이번 강의는 CNN 구조에서 layer들에서 filter들이 나타내는 내용이 무엇인지에 대해서 알아봅니다.

일단 위에 그림들은 filter를 이미지로 표현하기 위해서 weight들을 0~255로 normalize 하고 bias는 무시한 상태로 출력한 모습입니다. pretrain 된 model의 첫 layer의 filter들의 모습인데 대부분 에지 성분을 보여줍니다. 흰/검으로 길게 늘어선 필터들도 보입니다. 첫 layer의 filter들은 oriented edge나 보색 같은 것들을 찾는다는 것을 볼 수 있습니다. 사실 인간의 시각체계도 oriented edge를 먼저 인식합니다.
filter의 그림이 저렇게 나온다면 과연 filter는 그 이미지를 찾는 것이 맞나?? 임의의 templete vector와 임의의 데이터를 내적해서 어떤 scalar output을 계산한다고 보겠습니다. filter 값을 가장 활성화시키는 input을 생각해보면 input과 weight가 동일한 경우입니다. 내적을 보면 두 값이 같은 경우 내적의 값이 최대가 됩니다. 그렇기 때문에 첫 번째 layer의 가중치를 시각화시키면 첫 번째 layer가 무엇을 찾는지 알 수 있습니다.

이번에는 중간 layer를 본 모습입니다. 해석하기가 더 어려워진 모습입니다. 이 예시는 작은 ConvNet demo network입니다. 이 네트워크에서 첫 번째 layer는 7x7 filter 16개가 있습니다. 두 번째 layer를 보겠습니다. 두 번째 layer까지 수 차례 conv & ReLU를 거칩니다. 두 번째 conv layer는 16 channel의 input을 받습니다. 그리고 20개의 7x7 conv filter가 있습니다. 이 conv filter는 16x7x7입니다. 이런 filter 20개가 있습니다. 이 filter들을 직접 살펴본다고 이해할만한 정보를 얻긴 힘듭니다. 이 두 번째 layer의 filter들은 첫 번째 layer의 output과 연결되어 있고 직접적으로 input image와 연결된 것이 아니기 때문에 무엇을 찾는지는 직관적으로 판단하기 쉽지 않습니다.

이제 마지막 layer를 보겠습니다. cnn의 마지막 layer는 1000개의 class score가 있습니다. 이는 학습 데이터의 predicted score입니다. 그리고 이 마지막 layer 직전에 FC-Layer가 있습니다. 가령 AlexNet의 경우 image를 표현하는 4096-dim vector를 input으로 받아 최종 class score를 출력합니다. 이 4096-dim vector를 시각화하는 것도 좋은 방법입니다.

