https://arxiv.org/abs/2306.17203
Diff-Foley: Synchronized Video-to-Audio Synthesis with Latent Diffusion Models
The Video-to-Audio (V2A) model has recently gained attention for its practical application in generating audio directly from silent videos, particularly in video/film production. However, previous methods in V2A have limited generation quality in terms of
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
최근 Video-to-Audio (V2A) model들은 silent video에서 바로 audio를 생성하는 실용적인 application program으로 많은 주목을 받고 있습니다. 하지만, 이전 V2A model들은 temporal synchronization과 audio-visual relevance 관점에 제한된 generation quality를 보여주고 있었습니다. 저자들은 DIFF-FOLEY라는 latent diffusion model (LDM)을 사용하는 synchronized Video-to-Audio synthesis method를 제안합니다. 이는 audio-visual relevance를 잘 나타내고 향상된 synchronization을 보여주는 고품질 audio를 생성합니다. 저자들은 contrastive audio-visual pretraining (CAVP)를 사용하여 시간적으로, 의미적으로 align 된 feature를 학습하고, spectrogram latent space에서 LDM을 학습합니다. CAVP-aligned feature는 LDM이 cross-attention module을 통해 미묘한 audio-visual correlation을 capture 할 수 있게 만듭니다. 저자들은 double guidance를 사용하여 sample quality를 상당히 향상시켰습니다.
Introduction
이 논문은 video/film production에 유용한 application인 Video-to-Audio (V2A) generation에 focus를 맞춥니다. live 촬영에서는 과도한 background noise와 복잡한 상황에서의 audio collection의 어려움으로 인해, 영화에 녹음된 대부분의 소리는 post-production 과정에서 recreation 됩니다. video에 동기화되고 사실 같은 sound effect를 video에 더하는 과정을 Foley라고 합니다. studio에서 진행되는 전통적인 Foley와 저자들의 neural Foley를 비교하면 다음과 같이 그릴 수 있습니다.
전통적인 Foley는 숙련된 artist가 물체를 조작하여 수 시간 동안 진짜 같은 물리적 소리를 생성하는 노동 집약적이고 시간 소모적인 과정입니다. AI로 생성된 high-quality synchronized audio는 video production 시간을 단축시킬 수 있고 인간의 작업 부담을 덜어줄 수 있기 때문에, neural Foley가 매력적인 대안책이 될 수 있습니다. text script와 video frame을 가지고 speech를 합성하는 Neural Dubber와 다르게, Neural Foley는 video content만 가지고 다양한 범위의 audio를 생성하는 데 중점을 두고 있으며, 이는 훨씬 더 높은 난이도의 task입니다.
Foley를 수행할 때, Video-based audio generation은 자연스럽게 text-based generation에 비해 2가지 이점이 존재하게 됩니다. 먼저, T2A는 학습을 위해 모으기 힘든 많은 양의 text-audio pair가 필요로 하지만, audio-video pair는 이미 인터넷에 많이 존재합니다. 둘째로 V2A는 Foley audio와 video의 시간적 synchronization을 더 잘 control 할 수 있습니다.
semantic content matching과 시간적 synchronization은 V2A의 2가지 주요 목표입니다. 최근 몇몇 연구들에서 V2A에 대한 일부 발전이 있었지만, 대부분의 audio generation method들은 content relevnace에 focus를 맞추고 audio-visual synchronization 측면을 간과합니다. 예를 들어 drum 연주 video가 주어졌을 때, method들은 drum sound를 생성할 수 있지만 생성된 sound가 video에서 일어나는 일과 정확히 일치한다는 것을 보장하지 못합니다. 즉, 스네어 드럼이나 crash 심벌을 정확한 시간에 치는 소리를 생성하지 못합니다.
RegNet은 pre-trained (RGB+Flow) network가 추출한 feature를 GAN의 conditional input으로 사용하여 sound를 합성합니다. 반면에 SpecVQGAN은 pretrained ResNet50 or (RGB+Flow) visual feature를 condition으로 사용하는 autoregressive Transformer model을 사용하여 더 나은 sample quality를 보여주기도 합니다. 이러한 method들은 pre-trained image and flow feature들이 audio와 video 사이 미묘한 correlation을 capture 할 수 없기 때문에 생성된 audio들은 sync나 relevant에 한계가 존재합니다.
저자들은 새로운 Neural Foley framework인 DIFF-FOLEY를 제안하며, 이는 강력한 audio-visual relevance를 나타내는 realistic and synchronized audio를 합성하는 Latent Diffusion Model (LDM) 기반 model입니다. DIFF-FOLEY는 CAVP를 통해 시간적으로, 의미적으로 align 되는 feature를 먼저 학습합니다. 동일한 video의 visual feature와 audio feature 사이 유사도를 최대화함으로써 세밀한 audio-visual 연결을 capture 할 수 있습니다. 그 다음 CAVP visual feature를 condition으로 하는 LDM을 spectral latent space에서 학습합니다. CAVP의 align된 visual feature는 LDM이 audio-visual relationship을 capture할 수 있도록 도와줍니다. quality를 더 향상시키기 위해, reverse process를 guide 하기 위해 classifier-free & alignment classifier guidance를 동시에 사용하는 'double guidance'를 제안합니다. DIFF-FOLEY는 VGGSound라는 large-scale V2A dataset에서 가장 좋은 성능을 달성했으며, 다른 baseline보다 훨씬 뛰어난 성능을 보여줍니다.
Related Work
Video-to-Audio Generation
video production에서 silent video로 audio를 생성하는 것은 상당한 잠재력을 보여주며, V2A model이 post-production을 효율적으로 향상시킬 수 있습니다. 최근 발전에도 불구하고, open-domain V2A는 여전히 어려운 과제로 남아있습니다. RegNet은 pre-trained (RGB+Flow) network를 사용하여 video feature를 추출하고 GAN의 condition input으로 사용해 sound를 합성합니다. SpecVQGAN은 더 powerful 한 Transformer-based autoregressive model을 사용하여 ResNet50이나 RGB+Flow에서 추출된 feature를 가지고 sound를 합성합니다. 가장 좋은 성능을 보이고 있는 Im2Wav은 CLIP feature를 condition으로 사용하는 2개 transformer model을 사용하지만, 수천번의 inference step을 사용하기 때문에 inference speed가 느리다는 문제가 존재합니다. 현재 존재하는 V2A method는 pre-trained visual feature에 audio-related information이 부족하여 synchronization에 어려움을 겪고 있으며 내재된 audio-visual correlation을 capture 하는데 한계가 존재합니다.
Contrastive Pretraining
Contrastive pretraining은 다양한 생성 task에서 잠재력을 보여주고 있습니다. CLIP은 contrastive pretraining을 사용하여 text-image representation을 align 합니다. Text-to-Image의 경우, CLIP과 Stable Diffusion을 사용하여 text prompt feature를 추출하고 사실 같은 image generation을 수행합니다. Text-to-Audio의 경우, CLAP은 text representation과 audio representation의 align 하고, 최종 audio feature를 AudioLDM에 사용하기도 합니다. multimodal generation에서 modality alignment의 중요성을 인식하여, 저자들은 contrastive audio-visual pretraining (CAVP)이 temporally and semantically aligned feature를 학습하도록 만든 후 generation task에 사용합니다.
Latent Diffusion Model
Diffusion Model은 image generation, audio generation, video generation과 같은 다양한 generation task에서 눈에 띄는 성공을 보여주고 있습니다. Stable Diffusion (SD)와 같은 Latent diffusion model은 data latent space에서 forward pass와 reverse pass를 수행하여 효율적인 연산과 가속된 inference를 제공합니다.
Method
DIFF-FOLEY는 two stage로 구성됩니다: Stage 1 CAVP, Stage 2 LDM training. 저자들의 model은 다음과 같습니다.

