https://www.isca-archive.org/interspeech_2020/wang20u_interspeech.html
ISCA Archive
Using Cyclic Noise as the Source Signal for Neural Source-Filter-Based Speech Waveform Model Xin Wang, Junichi Yamagishi Neural source-filter (NSF) waveform models generate speech waveforms by morphing sine-based source signals through dilated convolution
www.isca-archive.org
해당 논문을 보고 작성했습니다.
Abstract
Neural source-filter (NSF) waveform model은 sine-based source signal을 time domain에서 dilated convolution을 수행하여 morphing 해 speech waveform을 생성합니다. sine based source signal은 NSF model이 특정 pitch로 voiced sound를 생성할 수 있도록 도와주지만, target voiced sound의 주기성이 뚜렷하지 않다면, sine shape는 생성된 waveform이 제약을 갖게 만듭니다. 이 논문에서 저자들은 cyclic noise라 불리는 더 유연한 source signal을 제안합니다. 이는 static random noise와 pulse train의 convolution을 통해 signal shape을 control 하는 학습 가능한 decaying rate를 가지는 준주기적 noise sequence입니다.
저자들은 NSF model이 cyclic noise-based source signal로부터 주기적 voiced sound를 생성하는 NSF model을 guide하는 masked spectral loss를 제안합니다. 대규모 listening test 결과를 통해 저자들은 cyclic noise의 효율성을 입증하고 masked spectral loss도 입증했습니다.
Introduction
저자들은 source-filter speech production model의 idea를 dilated convolution (CONV) NN과 결합한 neural source-filter (NSF) waveform model을 제안합니다. NSF model은 3가지 common component를 공유합니다: input spectral feature를 pre-processing 하는 condition module, input F0를 사용하여 sine-based source signal을 생성하는 source module, source signal을 output waveform으로 변환하는 dilated-CONV-based filter module입니다. 다른 neural waveform model들과 비교했을 때, NSF model은 waveform generation을 쉽게 학습하고 빠르게 동작할 수 있습니다.
NSF model들은 time domain에서 source signal을 점진적으로 변형시켜 output waveform을 생성하기 때문에, NSF model에게 source signal은 매우 중요합니다. 이전 TTS 연구들은 생성된 voice sound가 정확하게 주기성을 유지할 수 있도록 sine-based source signal을 사용했습니다. 그리고 sine-based speech waveform을 사용하는 것은 NSF model이 고품질의 music signal을 생성할 수 있게 도와줍니다.
하지만 speech waveform generation의 경우, target sound가 주기성이 뚜렷하지 않다면 sine-based source signal은 artifact를 야기할 수도 있습니다. 특정 waveform shape를 사용했을 때 생기는 문제를 완화하고 주기성을 유지하기 위해, 저자들은 cyclic noise를 source signal로 사용하는 것을 제안합니다. specified F0를 가진 pulse train과 tunable decaying rate를 가진 random noise를 convolving하여 cyclic noise를 구합니다. 이를 통해 source signal의 준주기성을 유지할 수 있고, 주기 간의 cyclostationary randomness를 가능하게 합니다. 그리고 저자들은 NSF model이 준주기적 cyclic noise로 주기적 voiced sound를 생성할 수 있도록 만들어주는 masked spectral loss를 제안합니다. 실험을 통해 저자들이 제안한 cyclic noise를 사용하는 것이 sine-based source signal을 사용하는 것보다 남성 speaker에 대해서 더 좋은 모습을 보이고 여성 speaker data에 대해서는 동등한 성능을 보인다는 것을 증명했습니다.
Review of hn-sinc-NSF model
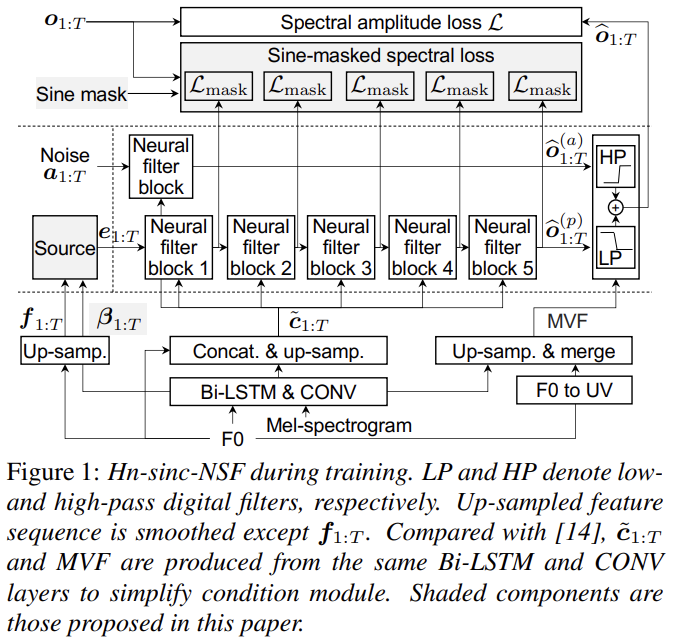
이 논문에서 저자들은 sinc filter를 사용하는 최신 harmonic-plus-noise NSF model (hn-sinc-NSF)에 초점을 맞춥니다. 위 그림과 같은 hn-sinc-NSF model은 input frame-level F0와 Mel-spectrogram이 변환되고 target waveform과 동일한 길이인 T까지 upsample 하여 feature sequence를 만듭니다. up-sampled F0는 source module에 feed 되어 source signal을 생성하고, 처리된 acoustic feature를 dilated CONV layer와 skip connection으로 구성된 neural filter block에 feed 합니다. neural filter block은 two branch로 구성됩니다: source module이 생성한 output을 o^(p)으로 변환하는 harmonic branch, noise sequence a를 o^(a)으로 변환하는 noise branch입니다. o^(p)는 low-pass sinc filter로 filtering 하고, o^(a)는 high-pass sinc filter로 filtering 해서 더하여 output waveform을 만듭니다. sinc filter의 time-variant cut-off frequency 또는 maximum voiced frequency (MVF)는 input acoustic feature를 가지고 예측됩니다. model은 o^과 o 사이 spectral amplitude loss를 minimize 하여 학습됩니다.
harmonic branch에 있는 source signal e_{1:T}는 sine waveform 기반이며 2단계에 걸쳐 생성될 수 있습니다. 먼저 up-sampled F0를 가지고 F0 또는 h번째 harmonic을 포함하는 sine waveform를 생성합니다. 식은 다음과 같습니다.

