AutoEncoder에 대해서 먼저 알아보겠습니다. 간단히 말하자면 AutoEncoder는 input을 기반으로 feature를 뽑아내고 이를 이용해 원본 input을 다시 만들어줍니다. 아래 그림처럼 hidden layer의 뉴런 수를 input layer의 뉴런 수보다 더 적게 설정해 데이터를 압축(차원을 축소)하거나, noise가 있는 image를 denoise 된 이미지를 만들거나 할 수 있습니다.

AutoEncoder는 input data를 Encoder network에 넣어 압축된 z vector를 얻습니다. z vector를 decoder network에 넣어 input data와 동일한 크기의 output을 생성합니다.
여기서 말하는 인코더(encoder)는 인지 네트워크(recognition network)라고도 하며, input을 내부 표현으로 변환하는 역할을 합니다. 디코더(decoder)는 생성 네트워크(generative network)라고도 하며, 내부 표현을 출력으로 변환하는 역할을 합니다.
encoder에 넣어 z vector를 얻는다고 했는데 여기서 말하는 z vector는 input으로부터 추출된 feature를 의미하고 이를 latent coding z라고도 표현합니다. AutoEncoder의 경우 latent coding z는 feature를 하나의 숫자로 표현하지만 VAE의 경우 가우시안 호가률 분포로 feature를 표현합니다. AutoEncoder의 latent coding 값은 single value z라면, VAE는 latent conding z가 가우시안 분포로 나타내기 위해서 평균과 분산값으로 나타냅니다.
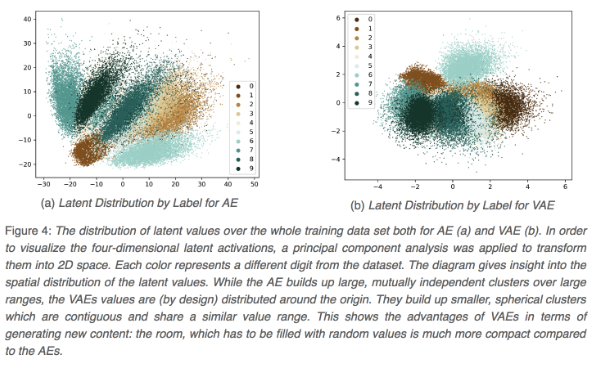
위 그림은 MNIST data에 대해 latent space를 2차원으로 표현한 모습이다. 왼쪽은 AE, 오른쪽은 VAE입니다. 왼쪼긍ㄹ 보면 군집이 넓게 퍼져있고, 중심점을 기반으로 잘 뭉치지 않는 반면에 VAE는 중심점을 기반으로 잘 뭉쳐져 있는 것을 볼 수 있습니다.

위 그림을 보면 AutoEncoder에 대해 설명이 잘 나와있습니다.
AutoEncoder의 경우 Loss값은 input data(위 그림에서 x)와 decoder의 output(위 그림에서 y)의 차이를 의미합니다.
AutoEncoder는 input data의 feature를 추출할 때 많이 사용됩니다.
AutoEncoder의 종류로 Linear AutoEncoder, Denoising AutoEncoder 등 여러가지가 존재합니다.
- Variant AutoEncoder
이번에는 Variant AutoEncoder에 대해 보겠습니다.
VAE는 GAN, diffusion model과 같이 generative model의 한 종류로, input data와 output data를 같게 만드는 것을 통해 의미 있는 latent space를 만드는 AE와 비슷하게 encoder와 decoder를 활용해 latent space를 도출하고, 이 latent space로부터 우리가 원하는 output을 decoding 해 data generation을 진행합니다.
