https://arxiv.org/abs/2403.07938
Text-to-Audio Generation Synchronized with Videos
In recent times, the focus on text-to-audio (TTA) generation has intensified, as researchers strive to synthesize audio from textual descriptions. However, most existing methods, though leveraging latent diffusion models to learn the correlation between au
arxiv.org
위 논문을 보고 작성했습니다.
Abstract
최근 text-to-audio (TTA) generation에 대한 집중도가 향상되었으며, 연구자들은 textual description으로부터 audio를 합성하기 위해 노력해 왔습니다. 하지만 현재 존재하는 대부분의 method들은 audio embedding과 text embedding 사이 correlation을 학습하기 위해 latent diffusion model을 사용하지만, 생성된 audio와 video 사이 자연스러운 synchronization을 유지하는데 실패했습니다. 이는 종종 뚜렷한 audio-visual mismatch를 유발합니다. 이 gap을 줄이기 위해, 저자들은 T2AV-BENCH라 불리는 video와 align 하는 혁신적인 Text-to-Audio generation benchmark를 제안합니다.
Introduction
최근 DiffSound나 AudioGen과 같은 혁신을 통해, 연구자들은 denoising diffusion probabilisti models (DDPMs)의 성능에 대한 연구르 진행했습니다. 이러한 추세를 바탕으로, AudioLDM은 latent diffusion model과 contrastive prowess of language-audio pre-training (CLAP)의 시너지를 사용하는 새로운 방법이 등장했습니다. 그 결과로 audio는 풍부한 sound를 제공할 뿐만 아니라, 문맥적으로도 text와 연결되어 있습니다.
이러한 method들이 그럴듯한 sound를 만들어내는 것에 대해서 좋은 성능을 보여주지만, vidoe의 visual content와의 synchronization을 고려하지는 않으며, 결과적으로 audio와 video frame의 misalign이 발생됩니다. 예를 들어, model이 10초 길이 기차 경적 sound를 생성했을 때, frame에서 기차가 없을 수도 있습니다. 그래서 여기서 해결해야 할 문제는 video의 frame에서 sound를 자연스럽게 align 해야 한다는 점입니다. 이러한 점에서 영감을 받아 저자들은 video와 맞춘 각 text prompt의 의미를 학습하고 text-to-audio generation에 guide 하도록 만들었습니다. 이를 위해, 저자들의 key idea는 text embedding을 update 하기 위한 condition으로 video-aligned text representation을 capture 하는 것입니다.
저자들은 T2AV-BENCH라는 benchmark를 제안하여 video content와 synchronization을 보장하기 위해 video와 align하는 Text-to-Audio generation을 수행합니다. image domain의 Frechet Inception Distance에서 영감을 받아 저자들은 Frechet Audio-Visual Distance, Frechet Audio-Visual Distance, Frechet Audio-(Video-Text) Distance라는 3가지 새로운 metric을 제안하며, 이를 통해 저자들이 생성한 audio가 visual align 하는지, 시간적으로 일관성이 있는지 평가합니다.
이 benchmark 외에도, 저자들은 T2AV라는 간단하짐나 효과적인 latent diffusion model 기반 method를 제안합니다. 이는 visual-aligned text semantic을 video-aligned TTA generation의 guidance로 사용합니다. 구체적으로, 저자들의 T2AV는 대응하는 paired audio의 spatial and temporal level에서 textual feature와 visual feature 사이 alignment를 capture 하기 위해 visual-aligned contrastive language-audio pretraining을 사용합니다. 그다음 저자들은 temporal multi-head attention transformer기반 Audio-Visual ControlNet을 사용하여 latent diffusion model의 condition으로 사용되는 visual-aligned semantic 한 text embedding을 추출합니다. 이전 TTA baeline과 비교했을 때, 저자들의 framework는 Audio-Visual ControlNet에서 condition operator 수를 유연하게 가져갈 수 있으며, 주어진 input caption에 high-fidelity audio를 생성하기 위해 video-aligned semantic을 학습하는 것에 대한 효과를 보여줍니다.
저자들의 contribution을 요약하면 다음과 같습니다.
- T2AV-BENCH라 불리는 video와 align하는 새로운 Text-to-Audio generation benchmark를 제안하며, 시각적 일관성과 시간적 sync에 focusing 하는 새로운 3가지 metric을 사용하여 보완된 benchmark입니다.
