). 이러한 발전은 downstream task에서도 이점을 가져갈 수 있으며, UrbanSound8K와 ESC-50 dataset과 같은 변화에 대해서도 audio-head가 뛰어난 성능을 보여줍니다.
- AudioCLIP
video frame을 사용하는 저자들의 tri-modal training setup은 audio head의 target distribution의 많은 변화가 발생하게 되며, 이를 통해 audio만 사용하는 ESResNeXt model보다 overfitting 문제를 잘 해결하고 더 높은 audio classification 성능을 보여줄 수 있습니다. 또한 모든 세 가지 head를 동시에 학습하는 것은 추가적인 성능 향상을 만들어주고, multiple modality에 대한 classification을 수행할 수 있게 만들어주고, 이전 unseen dataset에 대한 zero-shot inference 성능도 향상시켜줍니다.
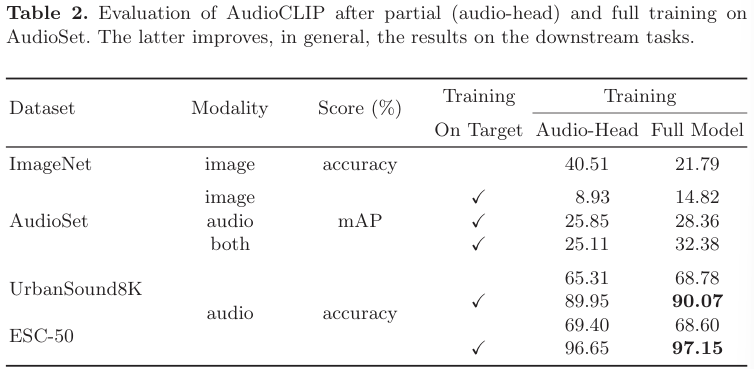
- Partial Training
text- and image-head의 supervision을 가지고 audio-head를 학습하는 것은 이미 현재 존재하는 model보다 더 뛰어난 성능을 보여줍니다(UrbanSound8K, ESC-50 dataset에 대해).
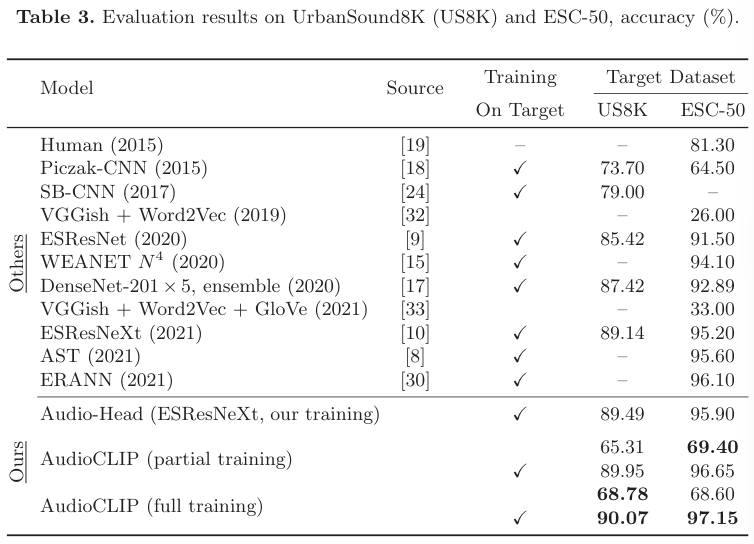
AudioCLIP model을 부분적으로 학습하는 것은 기존 CNN 학습 방법의 zero-shot classification 정확도보다 더 좋은 보여줍니다.
- Full Training
AudioCLIP model의 공동 학습은 부분만 학습하는 것보다 더 뛰어난 성능을 보여줍니다. Full trained AudioCLIP model은 UrbanSound8K와 ESC-50 dataset 모두에서 뛰어난 성능을 보여주며, UrbanSound8K dataset에 대한 zero-shot classification baseline보다도 더 뛰어난 결과를 보여줍니다.