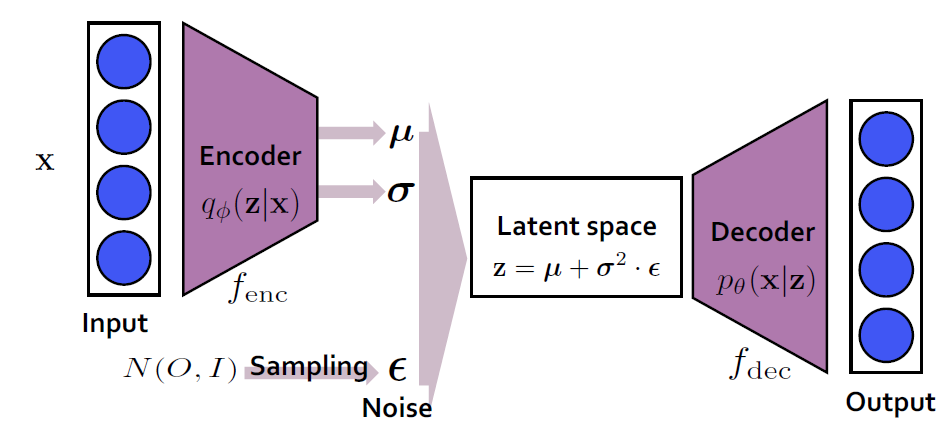
- Encoder
VAE의 encoder는 AE의 encoder와 같이 input을 latent space로 변환하는 역할을 합니다. 하지만 위에서 말한것처럼 VAE는 encoder를 통해 얻은 값은 AE와는 다릅니다. input x가 주어졌을 때 latent vector z의 분포(위 그림에서 q(z|x))를 approximate 하는 것이 VAE encoder의 목적입니다. q(z|x)가 정규분포를 나타내는 평균과 표준편차의 parameter(Φ)를 찾는 것이 목적이 됩니다.
- Decoder
decoder는 latent space를 변환하는 역할을 합니다. latent vector z가 주어졌을 때 x의 분포, 즉 위 그림에서 말하는 p(x|z)를 approximate하는 것을 목적으로 합니다. z vector가 주어지고 이를 통해 data를 generate 하는 역할을 합니다.
- latent space
latent space는 말 그대로 숨겨진 vector들이 존재하는 공간을 의미합니다. latent space가 주어져야 decoder는 image를 generate 할 수 있습니다. 만약 VAE가 AE처럼 input과 output을 똑같이 만드는 것을 목적으로 한다고 할 때 생성된 latent space는 항상 input과 동일한 모양의 데이터를 만들어낼 것입니다. 이를 방지하기 위해 noise를 sampling 하여 이로부터 latent space를 생성합니다. 예를 드어 어떤 표준 정규분포로부터 하나의 noise epsilon을 sampling 하여 얻고, 이에 encoder로부터 얻은 분산을 곱하고 평균을 더해서 latent vector z를 구하는 방법이다. 이를 reparametrization trick이라 합니다.
VAE는 AE와 다르게 input과 동일한 output을 얻는 것이 목적이 아니라 새로운 image를 생성하는 것이 목적입니다.
- ELBO
VAE를 학습하기 위해서 maximum likelihood 접근법을 사용합니다. p_Θ(x)를 maximize하는 Θ를 찾는 것을 목적으로 합니다. VAE는 log likelihood를 maximize 하는 것과 같은데 식으로 표현하면
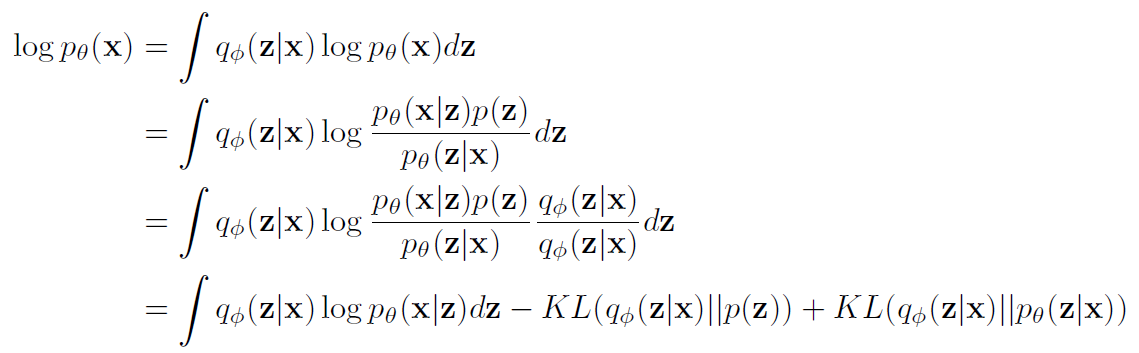
이와 같습니다. bayes rule과 KL divergence의 정의를 활용해 식을 전개했습니다. 마지막 식을 maximize하는 parameter Θ를 찾는 것이 VAE의 목표라고 볼 수 있습니다.
