https://arxiv.org/abs/2309.09470
Face-Driven Zero-Shot Voice Conversion with Memory-based Face-Voice Alignment
This paper presents a novel task, zero-shot voice conversion based on face images (zero-shot FaceVC), which aims at converting the voice characteristics of an utterance from any source speaker to a newly coming target speaker, solely relying on a single fa
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
이 논문은 face image를 기반으로 하는 zero-shot voice conversion을 수행하는 새로운 task (zero-shot FaceVC)를 제안합니다. 이는 source speaker가 녹음한 utterance의 voice characteristic을 새로운 target speaker로 변환하는 것을 목표로 하며, 이때 target speaker의 face image만 사용하여 수행합니다. 이 task를 수행하기 위해, 저자들은 face-voice memory based zero-shot FaceVC method를 제안합니다. 이는 memory-based face-voice alignment module을 사용하며, 이는 두 modality의 align을 수행하는 bridge 역할을 하며 face image로부터 voice characteristic을 capture 하는 것을 수행할 수 있게 합니다. speaker-independent content-related representation을 얻기 위해, 저자들은 pre-trained zero-shot voice conversion model을 사용하여 저자들의 zero-shot FaceVC model에 knowledge를 transfer 합니다.
Introduction
이 논문은 face image를 기반으로 zero-shot voice conversion을 수행하는 새로운 VC task인 (zero-shot FaceVC)를 제안합니다. 이 task는 unseen target speaker의 single face image를 어떠한 source speaker의 utterance로 변환하는 작업을 수행합니다. 이 task의 목적은 facial property가 voice characteristic의 지표로 어디까지 나타낼 수 있는 지를 탐구하는 것입니다. 만약 unseen speaker의 face image로부터 적절한 voice characteristic을 추론하는 것이 용이하다면, zero-shot FaceVC는 다양한 application에 잠재력을 갖게 됩니다.
저자들이 알기론, face image를 기반으로 하는 voice converison (FaceVC) 연구 2가지가 존재합니다. 두 연구는 source and target speaker 모두 training set에서 등장했던 many-to-many FaceVC task를 연구하지만, 이 논문에서는 zero-shot scenario를 고려한다는 차이가 있습니다. 이 중 한 연구는 original VC model에 사용되는 speaker embedding을 face embedding으로 대체했었습니다. 또 다른 연구는 face-voice reparameterization, facial-to-audio transformation을 포함하는 3가지 학습 전략을 사용하여 성능을 향상시켰었습니다.
FaceVC의 가장 큰 어려움 중 하나는 face-voice alignment이며, 이는 주어진 face representation으로 voice representation을 구하는 것에 대한 어려움을 의미합니다. 이전 연구들은 face representation이 mel-spectrum reconstruction의 supervision을 이용하거나, speaker embedding과 face embedding 사이 MSE를 minimize 하는 방식으로 최적화를 수행했었습니다. mel-spectrum reconstruction을 사용하는 방식은 target speaker의 recording을 사용할 수 없기 때문에 zero-shot FaceVC에 적용할 수 없습니다(zero-shot 이니까). 간단한 MSE를 사용하는 방식은 face representation에서 얻은 voice representation의 분포가 unimodal이라는 가정 하에 진행되는 방식입니다. 두 방식 모두 voice space와 face space의 복잡한 mapping을 설명하는 데 어려움을 겪었으며, zero-shot FaceVC task를 수행하기엔 완벽하지 않았습니다.
그래서 이 논문에서 face-voice memory-based zero-shot FaceVC (FVMVC) method를 제안합니다. 이 method는 memory-based face-voice alignment (MFVA) module을 사용합니다. MFVA module은 face space와 voice space 사이 common characteristic을 양자화하기 위해 학습 가능한 slot을 사용합니다. 학습할 때, MFCA의 slot value는 speaker embedding reconstruction loss를 minimize하는 방식으로 최적화될 뿐만 아니라, face space와 voice space의 slot weight 분포 사이 Kullback-Leibler divergence를 줄이는 방식으로 최적화됩니다. inference 할 땐 unseen target speaker의 face image가 주어지면, reference image로 slot weight를 구하고 voice space의 slot value로 speaker embedding을 계산합니다.
추가적으로 Zero-shot VC는 주로 training phase와 inference phase 사이 inconsistency 문제를 겪는 auto-encoder framework를 사용합니다. 더 구체적으로, 학습 과정에서는 speaker representation과 content representation가 동일한 speaker에서 구해지지만, conversion stage에서는 서로 다른 speaker에서 구해집니다. 이 문제를 해결하여 zero-shot FaceVC를 수행하기 위해서, 저자들이 mixed supervision strategy를 제안하며, 이는 기존 auto-encoder framework의 intra speaker supervision 뿐만 아니라 inter-speaker supervision을 사용하는 간단하지만 효과적인 방식입니다. training set에서 다른 speaker가 녹음한 recording으로부터 추출된 speaker embedding을 사용하여 pseudo-parallel training data를 생성함으로써 inter-speaker supervision을 만들어냅니다. 그리고 speaker-independent content representation을 얻기 위해, 저자들은 초기에 zero-shot VC model을 pretrain 하고, zero-shot VC로 zero-shot FaceVC에 knowledge를 transfer 합니다.
face image만 사용하여 target speaker의 정확한 voice를 recover한느 것은 불가능합니다. 대신 저자들은 zero-shot FaceVC에 의해 생성된 speech의 3가지 특성에 focus 했습니다. 먼저, 동일한 target speaker의 다른 어굴을 사용하여 변환된 voice characteristic 사이 동질성입니다. 두 번째, 다른 target speaker의 face image를 사용하여 변환된 voice characteristic의 다양성입니다. 세 번째, 변환된 utterance의 voice characteristic과 그에 대응하는 face image의 일관성입니다 (e.g., 성별). 그러므로 이 논문에서 사용한 여러 subjective and objective metric들은 위에서 언급한 관점에서 평가를 수행합니다.
Related Work
Learning Voice-Face Association
최근 몇 년 동안, voice-face association을 학습하는 것은 주목받는 연구 주제였습니다. face와 voice가 내제적으로 연관되어 있기 때문에, face와 voice 둘 다 포함하고 있는 다양한 cross-modal generation task들이 제안되었으며, face image로 voice conversion을 수행하는 연구도 등장했습니다.
face image 기반 voice conversion과 가장 관련된 task는 FaceTTS이며, 이는 voice characteristic을 control 하기 위해 speaker identity를 추출하도록 face image를 사용합니다. Fast2Speech는 FaceTTS를 수행하는 첫 논문이며, supervisedly generalized end-to-end (GE2E) loss로 face encoder를 pre-train하고, multi-speaker TTS model의 speaker encoder를 face encoder로 대체하여 수행합니다. Face2 Speech framework에 맞춰, 더 정교한 model 구조와 학습 방법들이 등장했으며, 이를 통해 합성된 speech의 quality를 향상시켰습니다. 하지만 FaceTTS의 voice-face alignment는 여전히 연구 주제로 남아있습니다. 이 논문에서 정교하게 memory-based module을 design 하여 두 modality의 alignment를 수행하는 zero-shot FaceVC를 제안합니다.
Method