- Querying
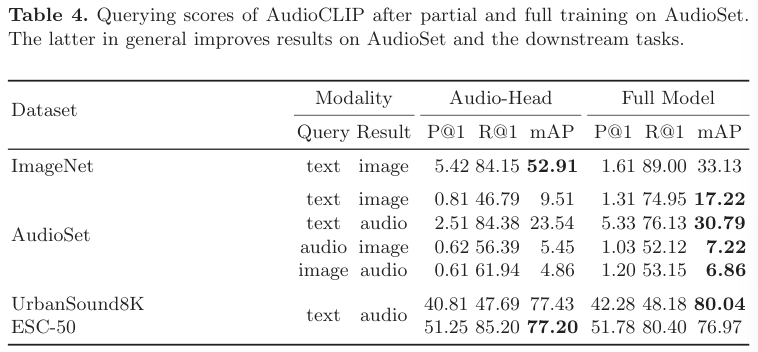
original CLIP model은 text-to-image 또는 image-to-text 모두에서 querying을 수행할 수 있는 능력을 가지고 있습니다. query가 주어졌을 때 (e.g., text), model은 다른 modality (visual)에서 표현되는 sample들의 similarity score를 구합니다. 그러면 dataset과 modality가 주어졌을 때, 선택된 modality로 unique 한 sample을 결정해줍니다. 이 논문에서는 model이 text, image, audio 중 어떠한 combination이어도 querying을 수행할 수 있게 audio modality를 추가했습니다. 저자들은 ImageNet, AudioSet, UrbanSound8K, ESC-50 dataset을 가지고 querying을 수행했으며 결과는 아래와 같습니다.
- Image by Text
target dataset의 smaple들은 class name에 맞춰 unique한 querying result를 만듭니다. ImageNet이나 AudioSet의 image들을 text로 표현해주는 방식입니다. 동일한 label을 가진 visual sample들만 동일한 result를 갖게 됩니다.
Audio dataset을 사용하는 경우, full training을 수행하여 mAP로 측정된 성능 점수를 향상시킬 수 있습니다. 하지만 ImageNet dataset을 이용한 querying 성능은 감소시켰으며, 이는 AudioSet과 ImageNet의 분포가 다르기 때문에 발생합니다.
- Audio by Text
이번에는 audio에 대한 설명을 text로 표현하는 방식입니다. AudioSet과 UrbanSound8K dataset에 대해, full training은 querying 성능을 향상시켜줍니다. ESC-50 dataset의 경우에는 성능 향상이 일어나지는 않지만, gap 차이가 크지는 않습니다.
- Audio by Image and Vice Versa
audio by image, image by audio에 대한 query 결과입니다. AudioCLIP model을 full training하는 것이 querying performance의 향상을 이끌어줍니다(mAP).
Conclusion
이 논문에서 확장된 CLIP model을 제안합니다. txtual and visual modality였던 CLIP에 sound classification model을 효율적으로 사용하여 audio까지 확장시켰습니다.
저자들이 제안한 AudioCLIP model은 UrbanSound8K와 ESC-50 dataset의 classification 정확도가 현존하는 model들 중 가장 뛰어난 모습을 보입니다. 추가적으로 zero-shot inference의 경우, 저자들의 model은 이전 방식들의 ESC-50 dataset에 대한 성능보다 큰 격차로 성능을 향상시켰습니다. 그리고 저자들은 model을 부분적으로 학습하거나 full train하여 classification과 cross-modal querying task에서의 성능을 보였습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] CLAP: Learning Audio Concepts from Natural Language Supervision (0) | 2024.06.27 |
|---|---|
| [논문] Soundify: Matching Sound Effect to Video (0) | 2024.06.24 |
| [논문] AudioLDM: Text-to-Audio Generation with Latent Diffusion Models (0) | 2024.06.22 |
| [논문] Generating Realistic Images from In-the-wild Sounds (0) | 2024.06.20 |
| [논문] What Do I Hear? Generating Sounds for Visual with ChatGPT (0) | 2024.06.19 |



