이번 마지막 강의에서는 강화 학습(Reinforcement Learning)에 대해서 배웁니다.

여태까지 배운 것들 중 주로 supervised learning을 배웠습니다. 데이터 x와 레이블 y가 있고 x를 y에 mapping 하는 함수를 학습하는 것이 목표였습니다.

지난 강의에서는 Unsupervised Learning을 배웠습니다. 데이터는 있지만 레이블이 없는 경우입니다. 데이터에 내재된 숨겨진 구조를 학습하는 것이 목표였습니다.

이번에는 좀 다른 형태의 Reinforcement Learning(강화 학습)에 대해 배웁니다. 강화학습에는 에이전트(agent)가 있습니다. 에이전트는 환경(environment)에서 행동(action)을 취하는 주체입니다. agent는 행동에 따른 적절한 보상(rewards)을 받습니다. 강화 학습은 agent의 보상을 최대화할 수 있는 행동이 무엇인지를 학습하는 것이 목표입니다.

이번 강의에서는 위와 같이 배웁니다.
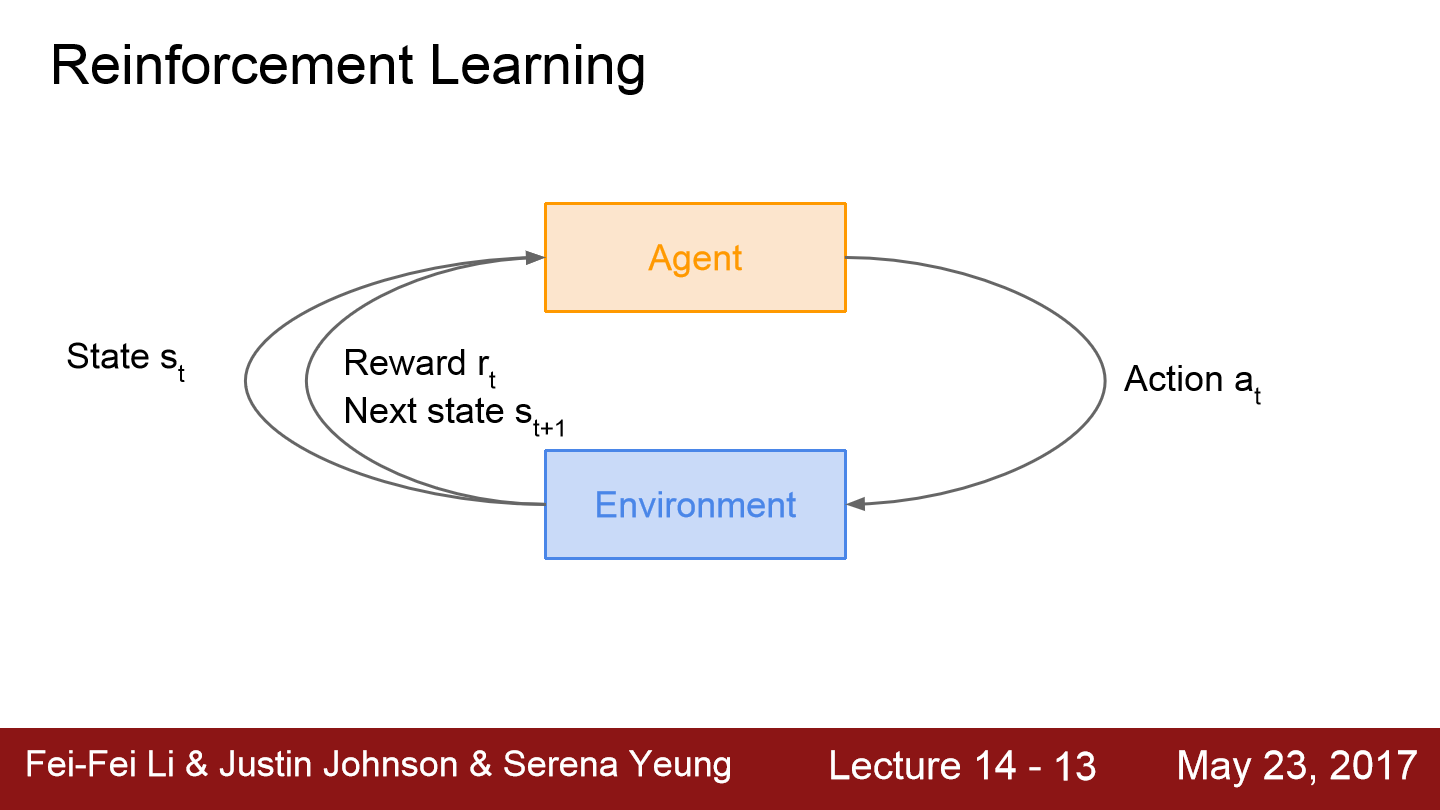
강화학습은 agent와 환경이 있습니다. 그리고 환경에서 에이전트에게는 상태(state)가 주어집니다. 에이전트는 어떤 행동을 취하게 되고 환경은 행동에 따라 에이전트에게 보상을 주고 다음 상태를 부여합니다. 이 과정은 에이전트가 종료 상태(terminal state)가 될 때까지 반복합니다. 종료가 된다면 한 에피소드가 끝나게 됩니다.