video에 있는 audio와 visual component는 강한 상관관계와 상호 보완성을 나타냅니다. 불행하게도 존재하는 image or optical flow backbones (ResNet, CLIP, etc.)은 audio와 visual 사이 강한 alignment를 반영하기에 어려움을 겪습니다. 이를 해결하기 위해, 저자들은 audio-visual feature를 align 한 outset을 만드는 Contrastive Audio-Visual Pretraining (CAVP)를 제안합니다. 그다음 CAVP-aligned visual feature를 condition으로 하는 LDM을 spectral latent space에서 학습을 수행합니다.
Contrastive Audio-Visual Pretraining
x_a ∈ R^{T' x M}은 M mel basis, T'은 time axis를 나타내는 Mel-Spec이고 x_v ∈ R^{T'' x 3 x H x W}는 video clip의 T''개 frame인 audio-video pair (x_a, x_v)가 주어졌다고 하겠습니다. audio encoder f_A()는 audio feature E_a ∈ R^{T x C}를 추출하고 video encoder f_V()는 video feature E_v ∈ R^{T x C}를 추출하며, 각 feature는 동일한 temporal dim T를 갖습니다. 저자들은 PANNs를 기반으로 audio encoder를 구현하며, SlowOnly architecture를 사용하여 video encoder를 구현했습니다. temporal pooling layer P()를 사용하여 저자들은 temporal-pooled audio/video features \hat{E_a} = P(E_a) ∈ R^C, \hat{E_v} = P(E_v) ∈ R^C를 얻습니다. CLIP의 contrastive objective와 유사한 objective를 사용하여 \hat{E_a}와 \hat{E_v}를 contrast 합니다. audio-video feature의 semantic and temporal alignment를 향상시키기 위해, 저자들은 Semantic contrast L_S와 Temporal contrast L_T를 사용합니다.
L_S의 경우, 저자들은 동일한 video의 audio-visual pair의 similarity를 maximize 하고, 다른 video의 audio-visual pair의 similarity는 minimize 합니다. 이를 통해 다른 video 간의 audio-visual pair의 semantic alignment를 학습하도록 만들어줍니다. 구체적으로 N_S개의 다른 video에서 audio-visual feature pair를 추출하여 B_S = {(\hat{E_a^i}, \hat{E_v^i}}_{i=1}^{N_S}를 얻었다고 하겠습니다. 각 sample pair의 semantic contrastive objective L_S^{(i, j)}를 정의하면 다음과 같습니다.

