1. 정규화란?
딥러닝을 공부하다 보면 "정규화"라는 용어를 자주 접하게 되는데 'normalization', 'standardization', 'regularization' 모두 정규화라고 번역됩니다. 사실 이 세 단어는 모두 다른 의미를 가지고 있습니다.
먼저 정규화가 필요한 이유에 대해서 알아보겠습니다. 머신러닝 알고리즘은 기본적으로 수많은 데이터를 가지고 진행됩니다. 보통 예측하고자 하는 것과 연관이 있는 여러 feature를 가지고 머신러닝 알고리즘을 학습시키는데 이 feature의 값들은 다양합니다. 예를 들어 부동산의 가격을 예측하는 머신러닝을 학습시킨다고 생각을 해보겠습니다.
부동산 가격에 영향을 주는 feature들은 평수, 역과의 거리, 지어진 년도 등 존재할 것입니다. 예를 들어 평수는 10 ~ 80평 사이의 값을 갖는다 생각해보고 역과의 거리는 0.5km ~ 5km 사이의 값을 갖는다 생각해보고 지어진 년도는 1 ~ 20년 사이의 값을 갖는다 생각해보겠습니다. 각 값들의 단위도 다르고 만약 단위가 같더라도 값의 범위가 크게 차이나는 상황에서는 비교하는 것이 힘듭니다. 이러한 이유로 인해 feature의 단위를 무시하고 범위를 비슷하게 맞춰주기 위해 사용되는 것이 정규화입니다.
- Normalization
학습 전에 값의 범위(scale)를 0 ~ 1 사이의 값으로 바꾸는 일을 합니다. 이는 머신러닝에서 scale이 큰 feature의 영향이 더 커지는 것을 방지하기 위해서 사용하고 학습 속도를 향상하기 위해서 사용합니다. feature의 스케일을 조정한다는 의미로, 'feature scaling'이라고도 불립니다.
- Standardization
학습 전에 값의 범위(scale)를 평균 0, 분산 1이 되도록 변환하는 일을 합니다. 평균을 기준으로 얼마나 떨어져 있는지를 살펴볼 때 일반적으로 사용됩니다. 이도 역시 머신러닝에서 scale이 큰 feature의 영향이 더 커지는 것을 방지하기 위해서 사용하고 학습 속도를 향상하기 위해서 사용합니다. 정규분포를 표준정규분포로 변환하는 일을 한다고 볼 수 있습니다. 이러다 보니 standardization은 표준화로 번역되기도 합니다.
- Regularization
weight를 조정하기 위해 제약을 거는 기법입니다. overfitting을 막기 위해 사용됩니다. 보통 모델의 설명도를 유지하면서 모델의 복잡도를 줄이기 위해 사용됩니다.
2. Normalization 설명

이 식은 정규화의 대표적인 공식입니다. 위 공식을 통해 모든 데이터들은 0 ~ 1 사이의 갑으로 표현됩니다.
먼저 이와 같은 그림으로 normalization을 사용하면 학습에 도움이 되는 것을 확인할 수 있습니다. 왼쪽 그래프는 normalization 하기 전의 그림이고 오른쪽 그림은 normalization을 한 그림입니다. normalization을 한 데이터를 가지고 학습한 속도가 훨씬 빠른 것을 볼 수 있습니다.
3. Normalization 종류
■ Batch Normalization
Batch Normalization은 2015년 Batch Normalization : Accelerating Deep Network Training by Reducing Internal Covariate Shift 논문에 설명되어 있는 기법입니다. 이 정규화는 gradient vanishing / gradient exploding이 일어나지 않도록 하는 아이디어 입니다. Batch Normalization은 training 과정 자체를 안정화하여 학습 속도를 가속화하는 방식으로 gradient vanishing / gradient exploding을 예방합니다. 표준화와 유사한 식으로 mini-batch에 적용해 평균 0, 분산이 1이 되도록 정규화합니다.
그림으로 보면 layer1의 결과가 layer2의 input이 되는 구조입니다. 그리고 두 번째 그림을 보면 데이터가 정규화된 모습을 볼 수 있는데 저 파란색 화살표가 Batch Normalization이라고 볼 수 있습니다.
Batch Normalization은 위 식의 방법으로 normalization을 진행합니다. Batch Normalization은 활성화 함수 이전에 사용되기 때문에 마지막 scale and shift부분이 있습니다. β, γ라는 두 문자가 존재하는데 γ은 scaling 하기 위해서 존재하고 β는 shifting 하기 위해서 존재합니다. 이 부분이 존재해야 하는 이유를 살펴보겠습니다.