강화 학습이 이룬 가장 큰 성과라 볼 수 있는 예시가 위에 있습니다. 바둑에서는 게임을 이기는 것이 목표가 되고 바둑을 둘 수 있는 모든 자리가 state이 됩니다. action은 다음 수를 두는 것이며 게임을 이겼을 경우에 보상(1)을 줍니다.

Markov Decision Process를 통해서 강화 학습 문제를 수식화 할 수 있습니다. MDP는 Markov property(현재 상태만으로 전체 상태를 나타내는 성질)를 만족합니다.
MDP는 위와 같은 몇 가지 속성으로 정의됩니다. S는 가능한 상태들의 집합, A는 가능한 행동들의 집합, R은 (state, action) 쌍이 주어졌을 때 받게 되는 보상의 분포가 됩니다. P는 전이 확률(transition probability)을 의미하는데 (state, action) 쌍이 주어졌을 때 전이될 다음 상태에 대한 분포를 나타냅니다. 마지막 discount factor는 보상을 받는 시간에 대해서 우리가 얼마나 중요하게 생각할 것인지 말해줍니다.

우선 초기 time step인 t = 0에서 환경은 초기 상태 분포인 p(s_0)에서 상태 s_0를 sampling합니다. 그리고 t = 0에서부터 완료 상태가 될 때까지 반복합니다. agent가 action(a_t)를 선택하고 환경은 어떤 분포로부터 보상을 sampling 합니다. 그리고 환경은 상태인 s_t+1도 sampling 합니다. 보상은 우리의 상태와 우리가 택한 행동이 주어졌을 때의 보상입니다. 그리고 에이전트는 보상과 다음 상태를 받고 다음 단계를 수행합니다. 이 과정을 에이전트는 종료될 때까지 반복합니다.