위 그림과 같이, 저자들의 FVMVC는 standard auto-encoder paradigm을 따르며, content encoder, speaker encoder, face encoder, pitch extractor, decoder, memory based face-voice alignment (MFVA) module로 구성됩니다.
inference 할 때, 저자들의 FVMVC는 target speaker의 face image와 source speaker의 전환될 utterance의 waveform, mel-spectrogram을 input으로 받습니다(3가지 input). face encoder와 MFVA module을 순차적으로 사용하여 face image를 처리함으로써, face image를 기반으로 하는 voice characteristic representation (i.e., the recalled face embedding)을 얻을 수 있게 됩니다. zero-shot VC와 유사하게, source speaker의 mel-spectrogram은 speaker-independent content representation을 제공해주고, waveform은 normalized fundamental frequency를 추출하는 데 사용됩니다. 위에서 말한 모든 representation은 decoder에 전달되고 converted utterance의 mel-spectrogram을 생성합니다. 이 mel-spectrogram은 vocoder를 사용하여 waveform으로 변환됩니다. 학습 과정에서, 저자들은 mel-spectrogram과 speaker encoder를 사용하여 추출된 speaker embedding을 사용하여 MFVA module의 학습을 supervise 하는 데 사용합니다.
Memory-based Face-Voice Alignment
face와 voice 사이 alignment는 face image만 가지고도 대응하는 speaker embedding을 검색할 수 있게 만들어 줍니다. face image로 검색된 speaker embedding은 recalled face embedding으로 사용됩니다. 저자들은 MFVA module을 사용하여 voice-face alignment modelling을 향상시키고, 이를 통해 zero-shot FaceVC의 성능을 향상시킵니다.

