https://arxiv.org/abs/1608.06993
Densely Connected Convolutional Networks
Recent work has shown that convolutional networks can be substantially deeper, more accurate, and efficient to train if they contain shorter connections between layers close to the input and those close to the output. In this paper, we embrace this observa
arxiv.org
해당 논문을 공부하고 작성했습니다.
Abstract

convolution 네트워크들은 점점 깊어지고 정확해지며, shortcut을 이용해 더 효율적으로 학습을 할 수 있게 되었습니다. 이 논문에서는 각각 층에서 다른 모든 층에 연결된 구조를 보여주는 Dense Convolution Network(DenseNet)에 대해서 살펴보겠습니다. 일반적으로 L개의 층을 가진 convolution network는 L개의 연결을 가지지만 DenseNet은 L(L+1)/2개의 직접 연결을 갖습니다. 각각 층에서 이전의 모든 특징 맵들을 input으로 사용하고, 그 자체의 특징 맵은 그다음 모든 층의 input으로 사용됩니다.
이러한 DenseNet은
- vanishing gradient 개선
- feature propagation 강화
- feature reuse
- parameter 수 절약
이와 같은 장점이 있습니다.
Introduction

Convolutional neural networks(CNNs)는 이미지 객체 인식에 주로 쓰이고 새로운 구조들이 등장하면서 층도 깊어지고 있습니다. CNN의 층이 깊어질수록 새로운 문제들이 발생하고 있고 최근에는 문제들을 해결하기 위한 논문들이 작성되고 있습니다. ResNet과 Highway Networks 등 여러 network 구조들은 이전 층과 다음 층에 short 경로를 생성해 정보를 공유하는 방식을 하면서 문제점들을 해결하고 있습니다. 이 논문에서는 층 사이에 흐르는 정보의 양을 최대로 늘리기 위해 각각의 서로다른 층들(각각 층에서 나온 특징 맵의 크기는 동일하게)을 직접 연결하는 방식을 사용합니다. 피드포워드의 특징을 유지하기 위해 각각의 층은 전에 존재하는 모든 층에서 feature map을 input으로 추가해 다음 층에 전달합니다.
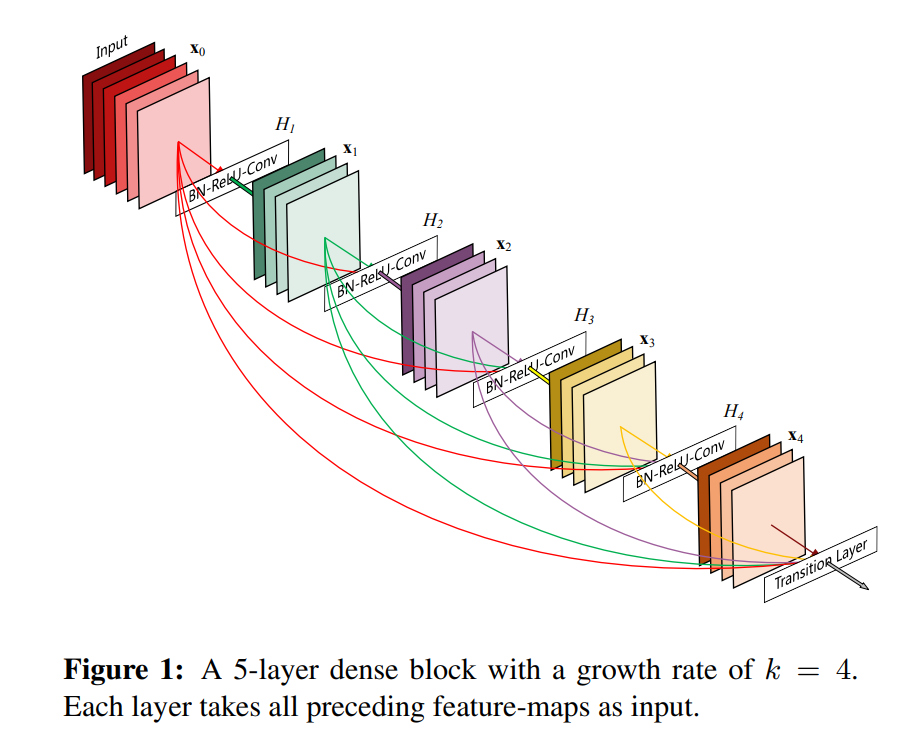
위 그림을 보면 논문에서 사용하는 구조에 대한 개요를 볼 수 있습니다. ResNet과 결정적인 차이가 있는데 전에 통과했던 층에서 오는 feature를 summation 방식으로 결합하는 것이 아닌 concatenating 방식으로 결합합니다. 이런 이유 때문에, L번째 층은 전에 존재하는 모든 특징 맵의 개수인 L개의 input을 갖습니다. 총 L개의 층을 가진 network는 L(L+1)/2개의 연결을 갖습니다. 이러한 dense connectivity pattern 때문에 Dense Convolutional Network(DenseNet)이라고 부릅니다.