마지막 layer에 있는 vector를 nearest neighbor을 이용해 시각화하겠습니다. 위에서 제일 왼쪽 그림을 보면 CIFAR-10을 이용해 유사한 그림을 찾아내는 모습입니다. 맨 왼쪽 열이 CIFAR-10으로 학습시킨 image입니다. 오른쪽 5열의 이미지는 test set입니다. 일단 두 번째 행에 있는 흰색 강아지를 보겠습니다. 픽셀 공간에서의 nearest neighbor는 흰색 덩어리가 있으면 가깝다고 생각할 것입니다. 굳이 개가 아니더라도 가깝다고 생각할 것입니다. 이런 식으로 거리가 가까운 이미지들을 시각화해보는 방법도 시각화 기법입니다. 다만 pixel 공간에서 nearest neighbor를 계산하는 것이 아닌 CNN에서 나온 4096-dim vector에서 계산하겠습니다.
오른쪽 이미지들에서 제일 왼쪽 열에 있는 사진은 ImageNet classification dataset의 test set입니다. 그리고 나머지 열들은 AlexNet의 4096-dim vector에서 계산한 nearest neighbor의 결과입니다. 이 결과를 보면 확실히 pixel 공간에서의 nearest neighbor과는 아주 다릅니다. feature 공간에서의 nearest neighbor의 결과를 보면 서로 pixel 값의 차이가 큰 경우가 존재합니다. 서로 픽셀값의 차이는 커도 feature 공간 내에서는 아주 유사한 특성을 지내는 것을 알 수 있습니다. 코끼리를 보면 test에서는 코끼리가 왼쪽에 서있습니다. 하지만 3번째 가까운 이미지를 보면 오른쪽에 서있습니다. pixel과는 다른 결과를 보입니다. 즉 network가 학습을 통해서 image의 semantic content 한 특징들을 잘 포착해낸 모습입니다. feature들에게 서로 유사해야 한다고 말해주지 않았지만 스스로 학습을 통해 가까워진 모습입니다.
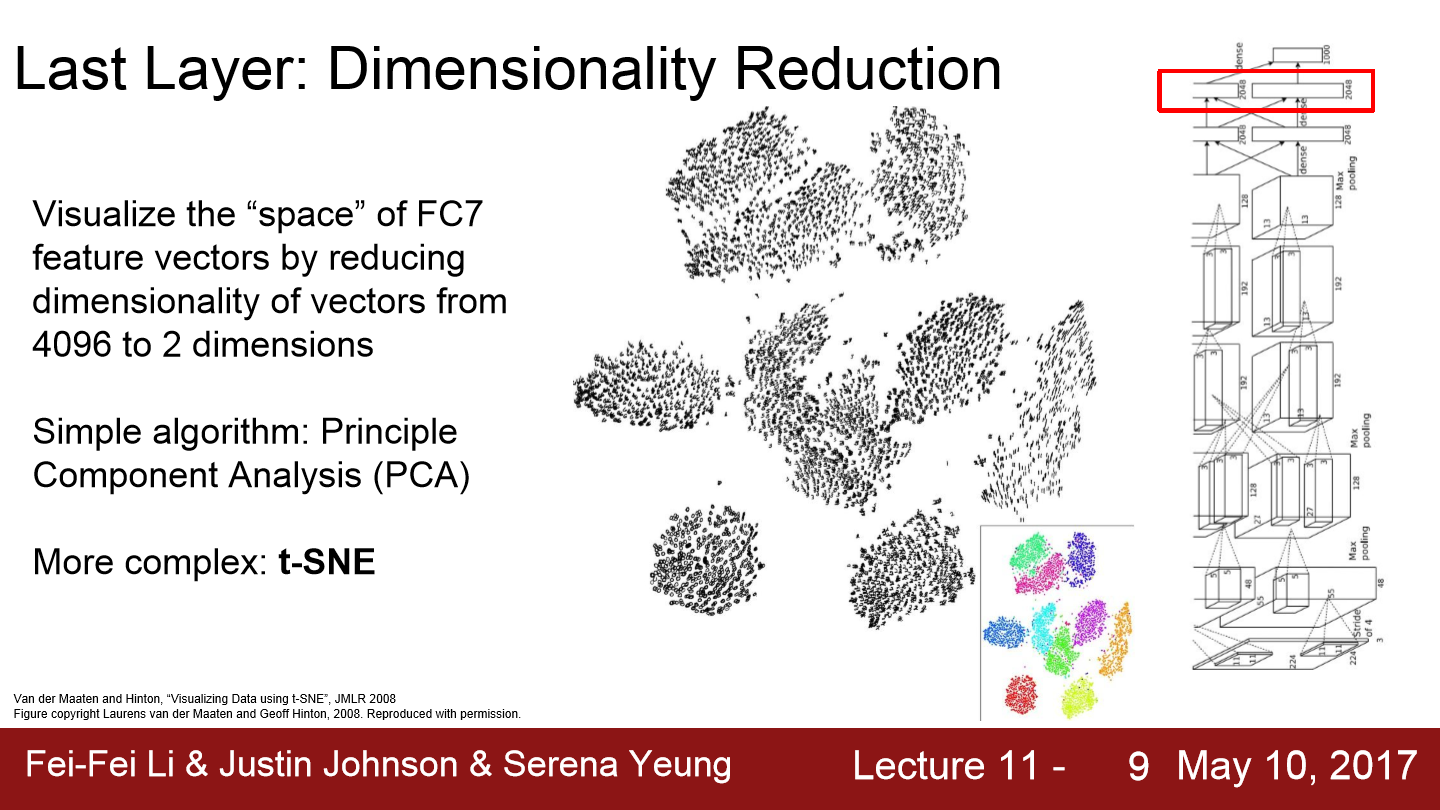
이번에는 dimensionality reduction에 대해서 보겠습니다. PCA는 4096-dim vector와 같은 고차원 vector를 2-dim으로 압축시키는 기법입니다. 이를 통해 feature 공간을 좀 더 직접적으로 시각화가능합니다. 더 powerful 한 방법으론 t-SNE도 있습니다. t-SNE는 t-distributed stochastic neighbor embeddings이라는 뜻을 가지고 있고 많은 사람들이 feature 공간을 시각화하기 위해서 사용합니다. MNIST를 t-SNE를 통해 시각화한 모습을 보면 위와 같이 나와있습니다. MNIST는 0~9의 숫자를 흑백사진으로 나타나 있는 data이고 각 이미지는 28x28입니다. t-SNE가 MNIST를 input으로 받고 이를 2-dim으로 압축하고 이를 시각화하면 위와 같이 자연스럽게 군집화된 모습을 볼 수 있습니다. 각 군집은 MNIST의 각 숫자를 의미합니다.

