https://arxiv.org/abs/1802.06182
CREPE: A Convolutional Representation for Pitch Estimation
The task of estimating the fundamental frequency of a monophonic sound recording, also known as pitch tracking, is fundamental to audio processing with multiple applications in speech processing and music information retrieval. To date, the best performing
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
pitch tracking이라 알려진 monophonic sound recording의 fundamental frequency를 추정하는 task는 speech processing과 music information retrieval과 같은 다양한 application의 audio processing에서 중요하게 사용됩니다. 현재까지 pYIN algorithm과 같이 가장 좋은 성능을 보여주는 기술들은 DSP (Digital Signal Processing) pipeline과 heuristic의 결합을 기반으로 합니다. 이러한 기술들은 일반적으로 잘 동작하지만, pitch를 정확하게 추정하지 못하는 경우가 여전히 존재합니다. 이 논문에서 저자들은 data-driven pitch tracking algorithm인 CREPE를 제안합니다. 이는 time-domain waveform에서 바로 수행되는 deep convolutional neural network 기반 algorithm입니다. 저자들이 제안한 model이 최첨단 기술과 동등하거나 더 나은 결과를 보여줍니다. 그리고 noise에 대해 robust 하고 model의 일반화 성능이 좋습니다.
Introduction
Pitch는 인지되는 sound의 주관적인 quality로 정의되고 물리적 속성인 fundamental frequency와 완전히 일치하는 것은 아닙니다. 하지만 몇 가지 예외를 제외하고 pitch는 fundamental frequency를 사용하여 정량화될 수 있으며, 심리음향학적 연구 외의 분야에서는 이 두 용어가 종종 혼용되기도 합니다. 편의를 위해 저자들은 두 용어를 혼용하여 사용합니다.
monotonic pitch estimation을 계산하는 방법은 50년보다 더 오랜 기간동안 연구되어 왔으며, 그동안 많은 신뢰할 수 있는 방법들이 제안되었습니다. pYIN은 YIN의 확률적 변형으로, HMM을 사용하여 가장 가능성 높은 pitch value sequence를 decode 합니다.
이전 방법들은 heuristic을 고안하는 것에만 의존하며, data에서 직접 학습되는 것은 없다는 단점이 있습니다. music information retrieval problem에서 data-driven method들이 일관성 있게 heuristic approach보다 더 나은 모습을 보여줍니다.
이 논문에서 저자들은 time-domain signal에서 동작하는 deep convolutional neural network 기반 새로운 monophonic pitch tracking data-driven method를 제안합니다. 저자들의 method는 CREPE (Convolutional Representation for Pitch Estimation)이라 불리며, 가장 뛰어난 성능을 보이고 pYIN과 SWIPE처럼 heuristic approach보다 noise에 더 robust 한 성능을 보이고 있습니다.
Architecture
CREPE는 pitch estimate를 생성할 수 있도록 time-domain audio signal에서 바로 동작하는 deep convolutional neural network로 구성됩니다. 저자들이 제안한 architecture의 block diagram은 아래와 같습니다.

input은 16kHz sampling rate를 사용하는 time-domain audio signal에서 1024개 sample을 추출된 것입니다. 2048차원 latent representation을 구하는 six convolutional layer가 있고, 그 뒤에 densely output layer와 sigmoid activation이 붙고 360차원 output vector y를 구합니다. 이를 통해 pitch estimate를 deterministic 하게 계산됩니다.
output layer의 각 360개 node는 특정 pitch value를 나타내며, cent로 정의됩니다. Cent는 reference pitch f_{ref}에 대한 음악적 간격을 나타내는 단위로, frequency f에 대한 함수로 정의됩니다.

위 식에서 f_{ref} = 10Hz로 설정하여 사용했다고 합니다. 이 unit은 100 cent가 반음(semitone)과 같도록 log pitch scale을 제공합니다. 360 pitch value를 ¢_1, ... , ¢_360으로 나타내고, 32.70Hz에서 1975.5Hz에 대응하는 C1과 B7 사이를 20 cent 간격으로 6 옥타브를 cover 하도록 선택됩니다. 결정된 pitch estimate ¢^는 output y에 따른 관련 pitch들의 weighted average로 구해집니다.