이번에는 정책 π에 대해서 알아보겠습니다. 정책은 각 상태에서 agent가 어떤 행동을 취할지를 명시해주는 기능을 합니다. 정책은 deterministic 할 수도, stochastic 할 수도 있습니다. 우리의 목적은 최적의 정책 π^*를 찾는 것입니다. 즉, cumulativce discounted reward를 최대화시키는 것이 목표입니다. 보상에는 미래에 얻을 보상도 포함이 되는데 discount factor에 의해 결정된 값을 얻습니다.
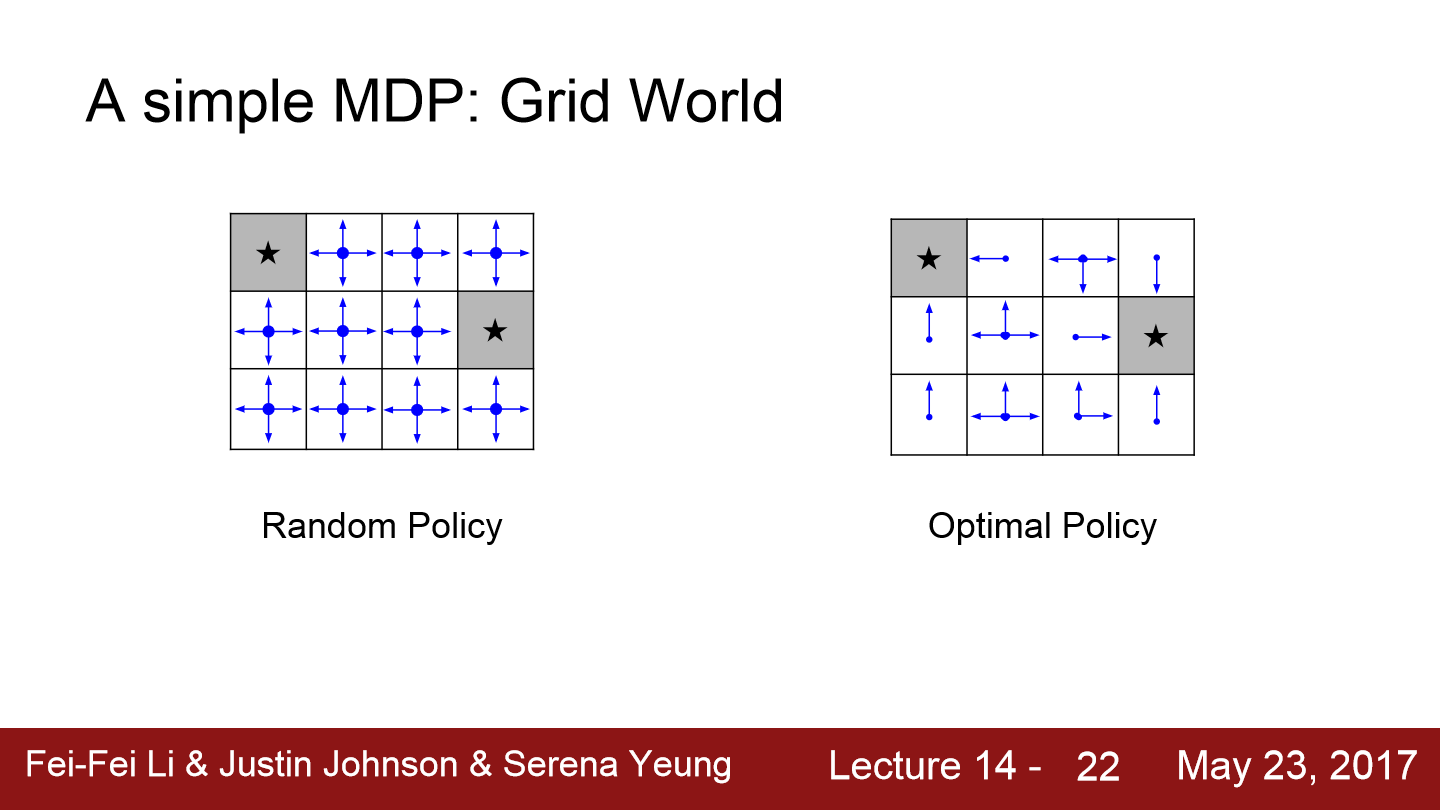
위에는 간단한 예시를 보여주는 그림입니다. random policy를 먼저 보겠습니다. random policy에서는 기본적으로 어떤 방향으로 움직이든 무작위로 방향을 결정합니다. 모든 방향이 동일한 확률을 가진 모습입니다.
하지만 학습을 거쳐서 얻게 될 optimal policy를 보면 우리가 점점 더 종료 상태에 가까워지도록 만드는 적절한 방향을 선택해서 행동을 취하게 됩니다. 예를 들어 종료 상태 바로 주변에 위치하는 경우라면 모든 방향은 종료 상태로 바로 이동하게끔 합니다. 종료상태와 먼 곳에 있다고 하더라도, 종료 상태에 가장 가깝게 이동할 수 있는 방향으로 이동합니다.

최적의 정책 π^*를 찾아야 하는데 최적의 정책은 보상의 합을 최대화시킵니다. 그리고 최적의 정책은 우리가 어떤 state에 있어도 그 때 얻을 수 있는 보상을 최대화시킬 수 있는 행동을 제시합니다.
MDP에서 발생하는 무작위성(randomness)을 다루기 위해서 보상의 합에 대한 기댓값을 최대화 시키는 방식으로 최적의 정책을 구하는 방향으로 진행하면 됩니다.