dense connectivity pattern 때문에 일반적인 convolutional network보다 더 적은 parameter들을 갖는다고 생각할 수 있습니다(불필요한 특징 맵을 가지고 다시 학습할 필요가 없기 때문에). 일반적인 feed-forward 는 층과 층을 통과하면서 상태를 전달하는 구조이고, 이러한 구조이기 때문에 보존해야 하는 정보도 통과시켜버리는 경우가 존재합니다.
ResNet은 이러한 문제를 해결하기 위해 제안되었지만 각 층에서 각각의 가중치를 가지기 때문에 많은 parameter가 필요합니다. 이 논문에서 제안한 DenseNet 구조는 network에 추가해야 되는 정보와 보존되어야 하는 정보 사이의 명확한 차이점을 가집니다. DenseNet은 network의 다른 부분은 그대로 유지하고 특징 맵에 오직 작은 부분만 추가하며 마지막 분류하는 부분에 모든 특징 맵을 기반으로 결정하게 만들어줍니다.
게다가 DenseNet은 매개변수 효율뿐만 아니라, 쉽게 학습할 수 있도록 network 내내 gradient와 정보의 흐름이 향상되었습니다. 각 층은 손실함수와 원래 input 신호를 직접적으로 액세스해 암묵적으로 심층 감시를 유도하는데 이는 깊은 network 구조에서의 학습에 도움이 됩니다. 또한 Dense 연결은 작은 training set으로 인해 발생하는 overfitting을 줄여주는 정규화 효과도 존재합니다.
Related Work

요즘 network에서 계층의 수가 증가함에 따라 아키텍쳐 간의 차이가 증가되고 다양한 연결 패턴을 연구하고 예전 연구 아이디어를 다시 보고 있는 추세입니다. 이 논문에서 제시하는 DenseNet 계층과 유사한 계단식 구조도 1980년대에 이미 연구되었습니다. 1980년대에 제안된 계단식 구조는 fully connnected에 대해 연구되었고 CNN은 skip-connections을 통해 효과가 증가되었습니다. 그 이후에 GoogLeNet, ResNet 등 여러 구조가 연구되고 구현되었습니다.
DenseNets

x_0라는 한장의 이미지가 convolution network를 통과한다고 생각해보겠습니다. network는 L개의 계층으로 구성되어 있고, 각 층은 비선형 변환 H를 구현합니다. H는 Batch Normalization(BN)과 같은 함수와 결합할 수 있고, ReLU, Pooling, 또는 Convolution과 결합할 수 있습니다. 그리고 L번째 층에서 결과 x_l로 표현할 수 있습니다.

일반적인 convolution 피드 포워드 networks는 L번째 층의 output을 (L+1)번째의 input으로 연결됩니다. 식으로 나타내면 위와 같이 x_L = H_L(x_(L-1))로 표현할 수 있습니다. ResNet은 skip connection을 추가해 식으로 표현하면
x_L = H_L(x_(L-1)) + x_(L-1)가 됩니다. 이런 ResNet의 장점은 기울기가 하위 계층에서 더 앞 계층으로 항등 함수(정의역인 모든 원소 x에 대해 f(x) = x인 함수)를 통해 바로 연결된다는 점입니다. 하지만 항등 함수와 ouput인 H_L은 summation으로 결합되는데, 이는 network에서 정보의 흐름을 지연시킬 수 있습니다.

이 논문에서 제시한 다른 연결 방식(어떤 층에서 그 이후의 모든 층에 직접 연결되는 방식)은 층들의 사이에서 정보의 흐름을 향상시킵니다. L번째 층은 모든 이전의 층들의 특징 맵을 input으로 받고 식으로 표현하면 위와 같습니다. H()에 들어오는 input을 단일 텐서로 만들어 적용합니다.