ImageNet data에서도 진행을 하면 위와 같이 나타납니다. 4096-dim vector들을 t-SNE에 적용하면 2-dim으로 압축이 됩니다. 이 데이터들을 통해 학습된 feature 공간의 기학적인 모습을 어렴풋이 추측해볼 수 있습니다. 위 그림을 보면 한쪽에는 식물들, 한쪽에는 강아지들, 한쪽에는 고양이들 등 다양한 동물들끼리 모여있고 다양한 지역들이 모여있습니다. 이를 통해 우리가 학습시킨 feature 공간에는 일종의 불연속적인 의미론적 개념이 존재한다는 것을 알 수 있습니다.
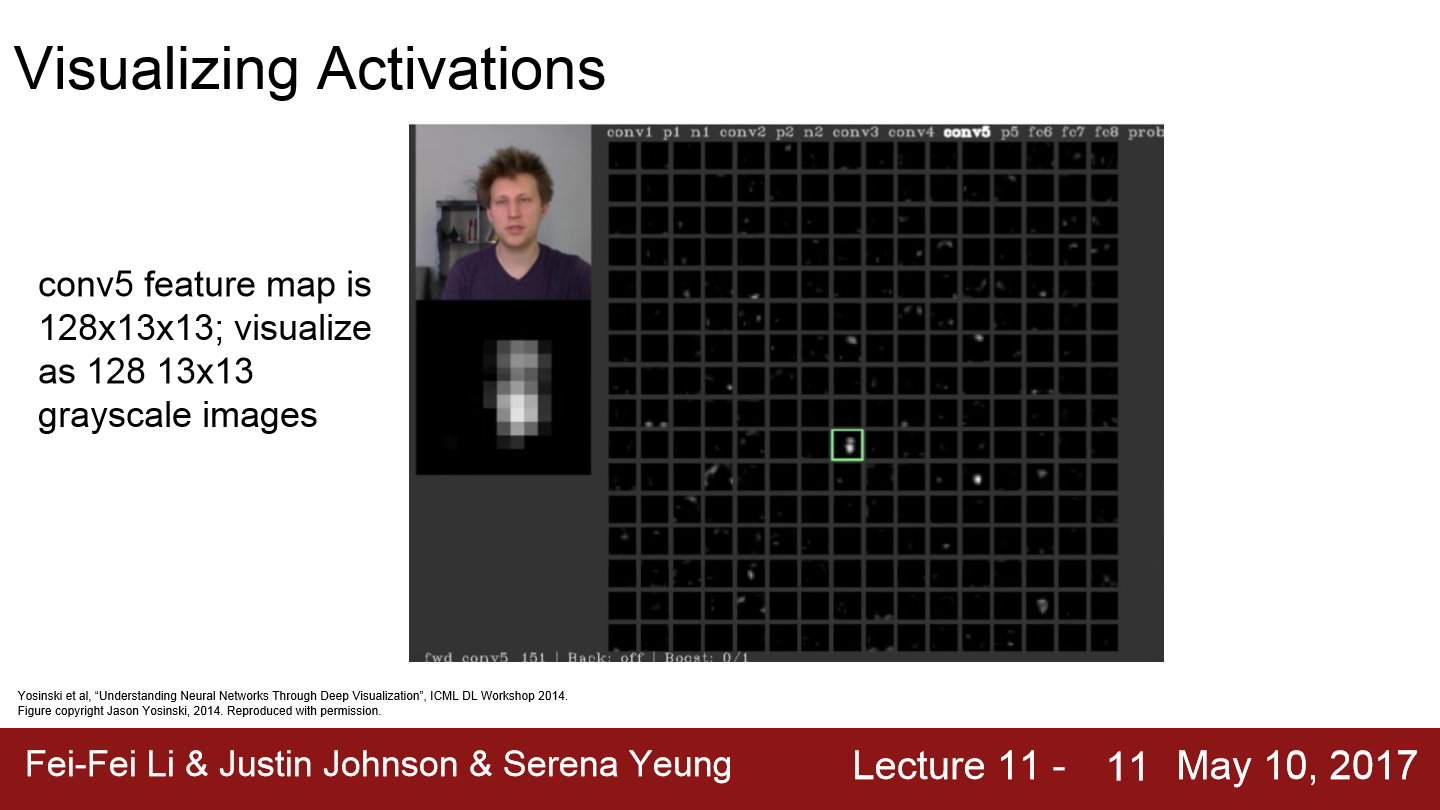
이번에는 중간 layer의 가중치가 아니라 activation map을 시각화해봤습니다. AlexNet의 conv5의 특징은 128x13x13-dim tensor입니다. 이 tensor는 128개의 13x13 2-dim grid로 볼 수 있습니다. 따라서 이 13x13 feature map을 그레이 스케일 이미지로 시각화할 수 있고 위와 같이 시각화할 수 있습니다. 이 결과는 conv layer가 input에서 어떤 특징을 찾고 있는지 짐작해볼 수 있습니다. 네모박스를 보면 사람의 얼굴에 활성화되는 것처럼 보입니다. 즉 네트워크의 어떤 레이어는 사람의 얼굴을 찾고 있는지 모른다는 것을 알 수 있다.