위 식에서 sim()은 cosine similarity를 나타냅니다.
L_T의 경우, 저자들은 동일한 video에 있는 다른 시간대의 video clip들을 sample 합니다. same time segment의 audio-visual pair의 similarity를 maximize 하고 다른 time segment 간의 audio-visual pair의 similarity는 minimize 하는 것을 목표로 합니다. 구체적으로, 동일한 video에서 N_T개의 video clip을 sample 하여 audio-visual feature pair B_T = {(\hat{E_a^i}, \hat{E_v^i}}_{i=1}^{N_T}를 추출합니다. sample 간 temporal contrast objective는 다음과 같습니다.

최종 objective는 semantic and temporal objective의 weighted sum인 L = L_S + λL_T가 되며, λ = 1로 설정했다고 합니다. 학습 후 CAVP는 audio-video pair를 embedding pair로 encode 합니다. (x_a, x_v) → (E_a, E_v)가 되며 (E_a, E_v)는 잘 align 되어 있고 visual feature E_v는 audio에 대한 풍부한 information을 담고 있습니다.
align 되고 매우 연관된 feature E_v와 E_a를 audio generation에 사용합니다.
LDM with Aligned Visual Representation
LDMs은 data laten space에서 denosing 하여 data distribution p(x)를 fit 하는 probabilistic model입니다. LDMs는 학습의 효율성을 위해 먼저 origin high dimensional data x를 low-dimension latent z = ε(x)로 encode 합니다. forward and reverse process는 압축된 latent space에서 수행됩니다. V2A generation에서, 저자들의 목표는 video clip x_v가 주어졌을 때, 그에 맞는 audio x_a를 생성하는 것입니다. latent encoder ε_θ를 사용해 Mel-spec x_a를 low-dim latent z_0 = ε_θ(x_a) ∈ R^{C' x T'/r x M/r}로 압축하며, 여기서 r는 compress rate를 나타냅니다. audio-visual align feature를 학습한 pretrained CAVP model을 사용하면, visual feature E_v가 풍부한 audio-related information을 포함하게 됩니다. 이를 통해 LDMs이 E_v를 condition으로 사용해 highly synchronized and relevant audio를 합성할 수 있게 됩니다. E_v를 적절한 dimension으로 projection 하기 위해, 저자들은 projection and positional encoding layer τ_θ를 사용합니다. forward process에서 고정된 schedule에 맞춰 noise를 점차 더하여 origin data distribution이 standard Gaussian distribution으로 변환됩니다.