H(x)는 batch normalization, ReLU, 3x3 covolution으로 구성됩니다. concatenation을 하기 위해서 feature map의 크기는 변경되지 않아야 합니다. 그러나 convolution networks에서 feature map의 크기를 줄이는 down-sampling은 필수적인 부분입니다. 그래서 down-sampling이 가능하게 하기 위해 network를 dense blocks(여러 densely 연결이 있는)으로 나눴습니다.
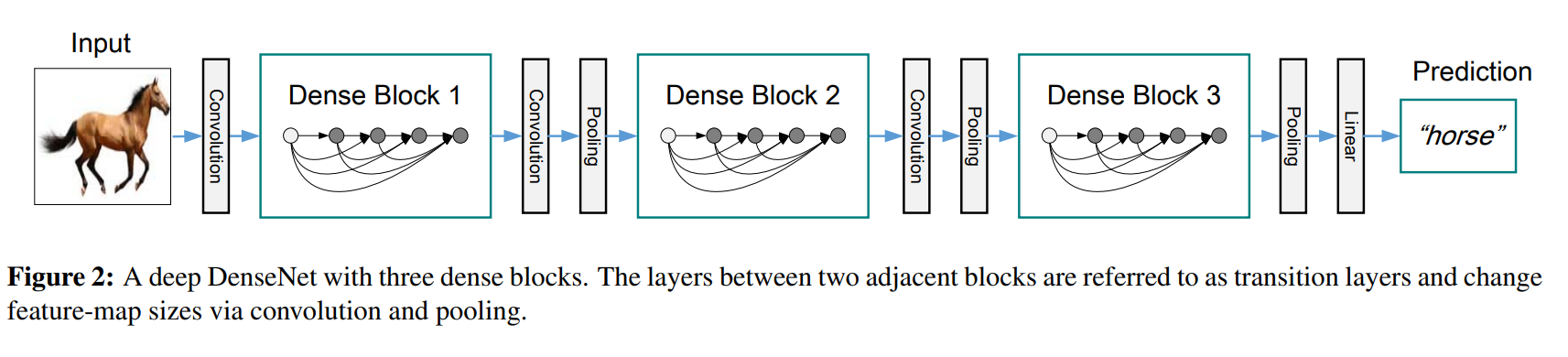
위 그림을 보면 dense block을 볼 수 있습니다. block들 사이에 transition layer라 불리는 연결이 적용되는데, 이는 convolution을 하고 pooling 하는 layer입니다. transition layer는 batchnormalization layer과 1x1 convolutional layer, 2x2 average pooling layer로 구성됩니다.

l번째 layer는 k_0 + k*(l-1)개의 input feature map을 가지는데 여기서 K_0는 input layer의 채널 수입니다. DenseNet과 존재하는 다른 network 아키텍처들과 다르게 매우 narrow 한 layer를 가질 수 있습니다. 하이퍼 파라미터인 k는 network의 growth rate를 의미합니다. 상대적으로 작은 k값으로 충분히 좋은 결과를 가질 수 있다는 것을 확인할 수 있는데 각 layer들이 block 내에 있는 모든 이전 feature map에 접근하여 collective knowledge에 접근할 수 있음을 의미합니다. feature map을 네트워크 전역의 state로 볼 수 있고, 각 계층은 전역 state에 k개의 feature map을 추가하는 것으로 볼 수 있습니다. growth rate는 각각의 계층의 정보를 global state에 얼마나 줄지 조절하는 역할을 합니다. 이렇게 한번 추가된 global state는 어디에서나 접근할 수 있기에 계층 간 복제를 할 필요가 없습니다.

각각 계층은 output인 k개의 feature map을 제공하는데, 이는 일반적으로 input보다 훨씬 많습니다. input으로 들어가는 feature map의 수를 줄이기 위해 각 3x3 convolution 이전에 1x1 convolution을 넣어 층을 구성하는 것을 bottleneck layer라 부르는데 이를 사용하면 특히 densenet에서 효율적입니다. 그래서 DenseNet-B라고 불리는 bottleneck을 적용한 H()를 만들었는데 이는 Batch Normalization -> ReLU -> Conv(1x1) -> Batch Normalization -> ReLU -> Conv(3x3) 구조로 이루어집니다.

transition layer에서 feature map의 수를 줄일 수 있습니다. 만약 dense block이 m 개의 feature map을 포함하고 있다면 transition layer는 [Θm] 개의 output feature map의 수를 발생하는데, 0<Θ≤1 사이의 값으로 정해집니다. 만약 Θ = 1인 경우, feature map의 수는 달라지지 않습니다. DenseNet에 Θ < 1인 값을 적용하고 이를 DenseNet-C이라 하고, 이 논문에서 Θ = 0.5로 설정하고 실험했습니다. bottleneck과 transition layer(Θ<1) 둘 다 적용하면 DenseNet-BC라 부릅니다.