- 저자들은 T2AV라 불리는 간단하지만 효율적인 방법을 제안하며, 이는 제안된 Audio-Visual ControlNet을 condition으로 하는 temporal video representation을 latent diffusion model에 적용하는 새로운 방법입니다.
- 실험을 통해 저자들의 T2AV가 이전 TTA generation baseline의 output보다 visual alignment & temporal consistency를 훨씬 뛰어 넘는다는 것을 입증했습니다.
Related Work
Audio-Visual Learning
이전 다양한 연구들에서 video에서 구분된 두 modality 사이 audio-visual alignment를 capture하기 위한 Audio-visual learning가 연구되었습니다. 이러한 cross-modal correspondence는 audio-event localization, audio-visual parsing, audio-visual spatialization & localization, visual-to-sound generation과 같은 다양한 audio-visual task에서 이점을 가져다줍니다. visual-to-sound generation task는 저자들의 문제와 연관되어 있지만, 저자들의 주요 focus는 visual-guided text-to-sound generation을 위해 cross-modal representation을 학습하는 것이며 이는 이전에 언급한 task보다 더 어려운 노력입니다.
T2AV-BENCH & Metrics
visual alignment와 temporal consistency 모두 가능한 video-aligned text-to-audio generation을 수행하는 T2AV-BENCH라는 새로운 benchmark를 제안합니다.
Benchmark Details
video-aligned text-to-audio generation을 평가하기 위해, 저자들은 500개 video-text pair로 구성된 새로운 dataset을 개발했습니다. 구체적으로 VGGSound의 test set에서 5158개 sample로부터 video를 얻었습니다. 각 video에서 "cat hissing", "female singing"과 같은 object와 action tagging이 포함된 class label을 text caption으로 사용했습니다. video-text pair를 기반으로, 저자들은 단일 source 객체, 시간적 일치, noise가 없는 background를 유지하는 video를 선택하여 500 쌍을 만들었습니다. 500개 video-text pair를 가지고 저자들은 각 video 마다 VGGSound의 original annotated information에 있는 starting timestamp에 맞춰 10초 길이 audio clip을 추출했습니다.
Metrics Details
image의 quality를 평가하는 Frechet inception distance (FID)와 audio의 quality를 평가하는 Frechet audio distance (FAD)와 유사하게, 저자들은 저자들의 video-aligned TTA generation이 만든 audio가 visual alignment 한 지, temporal consistency가 있는지 평가하기 위해 3가지 세로운 metric을 제안합니다.
- Frechet Audio-Visual Distance (FAVD): 생성된 audio의 분포를 real video set의 분포와 비교합니다. 구체적으로, 저자들은 VGGish로 얻은 audio embedding과 C3D로 얻은 video embedding 사이 거리를 계산합니다.
- Frechet Audio-Text Distance (FATD): 생성된 audio의 분포를 tagging text set의 분포와 비교합니다. audio embedding은 VGGish를 사용하여 구하고, word2vec을 이용하여 tagging class에 대한 text embedding을 구해 둘 사이 distance를 구합니다.
- Frechet Audio-(Video-Text) Distance (FAVTD): 생성된 audio의 분포를 video와 taggin text set의 분포와 비교합니다. VGGish로 audio embedding을 구하고, VGGish를 사용하여 video embedding을 구하고, word2vec을 이용하여 text embedding을 구해 평균 embedding을 구한 후 둘 사이 거리를 계산합니다.
Metrics Validation
저자들이 제안한 metric이 visual alignment와 temporal consistency를 평가하기에 효과적이라는 것을 증명하기 위해, 저자들은 (true) video-text pair와 mismatching (false) pair를 준비하여 metric을 계산해 simulation 실험을 수행했습니다.
- Visual Alignment
visual alignment를 위해, 저자들은 500개 matching (true) video-text pair와 500개 random하게 선택된 mismatching (false) pair를 사용하여 T2AV-BENCH에 대한 FAVD, FATD, FA(VT)D를 포함한 모든 metric을 계산했습니다. 그리고 AudioCaps에서 무작위로 선택된 500개의 matching (true) video-text pair를 사용합니다. 결과는 다음과 같습니다.