위 식에서 \hat{a_t}는 각 forward step에서 더해지는 noise의 곱을 의미합니다. LDM의 목표는 denosing objective를 최적화하여 score matching을 mirroring 하는 것입니다.

LDM을 학습한 후, 저자들은 주어진 visual-feature E_v를 condition으로 하는 reverse process를 통해 audio latent를 생성할 수 있습니다.

최종적으로 생성된 latent z_0를 decoder D에 feed 하여 decoding 한 Mel-spec \hat{x_a}를 얻습니다. DIFF-FOLEY의 경우 8초 길이 audio sample을 생성합니다.
Temporal Split & Merge Augmentation
LAION-5B과 같은 large-scale text-image pair를 사용하는 것은 현재 T2I model의 성공에 필수적인 역할을 했습니다. 하지만 V2A generation task에서 large-scale and high-quality dataset은 여전히 부족한 상황입니다. 그리고 temporal audio-visual correspondence와 같이 visual content에 잘 synchronize 된 audio를 생성하는 V2A model은 많은 양의 audio-visual pair가 있어야 학습이 가능합니다. 이러한 한계를 극복하기 위해, 저자들은 Temporal Split & Merge Augmentation을 제안합니다. 이는 temporal alignment을 위한 prior knowledge를 training process에 통합하는 방식입니다. 학습할 때, 두 video에서 서로 다른 time length를 가진 video clip를 random 하게 추출합니다. (x_a^1, x_v^1), (x_a^2, x_v^2)가 될 것이고, pretrained CAVP model을 사용하여 visual feature E_v^1, E_v^2를 추출합니다. 이를 통해 LDM 학습에 사용할 새로운 audio-visual feature pair를 생성합니다.

위 식에서 [;]는 temporal concatenation (Merge)를 나타냅니다. Split and merge augmentation은 audio-visual pair 수를 크게 증가시키고 overfitting을 방지할 수 있으며, LDM이 temporal correspondence를 학습할 수 있도록 만들어줍니다.
Double Guidance
Guidance technique은 controllable generation을 위해 diffusion model reverse process에서 많이 사용됩니다. guidance technique으로 2가지 main type이 있습니다. classifier guidance (CG)와 classifier-free guidance (CFG)입니다. CG의 경우, 각 reverse process timestep에서 class label loglikelihood ∇_{x_t}log(p_φ(y|x_t))의 gradient를 이용해 reverse process를 guide 하도록 classifier (e.g. class-label classifier)를 학습시킵니다. CFG의 경우, 추가적인 classifier를 사용하지 않지만, condition과 uncondition score estimation의 linear combination을 사용하여 reverse를 guide 합니다.

위 식에서 c는 condition을 나타내고, w는 guidance scale을 나타냅니다. w = 1인 경우, CFG는 conditional score estimate로 퇴화됩니다. CFG가 diffusion model에서 mainstream approach이지만, CG method는 주어진 true label을 고려하여 생성된 sample의 원하는 속성을 guide 할 수 있다는 장점이 있습니다. V2A setting에서 요구되는 특성은 semantic and temporal alignment입니다. 그리고 CFG와 CG method가 mutually exclusive 하지 않다는 것을 발견했습니다. 저자들은 reverse process의 각 timestep에서 CFG와 CG method를 동시에 사용하여 두 method의 장점을 모두 사용하는 double guidance를 제안합니다. 구체적으로 CG의 경우, alignment classifier P(y, z_t, t, E_v)는 audio visual pair가 semantic and temporal alignment 관점에서 real pair인지 아닌지 예측하도록 학습합니다. CFG의 경우, 학습 과정에서 20% 확률로 E_v condition을 random 하게 삭제하여 conditional and unconditional likelihood를 학습합니다. double guidance는 다음과 같이 정의됩니다.