이번 방법은 어떤 이미지가 들어와야 각 뉴런들(activation map의 하나의 scaler)의 활성이 최대화되는지를 시각화해보는 방법입니다. 이번에도 AlexNet을 사용하고 conv5는 128x13x13 한 덩어리의 activation volume을 갖습니다. 이제 이 128개의 channel 중 17번째 channel을 선택합니다. 그리고 많은 이미지들을 CNN에 통과시킵니다. 그리고 각 이미지의 conv5 feature를 기록합니다. 그 다음그다음 어떤 이미지가 17번째 feature map을 최대로 활성화시키는지를 살펴봅니다. 이미지 전체를 보지 않고 특정 layer의 feature를 최대화시키는 이미지의 일부분을 시각화시키는 과정이라 볼 수 있습니다. 그리고 layer의 activate 정도를 기준으로 패치들을 정렬시킨 모습이 위와 같습니다. 첫 사진을 보면 input image에서 어떤 푸르스름하고 둥근 물체를 찾는 것처럼 보입니다. 그다음 행을 보면 다양한 color의 orientation을 가진 휘어진 edge를 찾는 것처럼 보입니다.

이번에는 input image에서 어떤 부분이 이미지 분류를 결정짓는 근거가 되는지에 대한 실험입니다. input image에서 일부를 가립니다. 그리고 가린 부분을 datset의 평균으로 채워버립니다. 이 가려진 image를 network에 통과시켜 network가 image를 예측한 확률을 기록합니다. 그리고 이 가림막을 전체 이미지에 대해 돌아가면서 같은 과정을 반복해 확률 변화를 확인합니다. 위와 같이 확률들을 볼 수 있습니다. go-kart를 보면 카트를 가렸을 때 go-kart로 분류할 확률이 떨어진 것을 알 수 있습니다. 즉 네트워크가 이미지 분류를 결정할 때 go-kart가 실제로 영향을 많이 준다는 것을 알 수 있습니다.

이번에는 gradient ascent에 대해 설명합니다. 어떤 뉴런을 활성화시킬 수 있는 일반적인 input image를 만들어내는 방법입니다. 지금까지 loss를 최소화시켜 network를 학습시키기 위해 gradient descent를 사용했습니다. 하지만 여기에서는 network의 가중치들을 전부 고정시킵니다. 그리고 gradient ascent를 통해 중간 뉴런 혹은 클래스 스코어를 최대화 시키는 이미지 픽셀들을 만들어냅니다. gradient ascent는 네트워크의 가중치를 최적화하는 방법이 아니라 뉴런 또는 클래스 스코어가 최대화될 수 있도록 input image의 pixel을 변경하는 방법입니다.
이 방법은 regularization term이 필요합니다. 지금까지 regularization은 가중치들이 학습 데이터로의 과적합을 방지하기 위해 사용되었습니다. 여기서는 생성된 이미지가 특정 network의 feature에 과적합되는 것을 막기 위해 사용됩니다. regularization term을 추가함으로써, 이미지가 특정 뉴런의 값을 최대화시키는 방향으로 생성되길 기대하고 생성된 이미지가 자연 영상에서 일반적으로 볼 수 있는 이미지이길 기대할 수 있습니다.

gradient ascent를 사용하기 위해서 초기 이미지가 필요합니다. 이 이미지는 zeros, uiform, noise 등으로 초기화시켜줍니다. 초기화하고 나면 이미지를 네트워크에 통과시키고 여분의 관심있는 뉴런의 스코어를 계산합니다. 그리고 이미지의 각 픽셀에 대한 해당 뉴런 스코어의 gradient를 계산하여 backprop을 진행합니다. 여기에서는 gradient ascent를 이용해서 image pixel 자체를 update 합니다.

이와 같이 이미지들을 만들 수 있습니다. 한 class에 초기 image를 설정하는 방법에 따라 4가지의 image가 나온 모습입니다.