위 그림과 같이 학습 과정에서 MFVA module은 face embedding h ∈ R^{D}과 speaker embedding s ∈ R^{D} pair를 input으로 받고 recalled face embedding h^ ∈ R^{D}을 생성하여 voice를 control 합니다. face embedding h와 speaker embedding s는 face encoder와 speaker encoder로 추출되며, D는 projected face or speech embedding의 차원을 의미합니다. MFVA는 voice-value memory M_{voice} = [m_v^1, ... , m_v^N]T ∈ R^{N x D}와 face-key memory M_{face} = [m_f^1, ... , m_f^N]T ∈ R^{N x D}로 구성되며, N은 slot의 수를 나타내고, D는 각 slot의 차원을 의미하며, D는 projected speaker embedding의 차원과 동일합니다. MFVA module train은 두 가지 목적을 갖습니다. 1) voice-value memory에 충분한 voice characteristic information을 저장, 2) 두 modality의 분포 사이 distance를 minimize 하기, 입니다.
- The sufficiency of the voice characteristics information
Voice-value memory M_{voice}는 학습 가능한 slot의 bank를 만들어 줍니다. voice-value memory는 voice-related information만 capture 하고 어떠한 voice도 생성할 수 있습니다. 구체적으로, speaker embedding을 query로 받았을 때, query와 각 slot의 attention weight는 cosine similarity와 softmax normalization function을 통해 구해집니다.

w_{v}^{i}는 i-th slot인 m_{v}^{i}와 speaker embedding s 사이 relevance의 정도를 의미합니다. 그다음 모든 slot에 대해 attention weight를 계산함으로써 weight vector w_{voice}를 구할 수 있습니다. 마지막으로 저자들은 모든 slot으로부터 speaker embedding을 reconstruct 합니다.

input speaker embedding s와 recalled speaker embedding s^ 사이 MSE를 minimize 하도록 학습됩니다.
voice-value memory에 있는 slot들은 voice characteristic space를 생성하는 basis로 사용될 수 있으며, slot의 다양한 combination은 임의의 voice를 표현할 수 있습니다.
- The alignment between voice and face space
저자들은 slot을 face embedding을 voice space로 mapping 하는 streamed bridge로 사용합니다. 구체적으로 face embedding h가 주어지면, recalled speaker embedding 처럼 recalled face embedding h^을 생성합니다. 이때 attention weight는 face key memory M_{face}로 계산되며, voice-value memory M_{voice}의 slot과 정렬됩니다.

m_f^i ∈ R^D는 face-key memory M_{face}의 i-th 학습 가능한 slot을 의미합니다. 따라서, voice와 관련된 slot을 결합하여 recalled face embedding h^를 생성합니다. 그리고 face image는 사진을 찍는 각도나 image bacground와 같은 다양한 background noise를 포함하거나 voice와 관련 없는 정보를 포함하기도 합니다. Voice-value memory M_{voice}는 이러한 필요 없는 detail을 제거하기 위해 information bottleneck을 수행할 수도 있습니다. 최종적으로 Kullback-Leibler divergence를 사용하여 두 modality의 slot-weight distribution을 align 합니다.