이번에는 가치 함수(value function)과 Q-가치 함수(Q-value function)를 설명합니다. 우리가 정책을 따라 무언가를 수행하게 되면 결국은 모든 에피소드마다 어떤 "경로"를 얻게 될 것입니다. 초기 상태인 s_0, a_0, r_0부터 시작해서 s_1, r_1, r_1 이런 식으로 쭉쭉 나아갈 것입니다. 그렇게 되면 우리가 얻을 수 있는 s, a, r들의 하나의 경로(trajectory)가 생깁니다.
현재 상태가 얼마나 좋은 상태인지를 알 수 있도록 하는 함수가 가치 함수입니다. 가치 함수는 임의의 상태 s에 대한 가치 함수는 s와 정책이 주어졌을 때 누적 보상의 기댓값이 됩니다.
(state, action) 쌍이 얼마나 좋은지를 알 수 있도록 하는 함수는 Q-가치 함수입니다. Q-가치 함수는 π, a, s가 주어졌을 때 받을 수 있는 누적 보상의 기댓값입니다.

이번에는 Bellman 방정식에 대해 말합니다. 먼저 최적의 Q-가치 함수인 Q^*는 (state, action) 쌍으로부터 얻을 수 있는 누적 보상의 기댓값을 최대화시킵니다. 이러한 Q^*는 bellman 방정식을 만족합니다.
intuition을 보면 s^prime에서의 Q^*는 우리가 현재 상태에서 취할 수 있는 모든 행동들 중에 Q^*(s^prime, a^prime)을 최대화 시키는 값이 된다고 합니다. Q^*는 어떤 행동을 취했을 때 미래에 받을 보상의 최대치를 의미하는 것이며 이 값을 따라가기만 하면 최상의 보상을 받을 수 있습니다.

그럼 최적의 정책을 구하는 방법은? value iteration algorithm을 통해 구할 수도 있습니다. 반복적인 update를 위해서 bellman 방정식을 사용해 각 step마다 Q^*를 조금씩 최적화시키게 됩니다.
하지만 이 방법은 scalable하지 않습니다. 반복적으로 update하기 위해서는 모든 (state, action)마다 Q(s)를 계산해야 합니다. 만약 Atari game의 경우 스크린에 보이는 모든 픽셀이 state가 되는데 이러면 state 공간 자체가 너무 크고 전체 state 공간을 계산하는 것은 불가능합니다.
이를 해결하기 위해서 Q(s, a)를 neural network를 사용해 근사 시키는 방법이 있습니다.

이제는 Q-learning 수식을 보겠습니다. 여기에서는 행동 가치 함수(action value function)를 추정하기 위한 함수 근사를 이용합니다. 함수 근사는 deep neural network를 사용할 것인데 이를 deep Q-learning이라 합니다.
여기에는 parameter θ가 있는데 이는 neural network의 가중치입니다.

최적의 방법을 찾으면서도 Q-function은 bellman 방정식을 만족하기 위해 위와 같은 형태를 보입니다.
neural network로 근사시킨 Q-function을 학습시켜 bellman 방정식의 error가 최소가 되도록 하면 됩니다. loss function은 q(s, a)가 목적 함수와 얼마나 멀리 떨어져 있는 지를 측정합니다. 위에 보이는 목적함수 y_i가 bellman 방정식이 됩니다.
forward pass에서는 loss function을 계산하고 backward pass에서는 계산한 손실을 기반으로 θ를 update 합니다. 반복적인 update를 통해 우리가 가진 Q-function이 타깃과 가까워지도록 학습합니다.

Deep Q-learning이 적용된 예시의 모습입니다. 게임의 목적은 최대한 높은 점수를 획득하는 것이고 state는 게임의 픽셀이 그대로 사용됩니다. 행동은 상하좌우와 같이 게임에 필요한 어떤 행동이 될 것이고 게임이 진행됨에 따라 매 time step마다 점수가 늘어나거나 줄어듦에 따라 보상을 얻습니다. 이 경우 score를 기반으로 전체 누적 보상을 계산할 수 있습니다.

