https://arxiv.org/pdf/1703.10593.pdf
해당 논문을 보고 작성했습니다.


Abstract
Image to image translation은 pair 되어 있는 train data를 이용해 input image와 output image를 mapping 하기 위해 학습합니다. 하지만, 대부분의 경우 pair 되어 있는 train data를 구하는 것은 거의 불가능합니다. 그래서 이 연구에서는 쌍이 없는 훈련 데이터 없이 source domain X에서 target domain Y로 이미지 변환하는 방법을 학습하기 위한 내용을 설명합니다. 이 논문에서 제시하는 방법을 통해 style transfer, object transfiguration, season transfer, photo enhancemet 등과 같이 pair 된 train data를 사용해야 하는 방식에도 좋은 결과를 보여줍니다.
1. Introduction

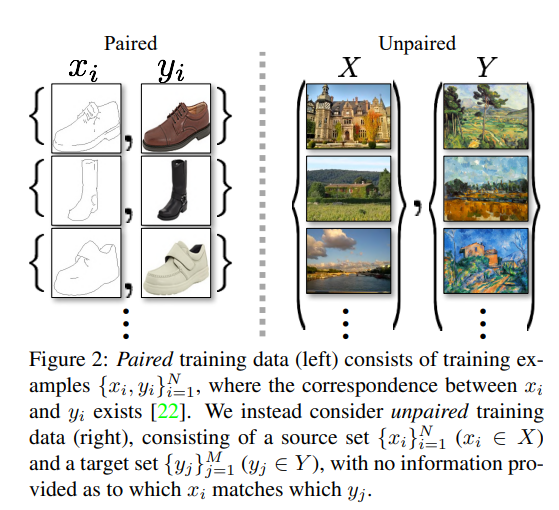
computer vision, image processing, computational photography and graphics 분야에서 수 년동안 지도학습을 통해 성능이 좋은 translation system을 만들었습니다(Figure 2에서 나오는 것처럼 image가 pair 되는 경우). 그러나 pair 된 train datda를 얻는 것은 어렵고 비용도 많이 듭니다. 많은 분야에서, 예를 들어 object transfiguration의 경우 얼룩말을 말로, 말을 얼룩말로 변경하는 system을 만든다고 할 때 pair 된 이미지 자체를 구하는 것은 매우 어려울 것입니다.
그래서 이 논문에서는 input, output이 pair되지 않고도 학습이 가능한 algorithm을 찾고 제시합니다. G: X -> Y로 mapping 하는 train을 하는데 이 output을 yˆ = G(x), x ∈ X라 하겠습니다. 적대적 학습을 통해 yˆ, y ∈ Y를 구분할 수 없을 정도로 유사한 이미지를 생성하도록 학습시킵니다. 이론적으로는 Y domain의 분포와 일치하도록 유도되지만 실제로는 최적화를 보장할 수 없고 mode collapse(모든 input image가 동일한 output image를 만들어내고 최적화가 진행되지 않는) 문제도 생깁니다.
그래서 이 논문에서는 "cycle consistent"를 이용합니다. 예를 들어, 영어에서 프랑스어로 문장을 번역한 다음, 다시 프랑스어에서 영어로 번역할 때, 원래 문장으로 돌아가는 것처럼 이러한 특성을 이용합니다. 수학적으로, 만약 G : X -> Y와 F : Y -> X가 존재하면 G와 F는 서로 반대여야 하고 두 mapping은 bijection이어야 합니다. 이 논문에서는 G와 F를 동시에 훈련하고 'cycle consistency loss'를 추가해 F(G(x)) = x, G(F(y)) = y가 되도록 합니다. 이 loss를 adversarial loss와 결합하면 upair인 image에 대해서 image-to-image translation이 가능합니다.
2. Related work
GAN, Image-to-Image Translation, Unpaired Image-to-Image Translation, Cycle Consistency, Neural Style Transfer이 등장합니다. Image-to-Image Translation은 pix2pix를 비롯한 pair 된 image에 대한 translation을 소개합니다. Unpaired Image-to-Image Translation은 이 전에 등장했던 방식들에 대해서 설명해주고 이 논문에서는 cycle consistency loss를 사용한다고 합니다.
3. Formulation

{xi} N i=1 where xi ∈ X and {yj}M j=1 where yj ∈ Y처럼 주어진 training sample에서 두 domain X, Y 사이 mapping 하는 function을 학습하는 것이 이 논문의 목표입니다.