이번에는 각 layer마다 적용을 한 모습입니다. 각 layer들이 찾는 이미지가 있다는 것을 볼 수 있습니다.

위 이미지 8개는 전부 식료품점입니다. 가장 상위의 이미지들은 선반 위에 전시된 물건들을 클로즈업한 것 같아 보입니다. 그리고 하단의 이미지들은 사람들이 식료품점을 돌아다니고 있는 모습인 것 같습니다. 두 종류의 사진들 모두 식료품점으로 labeling 됩니다. 서로 상당히 다르게 생겼지만 같은 label로 labeling 되는데 많은 클래스들이 이렇게 multimodality를 가지고 있습니다. 이미지를 생성할 때 이런 식으로 multimodality를 명시하게 되면 아주 다양한 결과를 얻을 수 있습니다.

이미지 픽셀의 gradient를 이용해서 이렇게 이미지를 합성하는 방법은 아주 좋았습니다. 이제 이를 통해 새로운 시도를 합니다. 네트워크를 속이는 image를 만드는 것입니다. 우선 image 하나를 고릅니다. 코끼리 이미지를 골랐을 때 네트워크가 이 이미지를 코알라로 분류하도록 이미지를 조금씩 변경합니다. 이미지를 변경해 network가 코알라로 분류한 모습을 위 그림을 통해 볼 수 있습니다. 사실 우리에게는 별반 차이가 없어 보입니다. 즉 우리가 보는 것과 다른 무언가가 있다는 뜻입니다.

이번에는 DeepDream입니다. DeepDream에서는 input image를 CNN의 중간 layer까지 어느 정도 통과시킨 후 backprop을 진행합니다. 해당 layer의 gradient를 activation값으로 설정합니다. 그리고 backprop을 하여 이미지를 업데이트합니다. 이 과정을 반복하면 network에 의해 검출된 해당 image의 feature들을 증폭시키는 기능을 합니다. 해당 layer의 어떤 feature들이 있던지 그 feature들을 gradient로 설정하면 이는 network가 image에서 뽑아낸 특징들을 더욱 증폭시키는 역할을 하는 것입니다.

위 이미지는 ImageNet train data를 가지고 학습한 network에 대해서 증폭시켜 시각화한 모습입니다. 그러다 보니 개에 대한 내용이 자주 나옵니다.

이번에는 다른 layer를 가지고 시각화한 모습입니다. 다른 결과를 보여줍니다. 좀 더 얕은 층의 layer를 가지고 시각화한 모습입니다. 그러다보니 에지나 소용돌이무늬와 같은 것들이 보입니다.

이번에는 feature inversion입니다. 어떤 이미지가 있고 이 이미지를 network에 통과시킵니다. 그리고 network를 통과시킨 activation map을 저장합니다. 그리고 이 activation map을 가지고 이미지를 재구성합니다. 해당 layer의 faeture vector로부터 image를 재구성하면, 이미지의 어떤 정보가 feature vector에서 포착되는지를 짐작할 수 있습니다. 이 방법 또한 regularizer를 추가한 gradient ascent를 사용합니다. 대신, feature vector 간의 거리를 최소화시키는 방법을 이용합니다. 그리고 total variation regularizer는 상화좌우 인접 픽셀 간의 차이에 대한 페널티를 부여하기 위해 작성한 부분이고 이를 통해 생성된 이미지가 자연스러운 이미지가 됩니다.

위 예시는 feature inversion을 통한 시각화 예제입니다. 왼쪽은 원본 이미지입니다. 코끼리와 과일 이미지가 있습니다. 이 image를 VGG-16에 통과시킵니다. 그리고 feature map을 기록하고 feature map과 부합하도록 새로운 이미지를 합성합니다. 다양한 layer를 이용해서 합성한 이미지들을 통해 얼마나 많은 정보들이 저장되어 있는지를 짐작해 볼 수 있습니다. 위 예시에서 ReLU 2_2를 거쳐서 나온 feature map을 통해 재구성한 이미지를 보면 거의 완벽하게 구현됩니다. 이를 통해 ReLU2_2에서는 image 정보를 엄청 많이 날려버리지는 않는다는 사실을 알 수 있습니다. 그럼 좀 더 깊은 ReLU 4_3, ReLU 5_1을 가지고 재구성을 해보겠습니다. 재구성된 이미지를 보면 이미지의 공간적인 구조는 잘 유지되고 있지만 디테일은 많이 사라졌습니다. 정확히 어떤 픽셀인지, 어떤 색인지 등을 알아보기 어렵습니다. 낮은 레벨의 디테일들은 네트워크가 깊어질수록 control 됩니다. 이를 통해 network가 깊어질수록 pixel 값이 정확히 얼마인지와 같은 저수준의 정보들은 전부 사라지고, 대신에 색이나 텍스처와 같은 미세한 변화에 더 강인한 의미론적 정보들만 유지하려 하는 것일 수 있다 말합니다.

