https://arxiv.org/pdf/1908.03826.pdf
해당 논문을 보고 작성하였습니다.


Abstract
이 논문에서는 단일 이미지 motion deblurring을 위한 새로운 GAN, deblurGAN-v2를 제시합니다. 이 deblurGAN-v2는 double scale discriminator가 있는 relativistic conditional GAN을 기반으로 만들었습니다. deblurGAN-v2의 핵심 구성 요소로 Feature Pyramid Network가 있고, 이는 광범위한 backbone에서 유연하게 작동해 성능과 효율성 간의 균형을 조정할 수 있습니다.
1. Introduction

이 논문은 단일 이미지 blind motion deblurring의 설정에 초점을 둡니다. 모션 블러는 손으로 찍은 사진이나 낮은 프레임의 비디오에서 흔히 발견할 수 있습니다. Blur는 인간의 지각 능력을 떨어뜨리고 컴퓨터 비전을 통해 분석하고 해결해야 합니다. 실제로 blur는 일반적으로 알려지지 않은 공간적으로 다양한 blur kernel을 가지고 있으며, noise와 artifact로 인해 더욱 복잡해집니다.
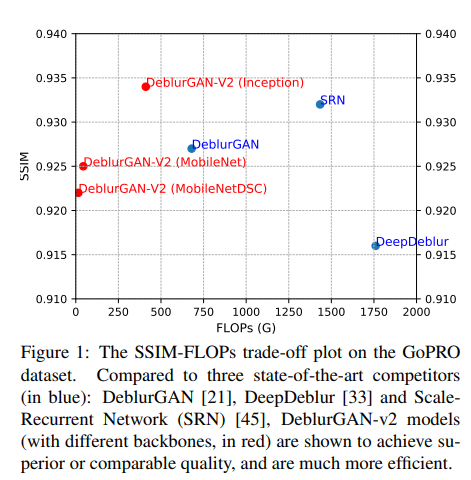
최근 딥러닝은 이미지 복원 분야에서 상당한 성과를 보여주고 있는데, 특히 GAN은 종종 고전적인 feed-forward encoder보다 더 선명하고 자연스러운 질감을 보여주고 이미지 초해상도 및 페인팅에서도 성공적인 성과를 보이고 있습니다. DeblurGAN이라고 불리는 모델은 합성 및 실제 흐릿한 이미지 모두에서 지각적으로 만족스럽고 정확한 이미지를 복원하는 것으로 입증되었으며 다른 모델들보다 5배 빠른 속도를 보여줍니다. 이 논문에서 제시하는 DeblurGAN-v2는 DeblurGAN보다 deblurring 성능이 좋고 효율성 측면에서 개선해 품질 스펙트럼에 대해 높은 유연성을 갖습니다.

- Framework Level:
새로운 conditional GAN framework를 구축합니다. 객체 인식을 위해 개발된 Feature Pyramid Network를 generator에 도입함으로써 이미지 복원 작업에 사용합니다. discriminator의 경우, 최소 제곱 오차를 사용하는 global(image)와 local(patch)를 각각 평가하는 두 개의 열을 가진 상대적인 discriminator를 적용했습니다.
- Backbone Level:
위 framework는 generator backbone에 영향을 받지 않지만, 선택은 deblurring 품질과 효율성에 영향을 미칩니다. 그래서 최첨단 deblurring 품질을 만들기 위해 정교한 Inception-ResNet-v2 backbone을 연결합니다. 보다 효율적인 방향(크기가 작고 결과가 빠르게 나오는)으로는 MoblieNet을 채택하고 깊이별 분리형 convolutions(MobileNet DSC)을 바탕으로 변형된 것을 만듭니다.
- Experiment Level:
DeblurGAN-v2의 성능을 보여주기 위해 세 가지 benckmark에 대한 결과를 보여줍니다. MobileNet-DSC를 탑재한 deblurGAN-v2는 DeblurGAN보다 11배 빠르고 다른 모델에 비해선 100배 빠릅니다. 또한 크기도 4MB에 불과해 실시간 비디오 deblurring에도 가능성을 시사합니다. 실제 blurry 한 이미지에 대한 deblurring 품질에 대해 주관적인 연구도 보여주고, 추가적인 유연성으로서 일반적인 이미지 복구에서의 deblurGAN-v2의 잠재력을 제시합니다.
2. Related work