Q-function에서 사용하는 network는 위와 같이 생겼습니다. Q-network는 가중치인 θ를 가지고 있습니다. network의 input은 상태 s가 됩니다. 즉 현재 게임 스크린의 픽셀들이 들어옵니다. 실제로는 4 프레임 정도 누적시켜서 사용합니다. input은 RGB -> grayscale 변환, downsampling, cropping 등 전처리 과정을 거쳐 들어옵니다.
network 구조는 conv, FC로 구성되어 있습니다. 8x8 / 4x4 conv를 거치고 FC-256을 거칩니다. FC layer의 출력 vector는 network의 input인 state가 주어졌을 때 각 행동의 Q-value입니다. 네 가지의 행동이 존재한다면 출력도 4차원입니다. 위 예시의 경우 현재 상태 s_t와 여기에 존재하는 행동들 a_1, a_2, a_3, a_4에 관한 Q 값들이 됩니다. 각 행동들마다 하나의 스칼라 값을 얻습니다. 이러한 구조는 한 번의 forward pass로 현재 상태에 해당하는 모든 함수에 대한 Q-value를 계산할 수 있습니다. 이는 매우 효율적입니다.

한 가지 더 알아야 할 개념이 있는데 "experience replay"라는 개념입니다. experience replay는 Q-network에서 발생할 수 있는 문제들을 다룹니다. Q-network를 학습시킬 때 하나의 배치에서 시간적으로 연속적인 샘플들로 학습하면 안좋습니다. 예를 들어 게임을 진행하면서 시간적으로 연속적인 샘플들을 이용해 state, act, reward를 계산하고 train 하면 모든 sample들이 correlated 한 관계를 갖게 되는데 이는 학습에 매우 비효율적입니다. 이를 해결하기 위해 experience replay를 사용합니다.
이 방법은 replay memory를 이용하는데 replay memory에는 (state, act, reward, next_state)로 구성된 전이 table이 있습니다. 게임 에피소드를 플레이하면서 더 많은 경험을 얻음에 따라 전이 테이블을 지속적으로 update 시킵니다. 여기에서는 replay memory에서의 임의의 mini batch를 이용해 Q-network를 학습시킵니다. 연속적인 샘플을 사용하는 대신 전이 테이블에서 임의로 샘플링된 샘플을 사용하는 방식입니다. 이 방식을 통해 상관관계 문제를 해결할 수 있으며 각각의 전이가 가중치 업데이트에 여러 차례 기여할 수 있다는 장점이 있습니다. 그리고 전이 테이블로부터 샘플링을 하면 하나의 샘플도 여러 번 뽑힐 수 있고 이를 통해 데이터 효율이 훨씬 더 증가합니다.

이제 experience replay를 이용한 Q-learning 전체 알고리즘을 보겠습니다. 우선 replay memory를 초기화합니다. 그리고 Q-network를 임의의 가중치로 초기화시킵니다. 그리고 앞으로 M번의 에피소드를 진행합니다. 따라서 학습은 총 M번 에피소드까지 진행됩니다.
그리고 각 에피소드마다 상태를 초기화시킵니다. state는 게임 시작화면 픽셀이 됩니다. 게임이 진행중인 매 다음 스텝마다 적은 확률로는 임의의 행동을 취합니다(정책을 따르지 않고). 이는 충분한 탐사(exploration)를 위해서는 아주 중요한 부분입니다. 이를 통해 다양한 state 공간을 sampling 할 수 있습니다.
낮은 확률로 임의의 행동을 취하거나 또는 현재 정책에 따라 greedy action을 취합니다. 다시 말해 대부분의 경우에는 현재 상태에 적합하다고 판단되는 greedy action을 선택하게 될 것이고, 가끔 낮은 확률로 임의의 행동이 선택됩니다.
이렇게 행동 a_t를 취하면 보상 r_t와 다음 상태 s_t+1를 얻습니다. 그리고 전이(transition)를 replay memory에 저장합니다.
이제 network를 학습시킵니다. 이 때 experience replay를 사용합니다. replay memory에서 임의의 mini-batch 전이들(transition)을 샘플링한 다음에 이를 이용해 update 합니다. 게임을 진행하는 동안에 experience replay를 이용하여 mini batch를 샘플링하고, 이를 통해 Q-network를 학습시킵니다.