이번에는 texture synthesis에 대한 내용입니다. 먼저 nearest neighbor방법이 나옵니다. 이 방법은 현재 생성해야 할 pixel 주변의 이미 생성된 픽셀들을 살펴봅니다. 그리고 input 패치에서 가장 가까운 pixel을 계산하여 input 패치로부터 한 pixel을 복사해 넣는 방식입니다. 이런 방식은 복잡한 상황에서는 잘 동작하지 않습니다.

그래서 Gram Matrix가 등장합니다. 이 예시는 input texture로 자갈 사진을 줍니다. 이 사진을 network에 통과시킨 후, network의 특정 layer에서 feature map을 가져옵니다. 이렇게 가져온 feature map의 크기는 CxHxW일 것입니다. HxW 그리드는 공간 정보를 가지고 있습니다. HxW의 한 점에 있는 C차원 특징 벡터는 해당 지점에 존재하는 image의 feature를 담고 있다고 할 수 있습니다.

이제 이 feature map을 가지고 input image의 texture를 계산합니다. 우선 feature map에서 서로 다른 두 개의 feature vector를 뽑아냅니다(위처럼 파란색과 붉은색 vector). 각 faeture vector는 C차원 vector가 됩니다. 이 두 vector의 외적을 계산해서 CxC 행렬을 만듭니다. CxC 행렬은 image 내 서로 다른 두 지점에 있는 feature들 간의 co-occurrence를 담고 있습니다. 가령 CxC 행렬의 (i, j)번째 요소의 값이 크다는 것은 두 입력 벡터의 i번째, j번째 요소가 모두 크다는 의미입니다. 이를 통해 서로 다른 공간에서 동시에 활성화되는 feature가 무엇인지 2차 모멘트를 통해 어느 정도 포착해 낼 수 있습니다.
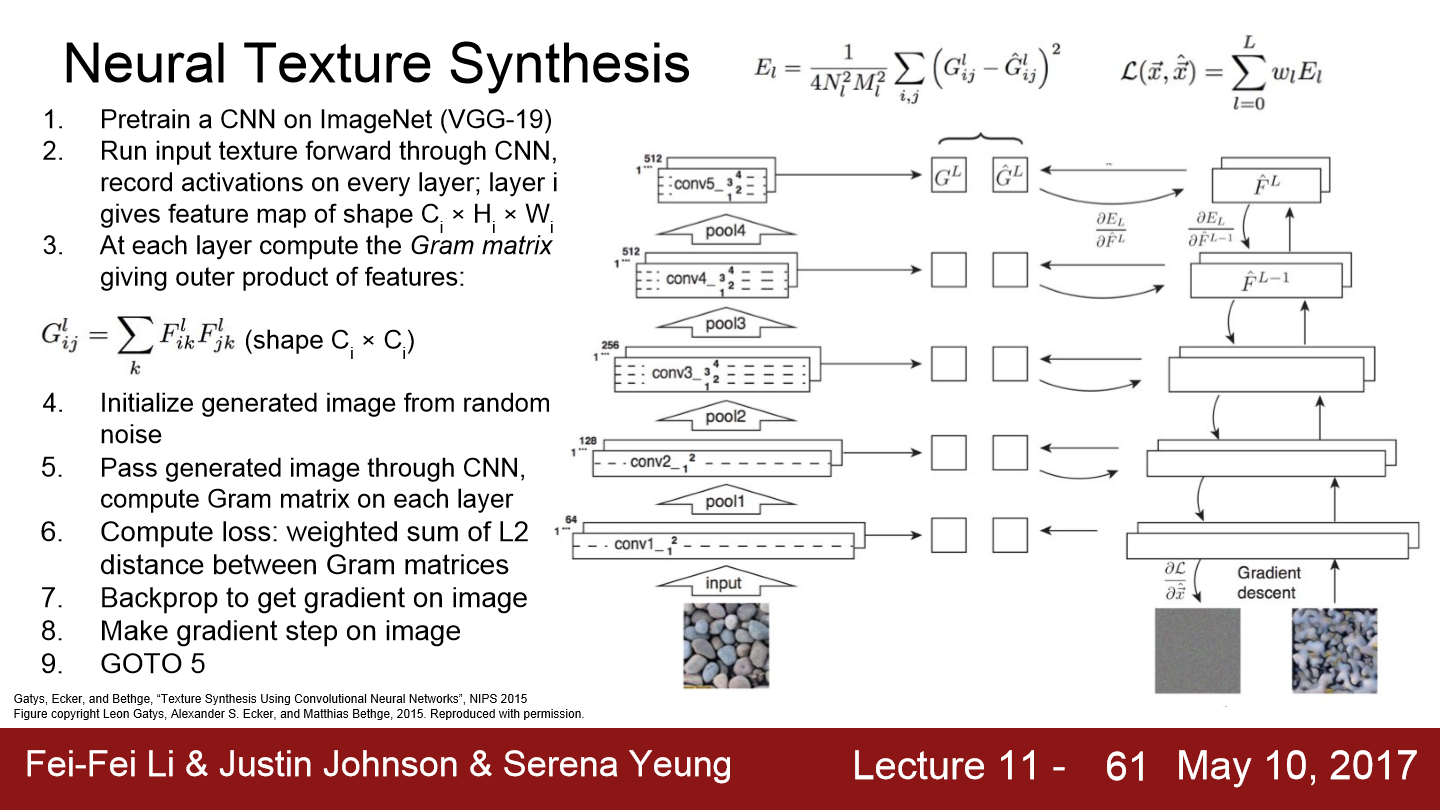
pretrained model에 input image를 넣고 다양한 layer에서 gram matrix를 계산합니다. 그리고 생성해야 할 image를 random으로 초기화시키고 VGG를 통과시킵니다. 그리고 여러 layer에서 gram matrix를 계산합니다. 그리고 원본 이미지와 생성된 이미지의 gram matrix 간의 차이를 L2 norm을 이용해 Loss로 계산합니다. Loss를 backprop 해 생성된 이미지의 픽셀의 gradient를 계산합니다. 그리고 gradient ascent를 통해 image의 pixel을 조금씩 update 합니다. 이 단계를 반복합니다. 다시 앞 단계로 가서 gram matrix를 계산하고, Loss를 계산하고 backprop 합니다. 이 과정을 거치면 결국 input texture와 유사한 texture를 만들 수 있습니다.