f_t = 0은 t번째 time step의 unvoiced를 나타내며, Φ ∈ [-π, π]는 random initial phase를 나타내고, N_s는 waveform sampling rate를 나타내며, n_t ~ N(0, σ^2)는 Gaussian noise를 나타냅니다. 각 t에 대해, e_t는 다음과 같습니다.

여기서 H는 harmonic 수를 나타내고 {w_1, ... , w_H, w_b}는 학습 가능한 tanh activation function을 사용하는 feedforward layer의 weight를 나타냅니다. 저자들은 H = 8, σ = 0.003, α = 0.1로 두고 model을 구현했습니다. n_t와 hn-sinc-NSF의 noise source signal a_t는 동일한 Gaussian distribution에서 sample 될 수 있지만 독립적입니다
Proposed methods
Cyclic noise-based source signal
sine-based source는 주기적인 waveform을 생성하는 것에 유용하지만, sine shape는 perceptual artifact를 만들 수도 있습니다. 예를 들어 불규칙한 glottal pulse가 있는 creaky voice에는 적절하지 않으며, source signal의 shape가 더 인식적으로 영향을 끼치는 low-pitch voice에도 적절하지 않습니다. 저자들은 voiced sound의 경우 더 나은 NSF source signal은 단기간에 더 많은 randomness를 포함하지만, long-term periodicity를 보존할 수 있어야 한다고 가정합니다. 기존 speech vocoder에 사용되는 source signal을 사용할 수 있지만, 저자들은 simple parametric form이고 추가적인 analysis loop를 필요로 하지 않는 source signal에 focus를 맞춥니다.
speech perception의 실험적인 연구 결과에서 영감을 받아, 저자들은 cyclic noise라 불리는 source signal을 제안합니다. 이는 simple parametric form이고 주기성과 randomness를 보존할 수 있습니다. up-sampled F0 f_{1:T}에 대응하는 unit impulse train p_{1:T} = [p_1, ... , p_T]라 하고 n_{1:T}를 gaussian noise sequence라 하겠습니다. 제안된 t번째 time step의 source signal e_t를 다음 두 step을 통해 계산됩니다.