이러한 방식으로 inference 할 때, face embedding만 input으로 주어지면 voice characteristics information을 support 하기 위해 합리적인 recalled face embedding을 생성하여 zero-shot FaceVC를 수행합니다.
Structures of Other Modules
- Content Encoder
content encoder는 contrastive predictive coding (CPC)를 사용하는 방식으로 vector quantization (VQ)을 수행했으며, VQ는 mel-spectrogram으로 content embedding을 추출합니다. VQ는 불필요한 content information을 제거하기 위해 information bottleneck으로 사용될 수 있으며, speech의 local structure를 explore 하기 위해 CPC를 사용될 수 있습니다.
- Face Encoder
face image에서 face embedding을 추출하기 위해 face encoder를 사용합니다. 먼저 MTCNN을 사용하여 original face image에서 face를 detection 합니다. 그다음 pretrained FaceNet에 self-attention module을 적용하여 facial feature를 추출하여 face embedding으로 사용합니다. zero-shot FaceVC 학습 과정에서, self-attention module만 다른 module들과 학습을 수행합니다.
- Speaker Encoder
Speaker encoder는 mel-spectrogram을 받아 길이가 고정된 speaker embedding을 생성합니다. speaker encoder는 2가지 part로 구성됩니다: Resemblyzer와 self-attention module입니다. Resemblyzer는 GE2E loss function으로 speaker verification task에서 pretrain 됩니다. pretrained speaker verification network를 zero-shot VC network에 잘 적용하기 위해, 저자들은 pretrained speaker verification network에 self-attention module을 사용했으며, zero-shot VC 학습 과정에서 동시에 학습됩니다.
- Pitch Extractor
Pitch extractor는 input waveform에서 fundamental frequency를 추출합니다. 이때 vocal fold vibration의 주기를 탐지하고 각 utterance에 z-normalization을 적용하는 방식으로 수행합니다.
- Decoder
decoder는 content representation, speaker-identity representation, pitch representation을 mel-spectrogram으로 mapping 합니다. decoder는 주로 convolutional block과 2개 long short-term memory (LSTM) layer로 구성됩니다.
Mixed Supervision Strategy
mixed supervision strategy는 intra-speaker supervision과 inter-speaker supervision을 포함합니다. 학습 과정에서, speaker A의 input utterance의 mel-spectrogram X_A를 speaker-independent content embedding c_A, normalized fundamental frequency f_A와 고정된 길이의 speaker embedding s_A로 encode 합니다. 동시에 얼굴 image Z_A를 사용하여 face embedding h_A를 얻습니다. 그다음 face embedding h_A와 speaker embedding s_A를 MFVA moduel에 feed 하여 recalled face embedding h_A^를 얻습니다. 최종 decoder D는 위 representation들을 reconstruct mel-spectrogram X_A^ = D(c_A, h_A^, f_A)로 mapping 합니다. reconstruction loss를 minimize 하는 방식으로 decoder, MFVA, face encoder의 self-attention module을 동시에 학습합니다.

하지만, intra-speaker supervision만 사용했을 때 train-inference 비일관성 현상이 발생하는데, 학습 과정에서 content embedding과 recalled face embedding은 동일한 speaker에서 얻어지지만 inference 할 때는 다르기 때문입니다. 저자들은 간단하지만 효율적인 inter-speaker supervision strategy를 제안합니다. 이 방식은 target speaker embedding으로 변환되는 voice를 supervised training을 위해 face embedding의 pseudo-parallel corpus로 사용합니다. 구체적으로 다음 부분입니다.

위 그림처럼 speaker A 외에도, extra speaker B의 face image와 mel-spectrogram pair를 input으로 사용하여 speaker embedding s_B와 recalled face embedding h_B^을 얻는 모습입니다. speaker A는 source speaker로 다뤄지고, speaker B는 target speaker가 됩니다.