- Generative adversarial networks
일반적인 GAN은 discriminator D와 generator G로 구성되어 있고 이 둘이 minimax game을 하면서 학습이 이루집니다. 그중 conditional GAN은 이미지 복원 및 향상과 함께 image to image 변환 문제에 적용되어 왔습니다. 하지만 최적화하기 어렵고 훈련 도중 mode collapse와 gradient vanishing/explosion 문제가 있습니다. 이러한 문제를 해결하기 위해 최소 제곱을 loss function으로 GAN의 D에 적용했습니다. 이를 통해 더 부드럽고 기울기 포화되는 문제를 해결할 수 있었습니다. 저자들은 로그 유형의 loss function이 x와 결정 경계 사이의 거리를 무시하기 때문에 빠르게 포화된다고 합니다. 대조적으로 L2 loss는 거리에 비례하는 기울기를 제공하며, 더 멀리 떨어진 fake image에 대해선 더 큰 페널티를 부과합니다.
GAN의 또 다른 개선된 모델은 Relativistic GAN 입니다. 이는 상대론적 D를 사용해 주어진 real data가 random 하게 추출된 fake image보다 더 현실적일 확률을 추정합니다. 이 Relativistic GAN은 DeblurGAN v1에서 사용한 WGAN-GP를 포함한 다른 GAN 유형에 비해 더 안정적이고 계산적으로 효율적입니다.
3. DeblurGAN-v2 Architecture

DeblurGAN-v2는 blur 처리된 image I_B를 받아 학습된 generator를 통해 sharp image I_s를 복원합니다.
3.1 Feature Pyramid Deblurring
현재 존재하는 CNN을 이용한 이미지 deblurring(및 기타 복원 문제)은 일반적으로 ResNet과 유사한 구조를 보입니다. 대부분의 최첨단 방법은 서로 다른 규모의 input image pyramid를 가진 다중 스트림 CNN을 활용하여 서로 다른 수준의 blur를 처리합니다. 하지만 다중 스케일 이미지를 처리하는 것은 시간이 오래 걸리고 메모리도 많이 필요합니다.
이 논문에서는 이미지 복원 및 향상 분야에서 일반적으로 쓰이는 Feature Pyramid Networks(FPN)을 사용합니다. 이는 다중 스케일 기능을 통합하는 경량화된 대안으로 사용됩니다. FPN은 원래 객체 감지를 위해 설계되었습니다. 이는 다양한 의미를 인코딩하고 더 좋은 품질의 정보를 포함하는 다양한 feature map layer를 만듭니다. FPN은 bottom-up과 top-down path를 포함합니다. bottom-up pathway는 공간 해상도가 downsampling 되지만 더 많은 의미 있는 context 정보가 추출되고 압축되어 있는 feature를 얻기 위해 사용되는 일반적인 convolution network입니다. top-down pathway를 통해 FPN은 다양한 layer로부터 고해상도로 재구성합니다. bottom-up과 top-down pathway를 연결하는 것은 고해상도 디테일을 보완하고 객체를 위치시키는 데 도움이 됩니다.
이 논문에서 사용하는 모델의 architecture는 FPN backbone으로 구성되어 있고 여기서 서로 다른 크기의 다섯개의 final feature map을 얻습니다. 나중에 feature는 동일한 input size의 1/4로 up-sampling 되고, 서로 다른 level의 의미 정보를 포함하는 하나의 tensor로 concat 됩니다. network 끝에 up-sampling, convolution layer 2개를 추가해 원래 이미지 크기를 복원하고 인조적인 느낌을 줄입니다. 그리고 이 논문에서는 input에서 output으로 가는 direct skip connection을 추가해 성능을 향상했습니다. 그리고 input image를 -1 ~ 1로 정규화합니다. 또한 출력을 동일한 범위로 유지하기 위해 tanh를 activation layer로 사용했습니다. muli-scale feature aggregation capability 뿐만 아니라, FPN은 정확성과 속도 사이에서 균형을 이룹니다.
3.2 Choice of Backbones: Trade-off between Performance and Efficiency
새로운 FPN embeded architecture는 feature extractor backbone과는 무관합니다. 이러한 plug-and-play 속성을 통해, 정확성과 효율성의 스펙트럼을 탐색할 수 있는 유연성을 얻을 수 있습니다. 기본적으로 이 논문에서는 pretrain된 Image-Net backbone을 사용해 더 많은 semantic-related features을 전달합니다. 이 논문에서 하나의 옵션으로, deblurring 성능을 추구하기 위해 Inception-ResNet-v2를 사용하지만, SEResNeNext와 같은 다른 backbone이 약간 더 효과적이라고 합니다.
최근 moblie-on-device image 향상의 필요성으로 인해 효율적인 복뭔 모델에 대한 요구가 증가되었고 이를 바탕으로 이 논문은 MoblieNet-v2 backbone을 또 다른 option으로 사용합니다. 복잡성을 더 줄이기 위해, 전체 network의 모든 convolution을 Depthwise Separable Convolution으로 변경했습니다. 결과 모델은 MobileNet-DSC로 표시되며 매우 가볍고 효율적인 이미지 Deblurring을 제공합니다.
3.3 Double-Scale RaGAN-LS Discriminator