이를 보면 아주 잘 texture가 만들어진 것을 볼 수 있습니다. layer가 깊어질수록 더 큼지막한 pattern들이 아주 잘 재구성되는 모습입니다.

이번에는 content image와 style image 두 개의 input을 넣어주고 최종 image는 content image의 feature reconstruction loss도 최소화하고 style image의 gram matrix loss도 최소화하는 방식으로 최적화하여 생성됩니다. 결국 최종 image는 style image 스러운 화풍의 content image가 생성됩니다.

network에 content/style image를 통과시키고 gram matrix와 feature map을 계산합니다. 최종 output image는 random noise로 초기화시킵니다. forward/backward를 반복하여 계산하고 gradient ascent를 이용해 이미지를 update 합니다. 수백 번 정도 반복하면 아주 아름다운 이미지를 얻을 수 있습니다.
style transfer는 deepdream에 비해 이미지를 생성할 때 컨트롤할 만한 것들이 더 많습니다. deepdream의 경우에는 어떤 것들을 만들어낼지 컨트롤할 만한 요수가 많이 부족합니다. 반면 style transfer의 경우 원하는 결과를 만들기 위해 조절할 것들이 좀 더 많습니다. 하나의 content image라고 할 지라도 다양한 style image를 고르게 되면 전혀 다른 image들이 생성됩니다.

또한 hyperparameter를 설정해 마음대로 조절할 수도 있습니다. style/content loss의 joint loss이기 때문에 두 loss의 가중치를 잘 조절해 이미지를 어디에 더 집중해서 만들지를 정할 수 있습니다. 또한 style image를 resizing 해서 넣어주게 된다면 style image의 feature들도 조절되어 들어가게 됩니다.