위 Figure3와 같이 이 논문에서 만든 model은 G : X -> Y와 F : Y -> X로 mapping합니다. 추가적으로 adversarial dircriminator D_x와 D_y가 존재하는데, D_x는 x와 F(y)를 구분하는 걸 목표로 하고 D_y는 y와 G(x)를 구분하는 걸 목표로 합니다. 생성한 이미지의 분포를 목적 domain의 data 분포와 일치시키기 위해 adversarial loss와 학습된 G와 F가 서로 contradict 되는 것을 막기 위해 cycle consistency loss를 사용합니다.
3.1 Adversarial Loss
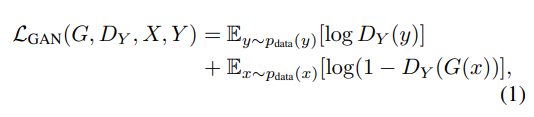
이 논문은 두 mapping 모두를 adversiral loss에 적용합니다. 위 식은 G : X -> Y, discriminator D_y에 대한 식입니다. G는 G(x)라는 image를 생성하는데, 이를 domain Y와 비슷하도록 생성하는 걸 목표로 하는 반면, D_y는 G(x)와 real image y를 구분하는 것을 목표로 합니다. G는 위 식의 값을 최대한 작게, D는 최대한 크게 만들도록 학습됩니다(MinGMaxD). 이와 같이 F : Y -> X도 사용합니다.
3.2 Cycle Consistency Loss
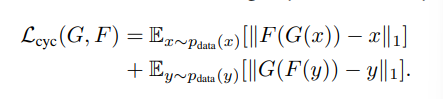
이론적으로 adversarial train은 각각 목표 domain Y와 X로 동일하게 분포된 출력을 생성하는 mapping G, F를 학습할 수 있습니다. 하지만 adversarial loss만으로 train된 function이 input x_i을 output y_i로 mapping 할 수 있다고 보장할 순 없습니다. 이 논문의 저자는 가능한 mapping function의 공간을 더 줄이기 위해, train 된 mapping function이 cycle-consistent 해야 한다고 말합니다. Figure 3에 (b)처럼 domain X에 속한 각각의 image x들은 translation cycle을 통해 다시 original image x로 돌아올 수 있어야 한다고 합니다. x → G(x) → F(G(x)) ≈ x 처럼 말입니다. 이러한 부분을 'forward cycle constistency'라 부릅니다. 비슷하게 Figure 3에 (c)에서는 domain Y에 속한 각각의 image y들은 다시 y로 돌아올 수 있도록 G, F는 'backward cycle consistency'도 만족해야 합니다. y → F(y) → G(F(y)) ≈ y 처럼 표현할 수 있습니다.
이 부분을 만족하기 위해 위 식 'cycle consistency loss'를 구현합니다. 저자들은 F(G(x))와 x 사이, G(F(y))와 y 사이의 adversarial loss를 L1 norm을 사용해봤지만 성능 향상을 보지 못했다고 합니다. cycle consistency loss를 사용해 그려진 그림은 아래에 Figure 4를 통해 확인할 수 있습니다. Reconstruction F(G(x))가 input x에 근접하게 그려지는 것을 볼 수 있습니다.

3.3 Full Objective
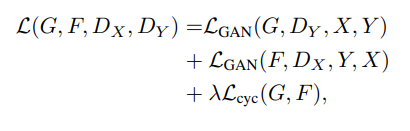
최종 식은 위와 같이 표현할 수 있습니다. λ는 두 목표의 상대적 중요성을 제어할 수 있습니다.

위 논문의 model은 autoencoder 2개를 학습하는 것처럼 보일 수 있습니다(F(G(X) -> X, G(F(Y)) -> Y). 하지만, autoencoder들은 각각 특별한 내부 구조를 가지고 있습니다. 이미지를 다른 domain으로 변환하는 중간 표현을 통해 image를 자신에게 mapping 합니다. 원래 autoencoder는 X -> Y로 가는 방식이지만 이 model은 X -> X로 갑니다. 그리고 이 model에서 사용한 loss가 효과가 있다고 합니다.
4. Implementation