DeblurGAN의 WGAN-GP discriminator 대신 몇몇 가지를 업그레이드한 DeblurGAN-v2를 제시합니다. 먼저 LSGAN cost function에 relativistic "wrapping"을 사용해 새로운 RaGAN-LS loss를 생성합니다.
WGAN-GP보다 현저히 학습이 빠르고 안정적입니다. 또한 생성한 이미지의 결과가 더 높은 품질을 보이고 sharper 한 이미지를 만들어냅니다. 그래서 DeblurGAN-v2의 generator의 adversarial loss를 위와 같은 식으로 정의됩니다. patchGAN은 전체 이미지에서 작동하는 표준 글로벌 discriminator보다 더 선명한 결과를 생성하는 70 x 70 크기의 이미지 패치에서 작동합니다. DeblurGAN은 이러한 patchGAN의 idea를 사용했습니다. 이 논문에서 제안하는 deblurGAN-v2는 전역 및 로컬 기능을 모두 활용하기 위해 patch level에서 작동하는 local discriminator와 전체 input image를 공급하는 global brach로 구성된 double-scale discriminator를 사용합니다. 이를 통해 더 크고 이질적인 실제 blur를 잘 처리할 수 있습니다.
GAN을 훈련하려면 훈련 단계 이미지를 재구성된 이미지와 원래 이미지를 몇 가지 metric으로 비교합니다. 흔한 하나의 option이 pixel space loss(L_p)를 L1 or L2로 간단하게 구현할 수 있습니다. L_p를 사용하면 지나치게 평활화된 픽셀 공간 출력을 산출하는 경향이 있다고 합니다. 그래서 이를 해결하기 위해 제안된 것이 content loss(L_x)로 perceptual distance를 사용하는 것입니다. L_2와 대조적으로 VGG19 conv 3x3 feature map에서 euclidean loss를 계산합니다. DeblurGAN-v2는 훈련을 위해 하이브리드 세 가지 loss를 사용합니다.
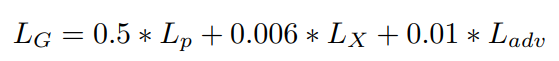
위와 같은 형식으로 loss를 정의합니다. L_p는 pixel space loss, L_x는 content loss, L_adv는 adversarial loss를 의미하고, L_adv에는 전역 및 국소 discriminator loss를 모두 포함합니다. 또한 MSE(Mean Square Error)를 L_p로 사용합니다. DeblurGAN은 L_p 항을 포함하지 않았지만 색상과 질감 왜곡을 수정하는 데 도움이 되어 DeblurGAN-v2에는 추가했습니다.

그다음에서 논문에는 실험 결과들에 대해 보여줍니다. 다양한 dataset을 이용해 많은 결과를 보여주고 있고, 다른 GAN model보다 더 빠르고 좋은 이미지 결과를 만들어내는 모습을 보입니다.
'연구실 공부' 카테고리의 다른 글
| [논문] Contrastive Learning for Unpaired Image-to-Image Translation (0) | 2023.01.03 |
|---|---|
| [논문]CycleGAN(Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks) (0) | 2022.12.25 |
| 성능 평가 지표(정확도(accuracy), 재현율(recall), 정밀도(precision), F1-score) (0) | 2022.09.07 |
| [Keras] Dogs vs Cats classification (0) | 2022.08.23 |
| GAN 정리(DCGAN, WGAN, CGAN, LSGAN) (0) | 2022.08.15 |