그림과 같이 scale and shift 하기 전에 데이터는 오른쪽 그림에 존재하는 빨간색 상자에 대부분 존재합니다. 그렇게 된다면 non-linearity가 떨어지게 되므로 데이터를 적절히 scale and shift를 해줍니다.
이와 같은 방법으로 학습 속도를 향상할 수 있습니다. Batch Normalization을 통해 CNN의 성능이 향상되었습니다. 하지만 Batch Normalization은 RNN에서는 좋지 못한 방법입니다. 왜냐하면 RNN에서는 각 단계마다 서로 다른 통계치를 갖는데, 이는 매 단계마다 레이어에 별도의 Batch Normalization을 적용해야 한다는 뜻입니다. 이렇게 되면 모델은 더 복잡해지고 계속 새롭게 형성된 통계치를 저장해야 합니다. 또한 batch size가 1이라면 분산이 0이므로 정규화를 할 수 없습니다. batch size가 작은 경우 전체 dataset과 비슷한 분포를 가지지 않을 수 있으며 정규화가 제대로 이뤄지지 않을 가능성이 존재합니다.
■ Weight Normalization
Weight Normalization은 mini-batch를 정규화하는 것이 아니라 layer의 가중치를 정규화합니다.

Weight Normalization은 레이어의 가중치 W를 위와 같은 방식으로 변경합니다. Batch Normalization에서 입력값을 표준 편차로 나누어주는 것과 비슷한 효과를 얻습니다. 논문에서 Weight Normalization은 mean-only batch normalization과 함께 사용하기를 제안합니다. 이 방법은 입력을 표준 편차로 나누거나 scale 재조정을 하지 않는 Batch Normalization입니다.
■ Layer Normalization
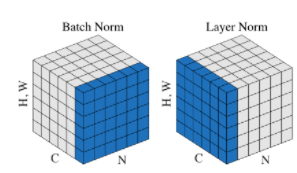
그림에서 볼 수 있듯이 Batch Normalization과 Layer Normalization의 형태는 거의 유사합니다. Batch Normalization은 Batch 차원에서 정규화이지만 Layer Normalization은 feature 차원에서 정규화입니다. Batch Normalization은 batch 전체에서 계산이 이뤄지고 각 batch에서 동일하게 계산됩니다. 하지만 Layer Normalization의 경우 각 feature에 대하여 따로 계산이 이뤄지며, 각 feature에 독립적으로 계산합니다. Layer Normalization은 batch 사이즈에 상관이 없으며 RNN에서 매우 좋은 성능을 보여줍니다.
■ Instance Normalization

Instance Normalization은 Layer Normalization과 유사하지만 한 단계 더 나아가 평균과 표준 편차를 구하여 각 example의 각 채널에 정규화를 진행합니다. image data에 대해 H, W에만 연산을 진행합니다. 이러한 Instance Normalization은 이미지에 국한된 정규화이며, RNN에서는 사용할 수 없습니다.
■ Group Normalization

Group Normalization은 Instance Normalization과 유사합니다. Group Normalization은 채널을 그룹으로 묶어 평균과 표준편차를 구해 연산을 한다는 차이가 있습니다. 간단하게 보면 Instance Normalization의 3묶음을 하나의 group으로 묶어 연산을 하면 Group Normalization이랑 동일하게 됩니다. 그림으로 보면 Instance Normalization과 Layer Normalization의 중간이라고 볼 수 있습니다. Group Normalization은 ImageNet에서 batch size가 32일 때 Batch Normalization과 거의 근접한 성능을 보여줬고 그 보다 더 작은 batch size에 대해서는 더 좋은 성능을 보여줬습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Densely Connected Convolutional Networks (0) | 2022.03.23 |
|---|---|
| [논문]Improving neural networks by preventing co-adaptation of feature detectors (0) | 2022.03.21 |
| Image deblurring using DeblurGAN(실행 결과, 새로운 unet 작성해보기) (0) | 2022.03.10 |
| Image deblurring using DeblurGAN(network, train, test) (0) | 2022.03.10 |
| Image deblurring using DeblurGAN(conditional_gan_model, losses.py) (0) | 2022.03.09 |