ImageNet을 제외한 나머지 데이터셋에 대한 실험에서 사용한 DenseNet은 모두 같은 layer수로 구성된 3개의 dense block을 갖습니다. 첫 dense block에 들어가기 전에 16개의 feature map을 출력하는 3x3 convolution이 수행됩니다. 그리고 feature map의 크기를 고정하기 위해 1 pixel 크기의 zero padding을 합니다. 이어서 오는 두 dense block 사이에 1x1 convolution -> 2x2 average pooling layer로 구성되는 transition layer가 있습니다. 마지막 dense block의 마지막에 global average pooling 이 존재하고 softmax 분류를 붙입니다. 3개의 dense block의 feature map의 크기는 각각 32x32, 16x16, 8x8입니다.
basic DenseNet은 {L = 40, k = 12}, {L = 100, k = 12}, {L = 100, k = 24}로 실험할 거고
DenseNet-BC는 {L = 100, k = 12}, {L = 250, k = 24}{L = 190, k = 40}로 실험할 것입니다.
ImageNet을 이용한 실험은 DenseNet-BC 구조를 이용하면서 4개의 dense block을 224x224 크기의 input image에 적용할 것입니다. 각각의 convolution layer는 2k, 7x7 convolution(stride = 2)로 구성됩니다.
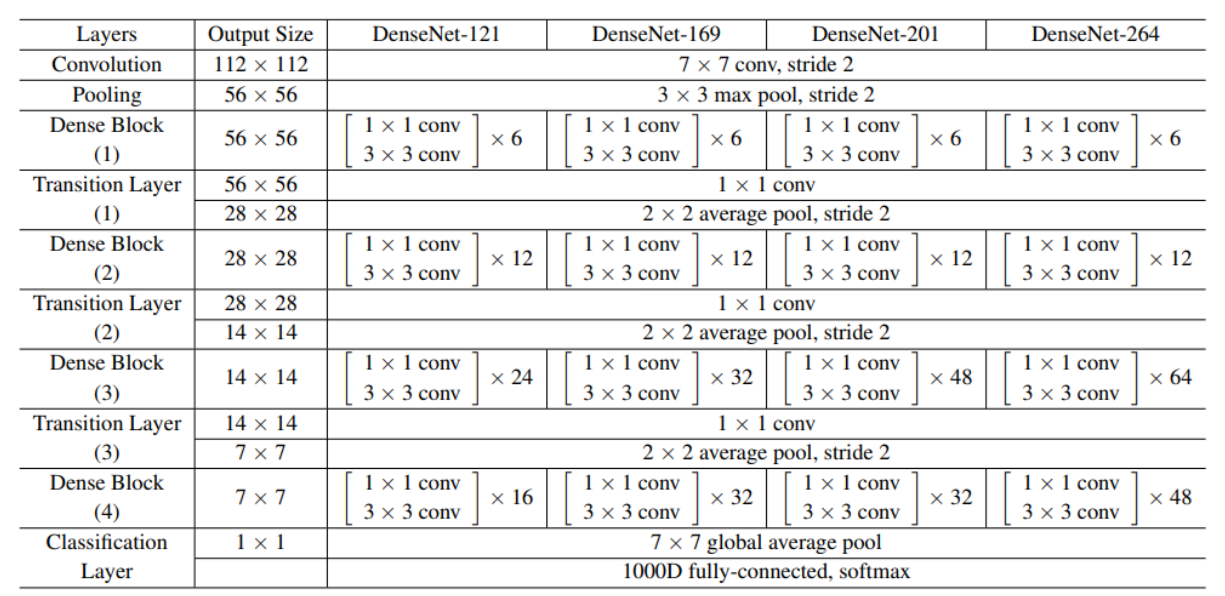
위 표를 보면 ImageNet에 대한 구조를 볼 수 있습니다.
Experiments
실험 dataset으로 CIFAR, SVHN, ImageNet을 이용합니다. 학습 때는 모든 network에 Stochastic Gradient Descent를 적용하고 CIFAR와 SVHN에 batch size는 64, 각 300, 400 epoch을 적용합니다. 첫 learning rate는 0.1로 설정하고 train epoch이 50% 일 때, 75% 일 때 learning rate를 10으로 나눠줍니다. ImageNet에서는 90 epoch, 256 batch size을 사용합니다. learning rate는 0.1로 시작하고 epoch 30, 60일 때 줄입니다.