사실 이런 style transfer에는 문제가 있습니다. image를 만들기 위해 backward/forward를 계속 반복하니까 연산량이 많아지고 아주 느려집니다. 그리고 고화질의 이미지를 만들기 위해서는 더 연산량이 많아지고 더 오래 걸리게 됩니다. 해결책으로 style image는 고정시키고 style transfer를 위한 또 다른 network를 학습시키는 것입니다.
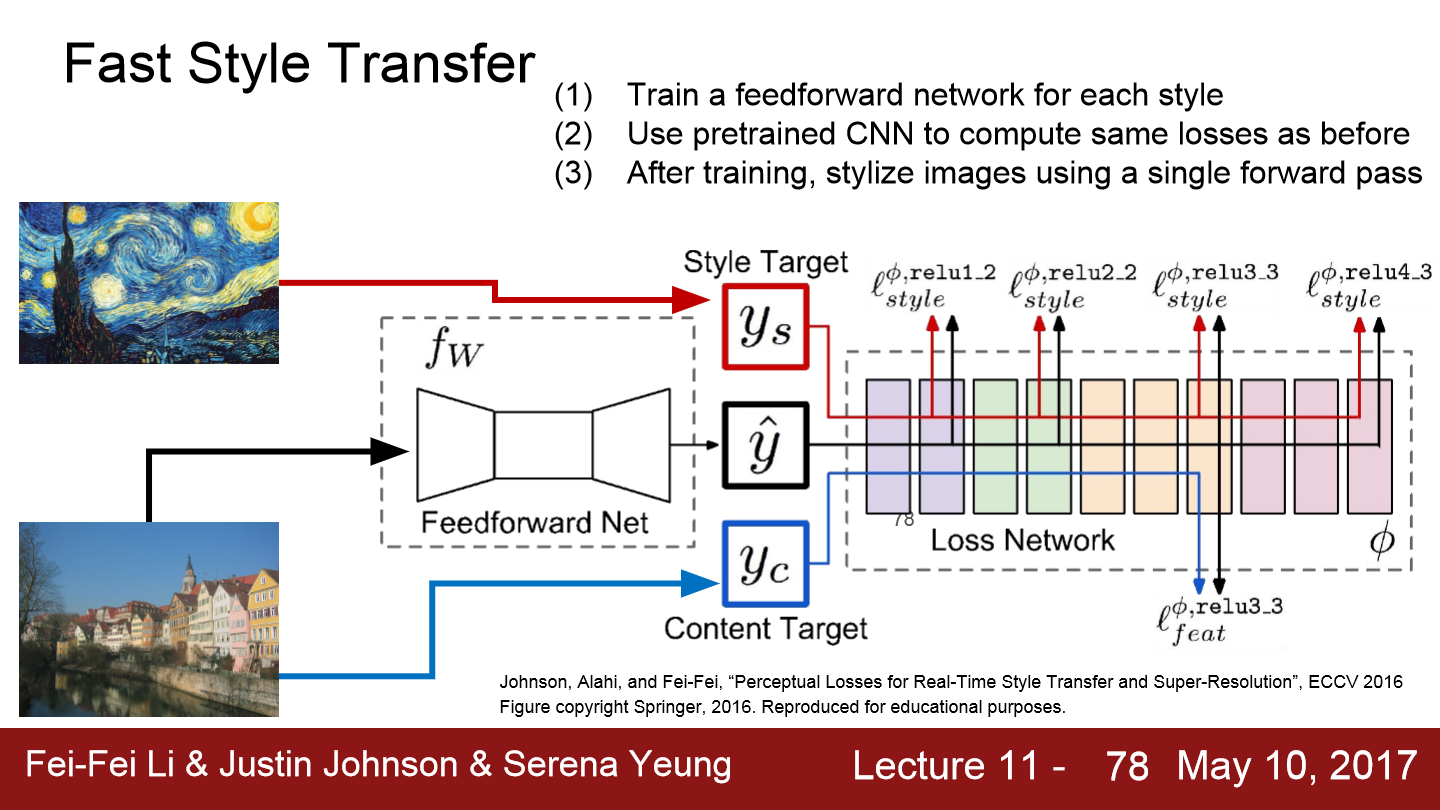
Fast Style transfer 방법은 합성하고자 하는 image의 최적화를 전부 수행하는 것이 아니라 content image만을 input으로 받아서 결과를 출력할 수 있는 단일 network를 학습시키는 방법입니다. 이 네트워크의 학습 시에는 content/style loss를 동시에 학습시키고 network의 가중치를 update 합니다. 학습은 몇 시간이 걸릴 수 있지만, 한번 학습시키고 나면 이미지를 network에 통과시키면 결과가 바로 나올 수 있습니다.

Fast Style Transfer는 style image가 고정이었지만 이번에는 다양한 style로 transfer 가능한 model입니다. network input으로 content image와 style image를 동시에 넣어 하나의 network만으로 실시간 style blending이 가능하게 되었습니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 14. Reinforcement Learning (0) | 2022.07.04 |
|---|---|
| Lecture 13. Generative Models (0) | 2022.07.01 |
| Lecture 11. Detection and Segmentation (0) | 2022.05.21 |
| Lecture 10. Recurrent Neural Networks (0) | 2022.05.19 |
| Lecture 9. CNN Architectures (0) | 2022.05.14 |



