https://arxiv.org/abs/1207.0580
Improving neural networks by preventing co-adaptation of feature detectors
When a large feedforward neural network is trained on a small training set, it typically performs poorly on held-out test data. This "overfitting" is greatly reduced by randomly omitting half of the feature detectors on each training case. This prevents co
arxiv.org
해당 논문을 공부하고 작성했습니다.
논문 본문

작은 training data set으로 학습을 진행할 경우 성능이 저하됩니다. training case에서 각 특징의 절반을 랜덤하게 생략하면 과적합(overfitting)은 감소됩니다. 이렇게 하면 몇 개의 특징에만 효과적인 overfitting을 예방할 수 있습니다. 랜덤한 드롭아웃은 벤치마크 테스크를 크게 발전시키고, 음성과 사물 인식에 새로운 기록을 작성할 수 있도록 했습니다.
피드포워드와 인공 신경망은 input과 output 사이에 비선형 hidden layer를 사용합니다. hidden unit에서 들어오는 연결들의 가중치를 조정함으로써 input이 주어졌을 때 올바른 output을 예측할 수 있습니다. 만약 input과 정확한 output 사이에 관계가 복잡하고 hidden units의 정확도가 높다면 training set을 거의 완벽하게 modeling 하는 많은 가중치들이 있을 것이고 특히 제한된 training data 양일 경우 더 그러할 것입니다. model은 test data가 아닌 training data에 대해 정확하게 결과를 보일 수 있도록 설정되어 있으므로 각각의 가중치 벡터는 test data에 대해 서로 다른 예측을 할 것이고, training data보다 test data에 대해 좋지 않은 결과를 보일 것입니다.
overfitting은 dropout을 사용함으로써 감소될 수 있습니다. 각각의 training case에 대해 0.5의 확률로 랜덤하게 hidden unit을 제외하고, hidden unit은 다른 hidden units들에 영향을 받지 않습니다. test set에 대한 에러를 줄이는 좋은 방법은 많은 다른 networks의 예측의 평균을 구하는 것입니다. 이렇게 평균을 구하기 위한 일반적인 방법은 많은 개별 네트워크를 훈련하고 test data에 네트워크를 각각 적용하는 것이지만 훈련과 테스트 모두에서 계산 비용이 많이 듭니다. 랜덤 dropout은 수많은 다른 networks에 대한 학습을 적정한 시간 내에 할 수 있도록 해줍니다. 각각의 training case에 대해 다른 network가 존재하지만 모든 network에서 사용되는 hidden units에 같은 가중치를 사용합니다.
지금까지 나온 dropout의 장점은
- overfitting을 예방
- 컴퓨터 자원을 절약
training case의 mini-batch에 dropout neural network를 학습하기 위해 일반적으로 SGD를 사용하는데, 가중치가 과도하게 커지는 것을 예방하기 위해 사용되는 penalty term을 수정합니다. 모든 가중치에 대해 penalizing에 사용되는 L2 norm대신에 각각의 개별적인 hidden unit에 입력으로 들어오는 가중치에 대한 L2 norm의 상한선을 설정해 사용합니다. 만약 가중치 업데이트가 제약을 위반하는 경우 개별의 hidden unit의 가중치를 정규화합니다. 이러한 방식이면 가중치가 과도하게 커지는 것을 예방할 수 있습니다. 이는 매우 큰 learning rate로 시작하는 것을 가능하게 합니다. 이렇게 큰 learning rate로 학습을 시작한다면 작은 learning rate와 작은 가중치를 사용해 시작하는 경우보다 weight를 더 넓은 범위로 찾아갈 수 있습니다.
성능 측정
MNIST를 이용해 dropout의 효과를 측정하겠습니다. MNIST는 60000장의 28x28 training images와 10000장의 test image가 존재합니다. 아무런 트릭 없이 일반적인 피드포워드 neural network를 이용해 test set에 대한 가장 좋은 결과를 얻은 경우 160개의 에러가 발생했습니다. 각각의 L2 제약이 걸린 hidden unit의 가중치에 50%의 dropout을 적용한 결과 130개의 에러로 줄일 수 있었고, 픽셀에 랜덤하게 20% 드롭해 110개의 에러로 줄일 수 있었습니다.

위 그래프가 결과를 보여줍니다.
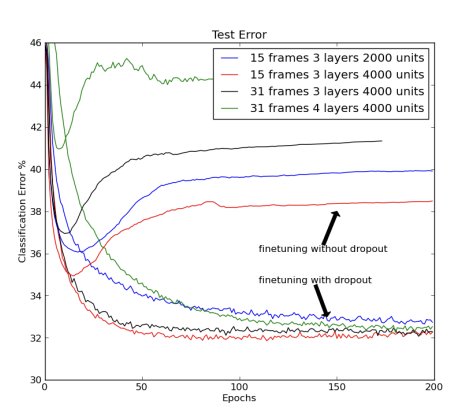
위 그래프는 윈도우의 중앙 프레임이 neural net에 의해 가장 높은 확률로 부여되는 HMM 상태라고 분류되었을 때 TIMIT 벤치마크의 코어 테스트 세트의 프레임 분류에 대한 오차율을 그리고 있습니다. 50% 확률의 dropout을 hidden units에 적용한 경우 다양한 다른 네트워크 아키텍처에서 상당히 향상된 모습을 보입니다.

CIFAR-10은 객체 인식에 사용되는 벤치마크입니다. 이는 웹에서 클래스 이름으로 검색하거나 하위 클래스로 검색해 찾은 10개의 다른 객체 클래스의 32x32 다운샘플링된 컬러이미지를 사용합니다. 이미지들은 label된 50000장의 training images와 10000장의 합리적으로 하나의 class로 분류할 수 있는 test image로 구성됩니다.

위 이미지는 test image에 대한 예시입니다. 변형없이 사용된 test set에 대해 가장 좋은 오차는 18.5%입니다. 3개의 convolution layer와 3개의 max-pooling layer을 적용해 오차를 16.6%까지 줄였습니다. 마지막 hidden layer로 dropout을 사용한 결과, 15.6%의 오차를 보여줍니다. 즉, dropout을 이용해 결과를 향상했다는 결과를 보여줍니다.
최종 결과

dropout은 training data가 주어졌을 때 각 모델의 사후 확률에 따라 가중치를 부여하는 베이지안 모델평균법보다 구현하기 상당히 간단합니다. 테스트 시, dropout 결정이 각 유닛에 대해 독립적이라는 사실은 평균 망을 통과하는 단일 패스를 사용하여 기하급수적으로 많은 dropout nets의 결합된 내용을 매우 쉽게 근사할 수 있게 합니다. 이는 수많은 분리된 model의 예측의 평균을 구하는 것보다 훨씬 더 효율적입니다.
친숙하고 극단적인 dropout 중 'naive bayes'가 있는데 training data가 적은 경우 로지스틱 회귀보다 더 잘 작동합니다.
'연구실 공부' 카테고리의 다른 글
| DenseNet 코드 (0) | 2022.03.24 |
|---|---|
| [논문] Densely Connected Convolutional Networks (0) | 2022.03.23 |
| 정규화(Normalization) (0) | 2022.03.14 |
| Image deblurring using DeblurGAN(실행 결과, 새로운 unet 작성해보기) (0) | 2022.03.10 |
| Image deblurring using DeblurGAN(network, train, test) (0) | 2022.03.10 |