- Network Architecture
이 논문에서 network architecture는 neural style transfer와 superresolution에서 효과를 보여준 Johnson 등의 생성 모델을 사용합니다. 이 network는 3개의 convolution, 몇 개의 residual blocks을 포함하고 2 개의 부분적인 stride를 하는 convolution을 포함하고 feature를 RGB에 mapping 하기 위한 convolution을 포함합니다. 128 x 128 image에는 6개의 blocks, 256 x 256 이상의 고해상도 image에 대해서는 9개의 block을 사용합니다. 또한 instance normalization을 사용합니다. Discriminator network에는 70 x 70 PatchGAN을 사용하는데, 이는 70 x 70 overlapping image patch가 real인지 fake인지 분류하는 것을 목표로 합니다. 이 Patch-level discriminator architecture는 전체 image discriminator보다 조금 더 적은 parameter를 사용하고 fully convolution 방식으로 임의의 크기의 image에서 작동할 수 있습니다.
- Training details
model train을 안정화하기 위해 두 가지 기술을 적용했습니다. 먼저 L_gan에 negative log likelihood를 least-squares loss로 대체했습니다. 이 loss를 통해 train을 안정적으로 할 수 있고 더 높은 퀄리티의 이미지를 생성할 수 있습니다.
LGAN(G, D, X, Y )에서 G를 Ex∼pdata(x) [(D(G(x)) − 1)^2 ]를 최소화 하도록 학습시키고 D를 Ey∼pdata(y) [(D(y) − 1)^2 ] + Ex∼pdata(x) [D(G(x))^2 ]를 최소화하도록 학습시킵니다.
두 번째로, 모델의 oscillation을 줄이기 위해 Shrivastava외 연구진의 전략을 따르고 discriminator를 업데이트할 때, 최신 생성 이미지가 아닌 생성된 이미지의 이력(50장)을 사용합니다.
마지막으로 모든 실험에서는 λ = 10으로 설정하고 batch_size = 1인 Adam을 사용합니다. 그리고 learning_rate는 0.0002로 설정해 학습했습니다. 처음 100 epochs에는 동일한 learning_rate를 유지하다가 다음 100 epochs은 0으로 선형적으로 감소시킵니다.
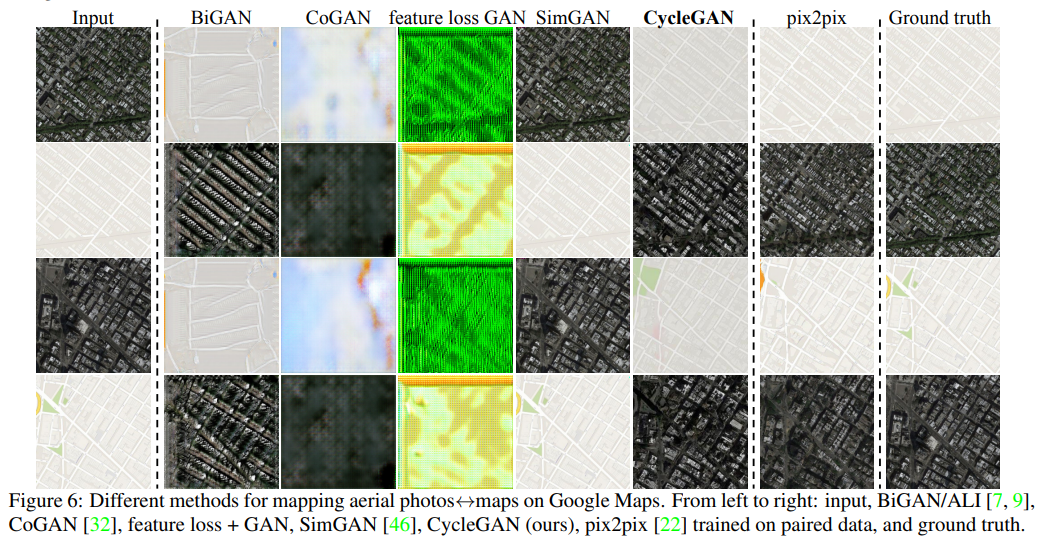
5. Results
더 자세한 결과와 코드는 website에 존재한다고 합니다.

'연구실 공부' 카테고리의 다른 글
| AutoEncoder(AE), Variant AutoEncoder(VAE) (0) | 2023.02.06 |
|---|---|
| [논문] Contrastive Learning for Unpaired Image-to-Image Translation (0) | 2023.01.03 |
| [논문] DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better (0) | 2022.09.23 |
| 성능 평가 지표(정확도(accuracy), 재현율(recall), 정밀도(precision), F1-score) (0) | 2022.09.07 |
| [Keras] Dogs vs Cats classification (0) | 2022.08.23 |