위 식에서 ω은 CFG guidance의 scale을 나타내고 γ는 CG guidance scale을 나타냅니다.
직관적으로 생각해 보면 CG의 경우 condition에 대한 세밀한 정보를 제공해 줄 수 있지만, classificaiton이 shortcut을 학습할 수도 있으며, 이를 통해 classifier의 gradient에 의해 reverse process에서 좋지 않은 결과가 생성될 수 있습니다. CFG와 CG 둘 다 사용한다면, CFG가 reverse process의 각 timestep에서 robust and reliable noise direction을 제공하며 CG term은 CFG term의 direction을 원하는 data attribute 방향으로 변환시켜 더 나은 sample quality를 얻을 수 있습니다.
위 식에서 CFG의 scale인 ω를 크게 설정한다면, audio quality와 synchronization을 크게 향상시킬 수 있습니다. CG의 scale인 γ를 키운다면, 우리가 원하는 audio-visual alignment로 refine 할 수 있습니다.
Experiments
Datasets
저자들은 VGGSound와 AudioSet이라는 두 dataset을 사용했습니다. VGGSound는 200K 개 10초 길이 video로 구성됩니다. original VGGSound train/test split을 그대로 사용했습니다. AudioSet은 527개 class인 2.1M 개 video로 구성되지만 매우 imbalance 하며, 대부분의 video는 Music and speech label입니다. video로부터 의미 있는 speech를 바로 생성하는 것은 V2A task에서 요구되는 것이 아니기 때문에, 저자들은 music tag data의 subset과 speech를 제외한 모든 tag를 download 하여 80K music-tagged video와 310K 다른 tagged video를 얻었으며, 이를 AudioSet-V2A로 불렀습니다. 저자들은 VGGSound와 AudioSet-V2A를 사용하여 CAVP를 학습했고, LDM에서는 VGGSound를 사용했습니다.
Data Pre-Processing
DIFF-FOLEY 학습을 위해, VGGSound와 AudioSet-V2A의 video들을 4 FPS로 sample을 진행했습니다. 4FPS로 sampling을 수행해도 이전의 다른 baseline method들(이 model들은 21.5 FPS, 30 FPS 정도를 사용) 보다 더 뛰어난 모습을 보여줍니다. 각 10초 길이 video sample들인 40개 frame들은 224 x 224로 resize 됩니다. audio data의 경우, original audio는 16kHz로 sample 되며 Mel-spectrogram (Mel Basis M = 128)으로 변환됩니다. Stage 1 pretraining의 경우, 더 나은 audio-visual data temporal dimension alignment를 위해 hop size 250으로 사용하고, LDM 학습의 경우 hop size를 256으로 사용했습니다.
Model Configuration and Inference
CAVP의 경우 저자들은 PANNs의 pretrained audio encoder를 사용하고 pretrained SlowOnly based video encoder를 사용했습니다. 학습의 경우 저자들은 10초 길이 sample에서 random 하게 4초 audio-video frame을 추출하여 x_a ∈ R^{256 x 256}과 x_v ∈ R^{16 x 3 x 224 x 224}를 얻습니다. N_T = 3인 temporal contrast L_T를 사용하고 각 pair마다 최소 시간 차를 2초로 설정했습니다. LDM 학습의 경우, 저자들은 pretraiend Stable Diffusion-V1.4 (SD-V1.4)을 denoising prior model로 사용했습니다. pretrained SD-V1.4는 학습 시간을 상당히 줄이고 생성 quality를 향상시킵니다. SD-V1.4에서 frozen pretrained latent encoder ε와 decoder D를 가져와 사용합니다. 흥미롭게도 image dataset (LAION-5B)로 학습되었지만 ε, D가 Mel-spectrogram을 잘 다룰 수 있습니다. inference 할 때, 25 sampling step으로 DPM-Solver sampler를 사용하였습니다.
Evaluation Metrics
평가를 위해 저자들은 Inception Score (IS), Frechet Distance (FID)와 Mean KL Divergence (MKL)를 사용합니다. IS는 sample quality와 다양성을 평가하고, FID는 distribution level에서 유사도를 측정하고 MKL은 paired sample-level에서 유사도를 측정합니다. 저자들은 synchronization과 audio-visual relevance를 평가하기 위해 Alignment Accuracy (Align Acc)라는 새로운 metric을 제안합니다. 저자들은 real audio-visual pair를 예측하기 위해 alignment classifier를 학습했습니다. classifier를 학습하기 위해, 저자들은 50% 양의 real audio-visual pair (true pair)를 label 1으로, 동일한 video지만 temporal shift가 있는 25% 양의 audio-visual pairs (temporal shift pair)를 label 0으로, 그리고 나머지 25%는 서로 다른 video에서 audio-visual pair (wrong pair)를 label 0로 설정했습니다. 저자들의 alignment classifier는 test set에서 90% 정확도를 보였습니다. 저자들은 IS와 Align Acc를 주요 metric으로 사용하여 sample quality를 평가했습니다. evaluation에서 저자들은 145K audio sample (test set에 있는 각 video마다 10개 sample)을 생성했습니다.
Baseline
비교를 위해, 저자들은 2가지 최신 V2A model인 SpecVQGAN과 Im2Wav를 사용했습니다. SpecVQGAN은 RGB+Flow와 ResNet50이라는 다른 visual feature를 기반으로 2가지 model을 준비했고, Im2Wav은 CLIP feature를 사용하여 의미적으로 관련된 audio를 생성하도록 만들었습니다. 저자들은 pretrained baseline model을 사용해 평가를 진행했으며, 각 model 모두 VGGSound를 가지고 학습되었습니다.
- Video-to-Audio Generation Results