X_{speech}는 speaker embedding s_B에 의해 변환된 mel-spectrogram을 나타내고, X_{face}는 recalled face embeding h_B^을 사용하여 얻어지는 변환된 mel-spectrogram을 나타냅니다. 그다음 reconstruction loss를 minimize 하는 방식으로 MFVA를 optimize 합니다.

zero-shot FaceVC의 학습 과정에서 사용되는 final loss function은 다음과 같습니다.
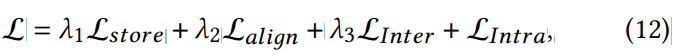
위 식에서 λ들은 각 term들의 중요도를 control 하는 weight를 나타냅니다.
Pretraining Strategy
content encoder가 speaker identity와 관련된 information도 encode 할 수도 있습니다. speaker representation과 content representation이 분리되었을 때만 speaker-identity representation을 변경하여 utterance의 voice characteristic을 변환할 수 있습니다. speech representation disentanglement는 zero-shot FaceVC의 성능에 상당히 중요한 역할을 합니다. 그래서 저자들은 zero-shot VC model을 pretrain 한 다음 content encoder, speaker encoder, decoder를 zero-shto FaceVC에 적용하여 성능을 향상시킵니다. 구체적으로 zero-shot FaceVC를 학습할 때, pretrained content encoder와 pretrained speaker encoder는 고정되지만, pretrained decoder는 추가적인 학습을 진행합니다.
speech representation을 분리하기 위해, 다른 representation 사이 의존성을 평가하는 mutual information (MI)를 사용합니다. 저자들은 content embedding, speaker embedding과 fundamental frequency 사이 MI를 minimize 합니다.
Experiments
Datasets
Zero-shot FaceVC task는 다양한 speaker로부터 얻어진 대규모 background-noise-free speech 뿐만 아니라 speaker의 clear face image를 필요로 합니다. 이러한 것을 고려하여, 저자들은 LRS3-TED dataset을 사용하여 zero-shot FaceVC task를 평가했습니다. 이 dataset은 5594개 TED & TEDx 영어 대화를 포함하며, 총 400시간 video content입니다. video에 있는 crop 된 face image는 224 x 224 resolution입니다. audio track은 single-channel 16-bit 16kHz format입니다.
Implementation Details
acoustic feature를 추출하기 위해, 저자들은 FFmpeg tool을 사용하여 video clip에서 audio를 추출했습니다. 그다음 80-dim mel-spectrogram과 normalized fundamental frequency을 계산했습니다. MTCNN와 FaceNet을 순차적으로 사용해서 video의 각 frame에서 512차원 face embedding을 추출했습니다. face embedding의 차원을 256으로 project 하였으며, 이는 speaker embedding의 차원과 같고, slot의 차원과도 동일한 크기입니다. MFVA의 slot 수는 96으로 설정했습니다. 저자들은 pretrained Parallel WaveGAN (PWG)을 vocoder로 사용했으며, 이 vocoder로 mel-spectrogram을 waveform으로 변환했습니다.
Comparison systems
저자들이 처음으로 zero-shot FaceVC task를 수행하기 때문에 비교할 method가 존재하지 않았으며, 저자들은 다음 system을 사용해 평가를 수행했습니다.
- Ground Truth
pretrained PWG vocoder를 사용하여 target speaker의 natural mel-spectrogram을 waveform으로 변환했습니다. source speaker와 target speaker에 parallel utterance가 존재하지 않기 때문에, groudn truth result는 converted rsult와 바로 비교할 순 없으며, 다양한 metric의 upperbound로 사용했습니다.
- SpeechVC
target speaker의 reference utterance를 사용하는 zero-shot VC model입니다.
- Auto-FaceVC
이 method는 AutoVC의 backbone을 사용합니다. zero-shot FaceVC task를 더 잘 수행하도록, 저자들은 AutoVC의 backbone을 VQMIVC로 변경했습니다.
- attentionCVAE
이는 multi-speaker TTS task인데, voice characteristic을 control 하기 위해 face attribute를 사용하는 method입니다. 이 method를 zero-shot FaceVC task에 사용하기 위해, face encoder와 MFVA module의 대체로 face attributes-based voice control module을 사용했습니다.
Metrics
저자들은 변환된 voice의 동질성, 다양성, 일관성을 평가하기 위해 여러 objective metric을 사용했습니다. zero-shot FaceVC system은 동일한 target speaker의 다른 face image라면, image의 각도나 background에 상관없이 일관성 있는 voice characteristic을 생성해야만 하기 때문에, 동질성을 평가하였습니다. 저자들은 잘 알려진 open-source speaker verification toolkit인 Resemblyzer를 사용했습니다. 동일한 speaker의 변환된 utterance로부터 speaker embedding을 추출하여 cosine similarity를 구하는 방식입니다. cosine similarity 값이 클수록 다른 utterance에 대한 동질성이 크다는 것을 의미합니다. 저자들은 동일한 target speaker의 다른 face image를 사용하여 변환된 utterance를 random 하게 match 하여 사용했습니다. 발화를 500번 섞고, 모든 pair의 average cosine similarity를 구해 speaker homogeneity score by random matching (SHR)로 사용했습니다. 추가적으로 one-to-one matching을 수행했습니다. speaker homogeneity score by one-to-one matching (SHO)로 사용했습니다.
동질성 외에도, 다른 target speaker로부터 변환된 voice characteristic은 다양해야 합니다. 동질성과 유사하게, 저자들은 동일한 source speaker에서 서로 다른 target speaker의 face image를 사용하여 변환을 수행했습니다. 변환된 두 speaker embedding 사이 cosine similarity가 낮을수록 target speaker 간의 voice characteristic의 다양성이 높다고 가정했습니다. 동일한 source speaker에서 다른 target speaker로 변환한 utterance를 random 하게 match 하여 평균 cosine simiarity를 구했으며, 이를 speaker diversity score by random matching (SDR)로 사용했습니다. 그리고 one-to-one matching도 수행했으며, 이를 speaker diversity score by one-to-one matching (SDO)로 사용했습니다.
voice characteristic과 그에 대응하는 face image 사이 일관성을 평가할 때 성별은 주요한 요소입니다. 저자들은 open source speech segment toolkit인 inaSpeechSegmenter를 사용하여 각 변환된 utterance의 gender accuracy (GA)를 구했습니다. 구체적으로 먼저 speech segmenter를 사용하여 speech가 없는 segment를 제거했습니다. 그다음 남아있는 speech segment를 convolutional neural network를 사용해 남성과 여성으로 분류했습니다. 만약 변환된 utterance에 있는 모든 speech segment가 target speaeker의 gender로 잘 분류된다면, 변환된 utterance의 성별은 target speaker와 일관성 있다고 봤습니다.
주관적인 평가를 위해, 저자들은 face-voice consistent degree (MOS-FVC) score와 speech naturalness (MOS-SN) score를 사용했습니다. MOS-FVC는 face image와 voice characteristic이 서로 일관성 있는지 평가하기 위해 사용되었습니다. MOS-SN은 변환된 voice의 자연스러움을 평가하기 위해 사용되었습니다.
Evaluation Results
저자들은 각 4명 source speaker의 6개 utterance를 선택하여 사용했습니다.