visual information과 mismatch인 false pair 수가 늘어남에 따라, 모든 metric도 향상되는 결과를 보여주고 있습니다. 500개 true pair를 더해 [500, 500] pair를 만들면 모든 meric이 감소하는 것을 볼 수 있습니다. 이러한 결과는 visual alignment를 평가하는 데 저자들의 metric이 효과적임을 보여줍니다.
- Temporal Consistency
temporal consistency를 위해, 저자들은 FAVD score의 변화를 비교하는 두 가지 하위 실험을 수행했습니다. 먼저 VGGSound에서 동일한 class인 500개 video를 random하게 선택합니다. 그다음 T2AV-BENCH에서 동일한 pair audio를 무작위로 shift 합니다. 결과는 다음과 같습니다.

FAVD score에 관점에서 저자들의 T2AV-BENCH의 결과를 비교하여 보여줍니다. 동일한 visual information을 공유하지만, mismatching temporal consistency와 false pair 수가 증가됨에 따라 FAVD score가 증가되었습니다. VGGSound에서 true pair 500개를 추가하여 [500, 500]을 만들었더니, FAVD score가 감소되는 것을 볼 수 있습니다. visual alignment와 함께 temporal consistency를 평가하는 데 저자들이 제안한 metric이 중요한 역할을 하는 것을 보여줍니다.
Method
video frame과 text prompt가 주어졌을 때, 저자들은 textual and visual semantic과 align된 audio를 합성하는 것을 목표로 합니다. 저자들은 LDM 기반 새로운 TTA generation approach인 DiffAVA를 제안합니다. 이는 Visual-aligned CLAP과 Audio-Visual ControlNet이라는 두 main module로 구성됩니다.
Preliminaries
- Problem Setup and Notations
video의 audio a와 visual frame v, text prompt t가 주어지면, textual and visual semantic과 align 된 새로운 audio를 합성하는 것을 목표로 합니다. video의 경우, 저자들은 audio의 mel-spectrogram A ∈ R^{T x F}와 visual frame V ∈ R^{T x H x W x 3}를 얻습니다. T와 F는 time과 frequency를 의미합니다. CLAP의 pre-trained text encoder f_t()와 pre-trained audio encoder f_a()를 통해 text feature F^t와 audio feature F^a를 추출합니다.
- Revisit AudioLDM
TTA generation의 문제점을 해결하기 위해, AudioLDM은 audio mel-spectrogram의 audio prior z_0 ∈ R^{C x T_r x F_r}에 대해 noise ε (z_n, n, F^t)를 추정하는 conditional latent diffusion model을 사용합니다. C는 latent representation의 channel을 나타내고 r은 compressive level을 나타냅니다. noise estimation에 대한 training objective는 다음과 같습니다.

위 식에서 ε∈N(0, I)는 더해지는 noise를 의미합니다. N번 forward pass 이후 마지막 step에서, input z_n은 isotropic Gaussian noise가 됩니다. 학습 과정에선 video에 있는 audio α의 cross-modal representation F^α에서 audio prior z_0를 생성합니다. TTA generation의 경우, ε_θ(z_n, n, F^α) 대신 ε_θ(z_n, n, F^t)을 예측하기 위해 text embedding F^t를 사용합니다.
- Visual-aligned CLAP
textual feature와 visual feature를 spatial and temporal level에서 paired sound에 맞춰 align하기 위해, 저자들은 multi-head attention transformer를 사용하여 video feature에서 temporal information을 집약합니다. 그다음 새로운 visual-aligned text embedding F^을 만들기 위해 text embedding과 temporal visual representation을 fuse 하는 dual multi-modal residual network를 사용합니다. contrastive language-audio pre-training (CLAP)을 기반으로, 저자들은 textual feature와 audio representation 사이에 visual-aligned CLAP을 사용하고 다음과 같이 정의됩니다.