위 (4) 식은 (2)와 유사하지만, multiple signal 대신 e_t^만 사용합니다(즉 harmonic을 사용하지 않음). unvoiced region에서 e_t^는 여전히 random noise이지만, voiced region의 e_t^는 p_{1:T}와 exponentially decaying noise n_{k+1}exp(-kf_t/β_tN_S)의 convolution입니다. f_t/N_s는 decaying rate가 period length나 F0에 독립적이게 만들어줍니다. 두 pulse 사이 간격의 길이에 상관없이 k가 period length N_s/f_t와 같아지면 noise value가 exp(-1/β_t)만큼 scale 됩니다. noise value는 β_t는 decaying rate를 control 하는 주요 parameter가 됩니다.
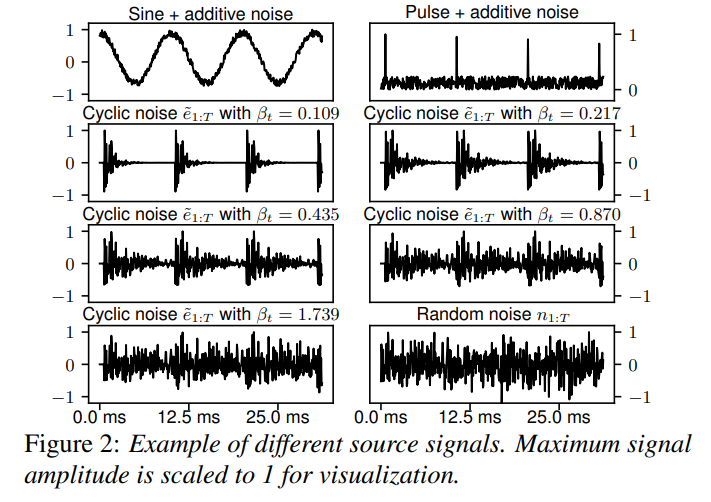
β_t를 조절하여 voiced sound의 cyclic noise-based source signal의 randomness와 주기성을 변경할 수 있습니다. 위 그림을 통해 다양한 β_t에 따른 source signal을 보여주고 있습니다. β_t = 0.435일 때, t = N_s/f_t에서의 noise amplitude는 exp(-1/0.435)로 scale됩니다. β_t가 작으면 random noise는 더 빠르게 감소되고 source signal은 pulse train과 더 가까워집니다. β_t가 증가되면, source signal은 noisy 하고 주기성이 약해집니다.
p_{1:T}는 F0를 전달하는 sine waveform의 local maxima인 t에서 p_t = 1로 설정하여 생성됩니다. noise sequence n_{1:T}는 Gaussian distribution에서 sample되며 각 training sample마다 변경됩니다.
Predicting β_t from acoustic features
decaying rate β를 hyper-parameter로 설정해 trial and error를 통해 결정합니다. 이 방식 대신 각 time step t에서 input acoustic feature를 사용해 β_t를 예측하는 small neural network를 사용할 수도 있습니다.
저자들은 Bi-LSTM와 CONV layer를 사용해 condition module을 구현했으며, condition module은 frame level에서 1차원 singal을 예측합니다. 이 signal은 그 다음 up-sample 된 다음 β_{1:t} = {β_1, ... , β_T}에 의해 smooth 됩니다.
Additional masked spectral loss to stabilize pitch
저자들은 실험에서 cyclic noise의 randomness가 stable pitch를 가진 waveform을 생성하는데 어려움을 준다는 것을 알아냈습니다. source signal이 NSF neural filter block에 의해 점차 변형되기 때문에, natural waveform과 filter block의 output 사이의 harmonic structure의 mismatch를 penalize한느 추가적인 loss가 있다면 도움이 될 것이라고 생각했다고 합니다.
그래서 저자들은 masked spectral loss를 제안합니다. K-point FFT를 사용하여 natural waveform의 n번째 frame의 복소수 spectrum y^(n)이 있다고 하겠습니다. neural filter block의 output signal로 구해진 spectrum을 p^(n)이라 하고 mask signal로 구해진 spectrum을 m^(n)이라 하겠습니다. loss는 다음과 같이 정의됩니다.