위와 같습니다. model을 학습하기 위해 사용하는 target output은 360차원 vector이며, 각 차원은 20 cent를 cover 하는 frequency bin을 나타냅니다. ground truth fundamental frequency에 대응하는 bin의 크기는 1로 설정됩니다. target은 Gaussian-blurring 되고 표준편차는 25 cent로 설정했습니다.

마지막 layer의 높은 activation은 input signal이 해당 node의 pitch와 가까운 pitch를 가질 가능성이 있음을 의미합니다.
network는 target vector y와 predicted vector 사이 binary cross entropy를 minimize 하도록 학습됩니다.

위 식에서 y_i와 y_i^은 0에서 1 사이 실수값입니다. 이 loss function은 ADAM optimzier를 사용하여 최적화되고, learning rate는 0.0002로 설정했다고 합니다. 각 convolutional layer 앞에 batch normalization이 있고 뒤에 0.25 확률인 dropout layer가 붙습니다.
Experiments
Datasets
CREPE를 객관적으로 평가하고 다른 algorithm들과 성능을 비교하기 위해서 완벽하게 ground truth annotation이 있는 audio data가 필요합니다. 그래서 저자들은 MedleyDB라는 dataset을 사용할 수 없었습니다. annotation과 audio 사이 100% 완벽한 일치를 보장하지 않기 때문에 MedleyDB와 같은 dataset을 사용할 수 없습니다. 완벽한 객관적 평가를 보장하기 위해, 저자들은 생성된 signal의 f_0를 완벽하게 control 할 수 있는 합성된 audio dataset을 사용해야만 합니다. 그래서 저자들은 RWC-synth와 MDB-stem-synth를 사용했습니다.
Results
- Pitch Accuracy

위 표는 두 dataset에서 진행한 pitch estimation 성능을 보여줍니다. RWC-synth dataset의 경우, CREPE는 baseline보다 더 낮은 error rate를 보여주며 거의 완벽한 성능을 보여줍니다. 이는 RWC-synth dataset이 고도로 균일한 timbre으로 구성되어 있기 때문에 가능했으며, 더 다양한 timbrally dataset으로 평가를 진행하여 일반화 성능을 평가했습니다. MDB-stem-synth의 결과 또한 CREPE가 baseline보다 더 좋은 성능을 보여주는 것을 볼 수 있습니다. 즉 CREPE가 pYIN과 SWIPE보다 복잡한 timbre에서 더 강건한 성능을 보인다는 것을 의미합니다.
- Noise Robustness
noise robustness는 중요합니다. 결과는 다음과 같습니다.
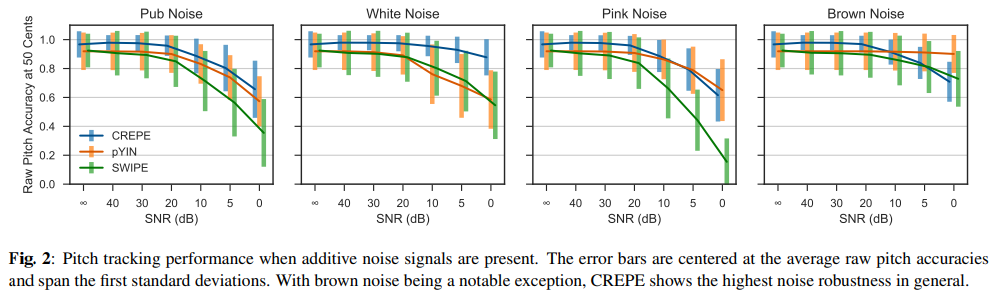
pub noise와 white noise에서 CREPE가 모든 SNR level에서 가장 좋은 성능을 보여주는 것을 볼 수 있습니다. Brown noise의 경우, pYIN의 성능이 noise에 거의 영향을 받지 않는 모습을 보입니다. brown noise가 low frequency에서 대부분의 energy를 사용하기 때문에 YIN algorithm이 특히 robust 한 모습을 보여줍니다.
Discussion and Conclusion
이 논문에서 저자들은 time-domain input을 처리하는 deep convolutional neural network 기반 새로운 monophonic pitch tracking data-driven method CREPE를 제안합니다. 저자들은 CREPE가 pYIN과 SIPE라는 baseline보다 더 뛰어난 모습을 보인다는 걸 증명했습니다. CREPE가 대부분의 noise가 추가되어도 robust 합니다.