사실 Q-function은 너무 복잡하다는 문제가 있습니다. Q-learning에서는 모든 (state, action) 쌍들을 학습해야만 하는데 모든 state, action 쌍을 학습시키는 것은 아주 어려운 문제입니다. 반면 "정책"은 매우 훨씬 간단하기 때문에 정책 자체를 학습해 여러 정책들 중 최고의 정책을 찾아내는 것이 가능합니다. 정책을 결정하기에 앞서 Q-value를 추정하는 과정을 거치지 않고 최고의 정책을 찾아낼 수 있습니다.

이러한 접근 방식이 "policy gradients"입니다. 수식적으로 매개변수화된 정책 집합(class of parametrized policies)을 정의하면 위와 같이 표현됩니다.
여기서 J(θ)는 미래에 받을 보상들의 누적 합의 기댓값을 나타냅니다. 최적의 정책인 θ^*를 찾는 것인데 이는 argmax_θ J(θ)로 나타낼 수 있습니다. 이제는 보상의 기댓값을 최대로 하는 정책 parameter를 찾으면 됩니다.
policy parameter에 대해서 gradient ascent를 수행해 계속 update해주면 최적의 정책을 찾을 수 있을 것입니다.

이제 gradient ascent를 위해 J(θ)를 미분하겠습니다. 미분한 후 이 값들을 gradient step을 취하면 됩니다. 미분은 잘 진행되긴 하지만 이 값을 계산할 수가 없습니다(intractable). p가 θ에 종속되어 있는 상황에서 기댓값 안에 gradient가 있어 문제가 될 수 있습니다.
그래서 이를 해결하기 위해 트릭을 적용합니다. p를 가지고 하는 트릭인데 어차피 1을 곱하면 상관없으므로 위아래에 p(τ;θ)를 곱해줍니다.
이제 수식을 앞에 있던 gradient에 대입하면 됩니다. 이제는 log(p)에 대한 gradient를 모든 경로에 대한 확률과 곱하는 꼴이 되고, 이를 τ에 대해서 적분하는 꼴이 되기 때문에 이는 다시 경로 τ에 대한 기댓값의 형식으로 바꿀 수 있습니다. 처음에는 기댓값에 대한 gradient를 계산했지만 이제는 gradient에 대한 기댓값으로 바꾼 셈입니다. 이로 인해, gradient를 추정하기 위해서 경로를 sampling 하여 사용할 수 있게 되었습니다.

p(τ)는 어떤 경로에 대한 확률입니다. 이는 현재 (state, action)이 주어졌을 때, 다음에 얻게 될 "모든 상태에 대해서 전이확률"과 "정책 π로부터 얻은 행동에 대한 확률"의 곱 형태로 이루어집니다. 따라서 이를 모두 곱하면 경로에 대한 확률을 얻어낼 수 있습니다.
위 식에서 첫 항인 전이확률은 θ와 무관한 항입니다. θ와 관련이 있는 항은 오직 두 번째 항인 log pi_θ(a_t | s_t)항 뿐입니다. 이를 통해 전이 확률은 전혀 상관하지 않아도 된다는 것을 알 수 있습니다. 즉 gradient를 계산할 때 전이 확률은 필요하지 않습니다. 따라서 우리는 어떤 경로 τ에 대해서 gradient를 기반으로 J(θ)를 추정해 낼 수 있습니다. 지금까지는 하나의 경로만 고려했지만 기댓값을 계산하기 위해서는 여러 개의 경로를 샘플링할 수도 있게 됩니다.
어떤 경로로부터 얻은 reward가 크다면, 즉 어떤 일련의 행동들이 잘 수행한 것이라면 그 일련의 행동들을 할 확률을 높혀줍니다. 즉 그 행동들이 좋았다는 것을 말해주는 것입니다. 반면 어떤 경로에 대한 보상이 낮다면 해당 확률을 낮춥니다. 그러한 행동들은 좋지 못한 행동이라는 것이며 따라서 그 경로로 sampling 되지 못하도록 해야 합니다.