N은 frame 수를 나타내고 η = 1e-5를 통해 안정성을 보장해 주는 계수입니다. mask singal은 e_{1:T}^<h>의 평균으로 정의됩니다. 이는 input F0의 harmonic을 나타내는 sine waveform들의 평균을 의미합니다. 이러한 mask signal의 spectrum amplitude는 harmonic frequency와 동일한 높이의 peak를 가지며, L_{mask}는 전체 spectral envelope보단 harmonic structure의 mismatch를 penalize 합니다.

위 그림과 같습니다. masked spectral loss L_{mask}는 multiple STFT를 사용하여 구해집니다.
Experiments
Experimental models

hn-sinc-NSF model list는 위 table과 같습니다. source signal과 L_{mask}를 제외하고 모든 model들은 sinc1-h-NSF와 동일한 network architecture입니다. 각 neural filter block의 k-th dilated-CONV layer의 dilation size는 2^{k-1}입니다.
Results and analysis
각 trained experimental model은 264개 test set waveform을 생성합니다. 생성된 waveform의 quality는 large-scale crowd-sourced listening test의 평균으로 평가됩니다.

1-to-5 mean opinion score (MOS) scale로 실험을 진행했습니다. 실험 결과는 위와 같습니다. 성별에 따른 성능 차이가 발견되었습니다. 여성 speaker에 대해서 sine and pulse가 random noise보다 더 나은 성능을 보여주지만, 남성 speaker의 경우 random noise가 더 나은 모습을 보여줍니다.
기존 speech vocoder의 경우에서도 성별 차이에 따른 성능 차이가 발견되었지만, 저자들은 새로운 발견을 했습니다. 예를 들어 남성의 경우 random noise는 주기적 voiced sound를 생성하고 sine or pulse를 사용했을 때보다 더 인지적으로 뛰어납니다. random noise를 사용하면 neural filter block이 random nooise를 long periodic cycle을 가진 주기적 waveform으로 변환할 수 있지만, classical vocoder에 있는 linear filter는 불가능합니다. 여성 voice의 경우, neural filter block이 short period cycle을 가진 주기적 waveform을 생성하는 것이 어렵기 때문에 주기적 source signal을 사용하는 것이 더 좋은 결과를 보인다는 걸 알아냈습니다.
Conclusion
저자들은 NSF model에 사용할 수 있는 cyclic noise라 불리는 새로운 종류의 source signal을 제안합니다. cyclic noise는 pulse train과 exponentially decaying noise sequence의 convolution 기반의 간단한 parametric form을 사용합니다. 저자들은 실험을 통해 적절한 β를 선택하면 cyclic noise signal이 주기성을 유지하고 randomness를 갖게 만든다는 것을 발견했습니다. 남성 speaker에는 잘 동작하지 않고 여성 speaker에서는 잘 동작하는 sine-based source signal과 비교했을 때, 제안한 cyclic noise가 female and male voice 모두에 적합합니다.