위 표는 VGGSound test set을 가지고 quantitative 평가를 진행한 결과를 보여줍니다. DIFF-FOLEY는 IS와 Align Acc에서 baseline method들보다 뛰어난 성능을 보였으며, MKL/FID에서는 비슷한 성능을 보였습니다. DIFF-FOLEY가 IS에 대해서 baseline보다 2배 더 나은 성능을 보여주고 Align Acc는 94.05%를 달성했습니다. Im2Wav는 좋은 KL metric 성능을 보여주지만, inference speed가 느려 효율성이 떨어집니다. DIFF-FOLEY는 최신 diffusion sampler DPM-Solver를 사용하여 각 sample마다 25번의 inference step을 거쳐 평균 0.38초 만에 한 개의 sample을 만들고, batch마다 64개 sample을 생성합니다.

위 그림은 quality를 보여줍니다. DIFF-FOLEY는 baseline method와 비교했을 때 상당히 뛰어난 synchronized audio를 생성하는 능력을 가지고 있는 것을 볼 수 있습니다. 소리가 없는 golf video가 주어졌을 때, DIFF-FOLEY는 골프공을 치는 순간에 맞춰 소리를 성공적으로 생성하는 것을 볼 수 있지만, 다른 baseline method들은 정확한 시간에 sound를 생성하지 못하는 모습을 보여줍니다. 이를 통해 DIFF-FOLEY의 뛰어난 synchronization 성능을 입증했습니다.
Visual Feature Analysis
CAVP는 audio와 visual feature를 align 하기 위해 semantic and temporal contrast objective를 사용합니다. 저자들은 LDM 학습을 할 때 사용되는 다른 visual feature과 비교했을 때 CAVP visual feature의 효율성을 평가합니다. 결과는 다음과 같습니다.
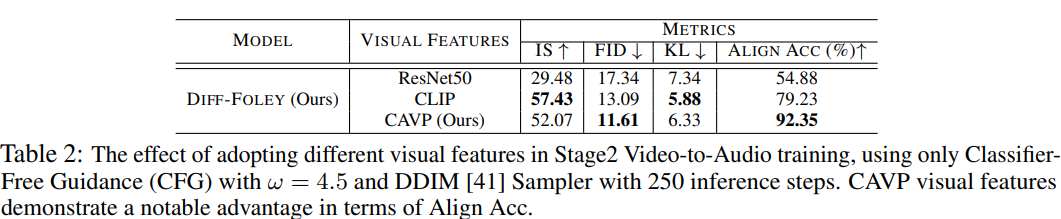
CAVP visual feature가 synchronization and audio-visual relevance (Align Acc)가 상당히 향상시키는 모습을 보여주었으며, 이를 통해 CAVP feature의 효율성을 입증하는 모습입니다. CLIP feature가 IS와 KL에서 좋은 모습을 보여주지만 synchronization 성능이 완벽하진 않습니다. 더 큰 dataset을 사용하면 CAVP가 이러한 차이를 줄일 수 있을 거라고 생각한다고 합니다. drum을 치는 video 결과는 아래와 같습니다.