위 표는 objective and subjective evaluation 결과를 보여줍니다. 저자들이 제안한 FVMVC가 Auto-FaceVC와 attentionCVAE system보다 objective metric에서 훨씬 뛰어난 모습을 보입니다. 추가적으로, 저자들의 FVMVC는 over-smotthing 문제를 완화하기 위해 MFVA module을 사용했으며, 더 다양한 voice characteristic을 만들 수 있게 되었습니다.
저자들의 FVMVC가 SHR과 SHO에서 SpeechVC보다 더 뛰어난 성능을 보여줍니다. 이는 face iamge에 안정적인 identity information이 존재하고, natural reference speech에는 prosody나 emotion과 같은 여러 speaker independent factor가 포함되어 있기 때문입니다.
Conclusion
이 논문에서 저자들의 FVMVC model은 zero-shot FaceVC를 다룹니다. MFVA module에 있는 slot은 face와 voice 사이 link 역할을 하며 unseen speaker의 face image를 기반으로 voice를 control 하는 성능을 향상시켜 줍니다. 그리고 mixed supervision strategy를 사용하여 VC task의 학습과 추론 사이의 inconsistency라는 오래된 문제를 완화시킵니다. 결과적으로 새로운 speaker의 face image를 기반으로 하는 FVMVC가 더 일관성 있고 다양한 voice를 생성할 수 있게 됩니다.