이번에는 hard attention과 관련이 있는 RAM에 대한 내용입니다. image classification과 관련이 있는데 여기에서도 이미지의 클래스를 분류하는 문제지만 이미지의 일련의 glimpse를 가지고만 예측을 합니다. 이미지 전체가 아닌 지역적인 부분만을 보는 것이며 어떤 부분을 볼 지를 선택적으로 집중할 수 있고 이렇게 정보를 얻어나갑니다.
처음에는 low resolution 먼저 보고 그 다음 더 복잡한 것을 봅니다. 이러한 방식은 계산 자원(computational resources)을 절약할 수 있습니다. 저해상도를 살펴보면서 어디서부터 시작할지를 저하고 고해상도 세부적인 것들을 찾아내는 방식이기 때문에 자원이 절약됩니다. 이로 인해 크기가 큰 이미지들을 더 효과적으로 처리할 수 있는 scalability를 갖게 됩니다.
이제 REINCFORCE 식으로 표현하겠습니다.우선 state는 지금까지 관찰한 glimpse가 됩니다. action은 다음에 이미지의 어떤 부분을 볼 지를 선택하는 것이 됩니다. 실제로는 다음 스텝에서 보고 싶은 고정된 사이즈 glimpse의 중간 x, y좌표가 될 수 있습니다.
강화 학습에서 분류 문제를 풀 때 보상은 최종 step에서 이미지를 올바르게 분류하면 1, 그렇지 않으면 0이 됩니다. 누적된 glimpse가 모델에 주어지고 여기에서는 상태를 모델링하기 위해서 RNN을 사용합니다. 그리고 policy parameters를 이용해 다음 액션을 선택하게 됩니다.
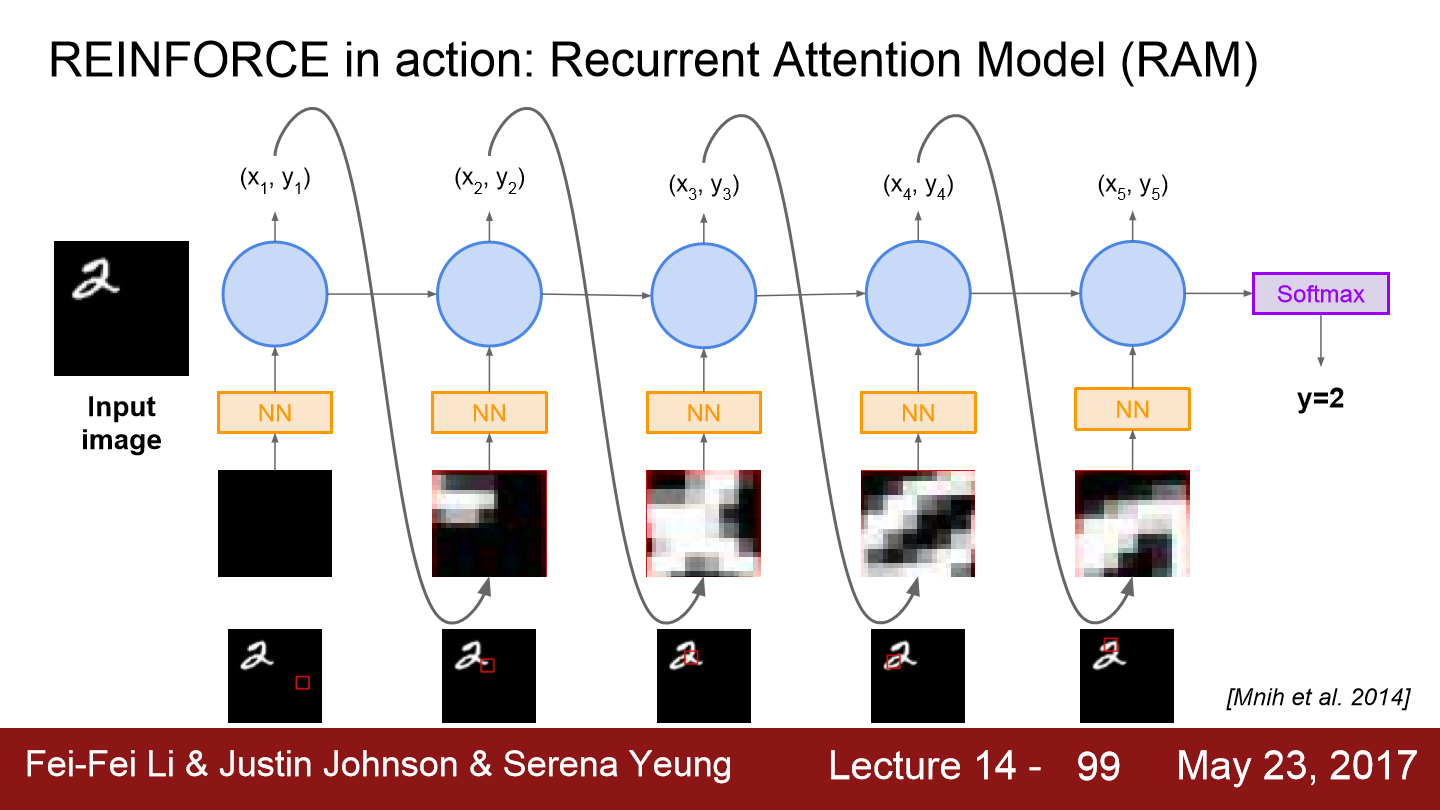
이번에는 예시를 들어보겠습니다. 우선 input image가 들어가고 glimpse를 추출합니다. 위 예시에선 빨간색 박스가 glimpse인데 비어있는 모습입니다. 그리고 추출된 glimpse는 neural network를 통과합니다.
glimpse를 neural network에 통과시키고 나면 RNN을 이용해 지금까지 있던 glimpse(state)를 전부 결합해 행동에 대한 분포의 형태로 만듭니다.
output으로 나온 행동 분포로부터 특정 x, y 위치를 샘플링한 다음에 이 x, y좌표를 이용해 다음 glimpse를 얻습니다. 새로운 glimpse를 보면 숫자 2의 꼬리 부분으로 이동했습니다. 잘 진행 중인 모습입니다. 현재 input과 이전 상태(previous hidden state)를 입력으로 받는 RNN을 이용해서 policy를 모델링합니다.
이러한 작업을 반복합니다. 그리고 마지막 time step에 도달하게 되는데 time step의 수는 고정된 값을 주로 사용하고 실제로는 6 ~ 8번 정도 사용합니다. 마지막 step에서는 결국 우리는 분류를 하고 싶었기 때문에 softmax를 통해 각 클래스 확률분포를 출력하도록 합니다. 이 모델의 경우 가장 높은 확률의 클래스가 2였고 결국 모델이 숫자를 2로 잘 예측한 모습입니다.