위 식에서 similarity sim(F_b,i, F_b,i)는 두 input에 대해 모든 temporal location에 맞춰 temporal audio-textual cosine similarity를 의미합니다. B는 batch size를 나타내고, D는 dimension을 의미하며, τ는 temperature hyper-parameter를 나타냅니다.
- Audio-Visual ControlNet
visual-aligned CLAP pre-training의 이점을 활용하여, 저자들은 pre-trained text encoder를 사용하여 visual-aligned semantic을 가진 text embedding을 추출하여 latent diffusion model의 condition으로 사용했습니다. temporal consistency를 향상시키기 위해, 저자들은 multimodal conditional text-to-image diffusion model인 ControlNet에서 영감을 받아 temporal self-attention layer를 가진 새로운 Audio-Visual ControlNet module을 제안합니다. 구조는 다음과 같습니다.

구체적으로 저자들은 temporal self-attention layer φ()를 사용하여 pre-trained visual encoder의 raw output feature에서 temporal feature를 집약했습니다.
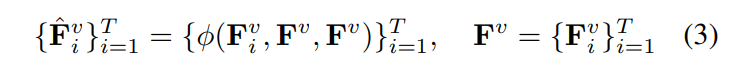
self-attention operator φ()는 다음과 같습니다.

저자들의 model은 latent diffusion model의 parameter를 고정시키고 AudioLDM에서 release된 VAE 및 vocoder를 직접 사용하여 효과적이고 video-conditioned TTA generation을 수행하게 됩니다.
Experiments
Experimental Setup
저자들은 AudioCaps dataset을 사용하였으며, 이는 YouTube video에서 train을 위해 45423개 10초 길이 audio clip과 그에 맞는 caption으로 구성되며, validation dataset은 2240개 sample로 구성됩니다. 각 audio clip들이 5 text caption으로 구성되기 때문에, 저자들은 1개 random caption을 선택하여 text condition으로 사용했습니다. VGGSound는 309개 sound category로 구성된 10초 길이 200k 개 YouTube video clip으로 구성됩니다. The Look, Listen and Parse (LLP) Dataset은 25가지 event class로 구성된 10초 길이 11849개 YouTube video clip으로 구성됩니다.
Comparison to Prior Work
이전에 등장한 DDPM and LDM baseline들(SpecVQ-GAN, DiffSound, MMDiffusion, AudioGen, AudioLDM)을 사용하여 비교를 진행했습니다. video-aligned text-to-audio generation에 대한 정량적 실험 결과는 다음과 같습니다.

위 표와 같이, 저자들의 T2AV가 video-aligned text-to-audio generation 성능이 다른 model보다 더 뛰어난 것을 볼 수 있습니다. 이를 통해 저자들의 방식이 text caption을 가지고 고품질의 video-aligned audio를 생성하는데 효과적이라는 것을 증명했습니다.
Conclusion
이 연구에서 저자들은 T2AV-BENCH라는 video와 align하는 새로운 TTA generation benchmark를 제안하며, visual alignment와 temporal consistency를 평가하는 3가지 새로운 metric을 소개합니다. 그리고 저자들은 간단하지만 효과적인 latent diffusion approach인 T2AV를 제안하며, 이는 Audio-Visual ControlNet을 통해 temporal visual-aligned embedding을 condition으로 사용합니다. 저자들은 Audio-Visual ControlNet에서 temporal visual embedding을 fuse 하기 위해, video feature에서 temporal information을 집약하는 temporal multi-head self attention transformer를 사용합니다. T2AV-BENCH와 AudioCaps에 대한 실험을 통해, 저자들의 T2AV가 visual-aligned text-to-audio generation 성능이 좋다는 것을 보였습니다.