위 그래프는 ImageNet을 이용해 test 한 결과를 보여주는데 가장 높은 error 비율을 y축으로 나타내고 왼쪽은 학습된 parameter 수를 x축으로, 오른쪽은 학습 시간을 x축으로 나타낸 모습입니다. 보면 DenseNet의 성능이 ResNet보다 뛰어난 것을 볼 수 있습니다.
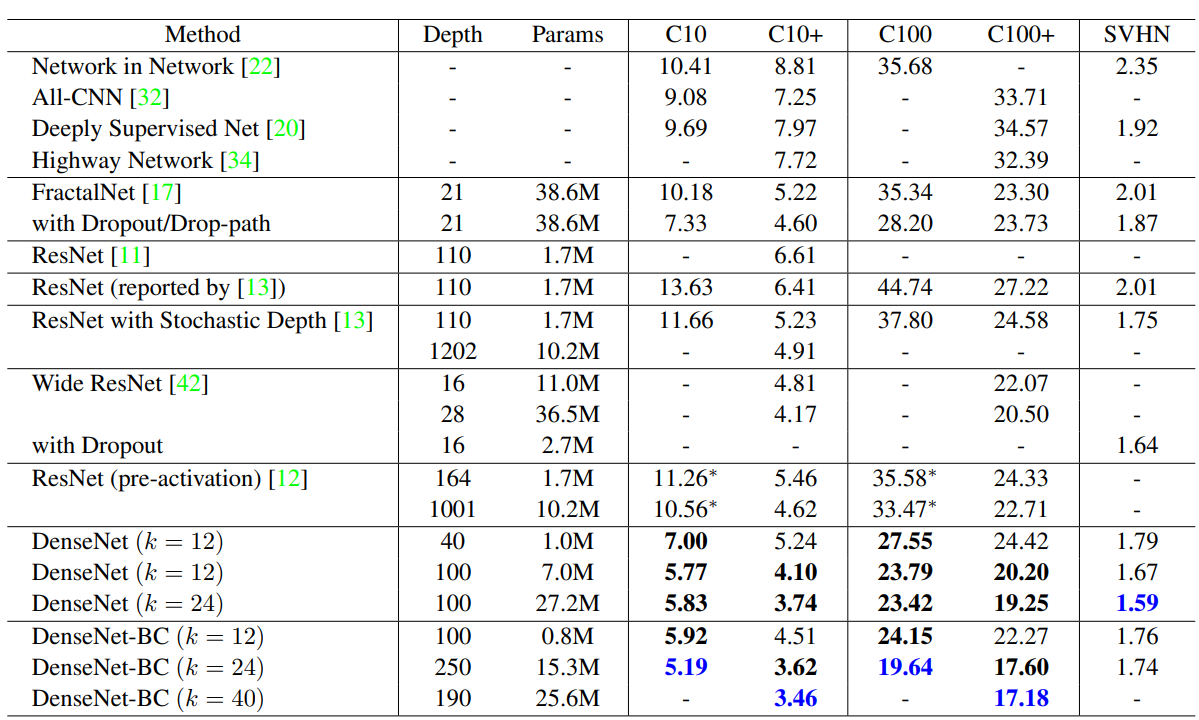
위 표를 보면 좀 더 다양한 결과를 볼 수 있습니다.
결론은 DenseNet은 overfitting, degradation 없이 정확도를 계속해서 개선할 수 있으며 상당히 작은 파라미터 수와 연산량으로 상당히 좋은 성능을 낼 수 있습니다. DenseNet은 identity mapping, deep supervision, diversified depth를 통합하여 네트워크 전역에서의 feature reuse를 가능하게 했고 했습니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Unet++ : A Nested U-Net Architecture for Medical Image Segmentation (0) | 2022.03.28 |
|---|---|
| DenseNet 코드 (0) | 2022.03.24 |
| [논문]Improving neural networks by preventing co-adaptation of feature detectors (0) | 2022.03.21 |
| 정규화(Normalization) (0) | 2022.03.14 |
| Image deblurring using DeblurGAN(실행 결과, 새로운 unet 작성해보기) (0) | 2022.03.10 |