우리가 흔히 아는 AlphaGo도 policy gradient를 사용했습니다. AlphaGo는 지도학습과 강화 학습이 섞여있습니다. 또한 Monte Carlo Tree search와 같은 오래된 방식과 아주 최신의 deep RL방법도 섞여있습니다. input vector로 바둑판과 바둑돌의 위치와 같은 요소들을 특징화시켜 넣어줍니다. 네트워크는 프로 바둑기사의 기보를 지도 학습으로 학습시켜서 초기화합니다. 바둑판의 현재 상태가 주어지면 다음 행동을 어떻게 취할지를 결정합니다. 프로 바둑기사가 두는 수들을 supervised mapping으로 학습시킵니다.
이번에는 policy network를 초기화하는 방법입니다. policy network는 바둑판의 상태를 input으로 받아서 어떤 수를 둬야 하는지 return합니다. 이 또한 policy gradient를 이용해서 지속적으로 학습합니다. 스스로 대국을 둬 이기면 보상(1)을 받고 지면 -1의 보상을 받습니다.
'Deep Learning(강의 및 책) > CS231' 카테고리의 다른 글
| Lecture 13. Generative Models (0) | 2022.07.01 |
|---|---|
| Lecture 12. Visualizing and Understanding (0) | 2022.05.23 |
| Lecture 11. Detection and Segmentation (0) | 2022.05.21 |
| Lecture 10. Recurrent Neural Networks (0) | 2022.05.19 |
| Lecture 9. CNN Architectures (0) | 2022.05.14 |