다른 visual feature들이 audio를 생성할 때 사용됩니다. 이 예제에서 drum을 4번 칩니다. ResNet과 CLIP feature가 synchronized audio를 생성하는 데 실패한 모습을 보이지만, CAVP feature는 drum을 치는 순간과 drum sound 사이 relationship을 성공적으로 학습하여 완벽하게 synchronization 되는 것을 볼 수 있습니다.
Temporal Augmentation Analysis
저자들은 Temporal Split & Merge Augmentation 효과를 평가했습니다. 결과는 다음과 같습니다.

저자들의 결과는 Temporal Split & Merge Augmentation이 모든 metric에서 효과가 있음을 보여주며, 특히 Align Acc에서 특히 효과적임을 보여줍니다. augmentation 기술은 audio-visual temporal alignment의 prior knowledge를 사용하며 model의 synchronization 성능을 향상시키고 audio-visual training pair 수를 늘리고, overfitting을 완화시킵니다.
Downstream Finetuning
- Background
수십억 개 data로 학습된 Stable Diffusion과 같은 generative model은 사실 같은 image를 생성할 수 있지만, 특정 style 또는 개인적인 image를 그리는 것은 어려워합니다. finetuning 기술은 이러한 제약을 극복하는데 도움을 줍니다. DIFF-FOLEY는 다른 dataset으로 downstream finetuning을 통해 특정 type의 sound를 합성할 수 있는 일반화 성능을 기대할 수 있다고 합니다.
- Finetuning Details
저자들은 EPIC-Kitchen을 가지고 DIFF-FOLEY를 finetuning 했습니다. EPIC-Kitchen dataset은 부엌에서 일어나는 물체 간 상호작용을 나타내는 최소한의 sound noise가 있는 video dataset입니다. EPIC-Kitchen은 VGGSound와 상당히 구분됩니다. 이 실험을 통해 fine-tuned DIFF-FOLEY의 일반화 성능을 평가했습니다. pre-trained CAVP model을 사용하여 visual feature를 추출했고 VGGSound로 학습된 LDM을 200 epoch 만큼 fine-tuning 했습니다.
- Generation Results
EPIC-Kitchen에 fine-tune 된 LDM의 qualitative 결과는 다음과 같습니다.

DIFF-FOLEY가 original video와 매우 synchronize 된 audio를 생성하는 것을 볼 수 있으며, sound의 timing을 잘 capture 하는 것을 볼 수 있습니다.
Limitations and Broader Impact
DIFF-FOLEY는 VGGSound와 EPIC-Kitchen에서 상당히 뛰어난 audio-visual synchronization 성능을 보여주지만, 저자들은 data computation resource의 제한으로 인해 수십억 규모의 초대형 dataset에서의 확장성은 아직 평가하지 못했습니다. 그리고 GAN에 비해 Diffusion model이 느리다는 단점이 존재합니다. V2A는 video production을 가속화할 수 있지만, 오용과 잘못된 정보를 사용하는 것을 막기 위해 주의가 필요합니다.
Conclusion
저자들은 DIFF-FOLEY라는 뛰어난 audio-visual relevance를 보이는 synchronized audio를 생성하는 V2A approach를 제안합니다. 저자들은 생성 quality 관점에서 저자들의 method가 뛰어나다는 것을 증명했습니다. 그리고 저자들은 double guidance technique을 사용하여 LDM의 reverse process를 guide 하여 생성된 audio sample의 audio-visual alignment를 매우 향상시켰습니다. 저자들은 DIFF-FOLEY downstream finetuning을 통해 실용적인 applicability and generalization capability를 입증했습니다.