마지막 식을 보면 x를 input을 z를 sampling하고 다시 z를 이용해 decoding을 한 값이 첫 번째 항입니다. 그다음 KL은 q와 p 둘 다 정규 분포를 따르기 때문에 쉽게 계산할 수 있습니다. 하지만 마지막 KL에 있는 p(z|x)는 우리가 구할 수 없습니다. 하지만 KL divergence는 항상 0 이상의 값을 갖기 때문에(KL divergence 정의에 의해)

이와 같이 식을 다시 작성할 수 있습니다. 마지막 부등식의 우항을 evidence lower bound(ELBO)라고 부릅니다. ELBO를 maximize 함으로써 likelihood 또한 maximize 할 수 있습니다.
ELBO식을 볼 때 첫 번째 항을 보면 이는 q(z|w)와 p(x|z) 사이의 negative cross entropy와 같습니다. 그렇기 때문에 이는 encoder와 decoder가 AE처럼 reconstruction을 잘할 수 있게 만들어주는 error라 볼 수 있기 때문에 reconstruction error라 부릅니다. 그다음 항은 q(z|w)와 p(z)의 KL divergence 값입니다. 이는 posterior와 prior가 최대한 비슷하게 만들어주는 error라고 할 수 있고 이는 VAE가 reconstruction task만 잘하는 것을 방지하기 때문에 regularization error(다시 한번 말하자면 p(z)는 정규분포에서 샘플링된 값이고 q(z|x)는 encoder의 output이고 이 두 분포의 차이가 적도록 KL divergence를 계산합니다)라 부릅니다.
마지막으로 VAE의 이미지 생성하는 부분을 보겠습니다.
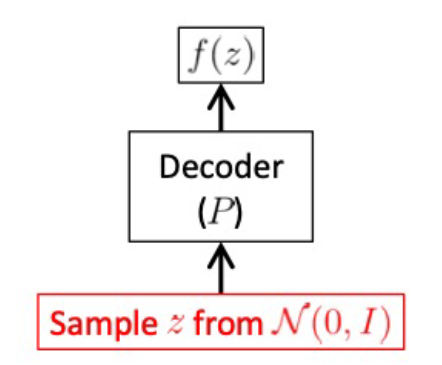
학습을 마친 encoder와 decoder가 존재할 때 표준 정규분포에서 어떤 z를 sampling하고, 이 z를 decoder의 input으로 넣어서 우리가 원하는 data를 generate 할 수 있습니다.
사실 AE와 VAE는 사용 목적부터 다르고 안에 사용되는 loss와 latent space의 활용이 다릅니다. 그래도 encoder, decoder의 구조를 가지고 있다는 공통점이 존재하긴 합니다.
'연구실 공부' 카테고리의 다른 글
| Contrastive Learning for Unpaired Image-to-Image Translation 논문 코드 (0) | 2023.02.13 |
|---|---|
| CycleGAN 논문 코드 (0) | 2023.02.07 |
| [논문] Contrastive Learning for Unpaired Image-to-Image Translation (0) | 2023.01.03 |
| [논문]CycleGAN(Unpaired Image-to-Image Translationusing Cycle-Consistent Adversarial Networks) (0) | 2022.12.25 |
| [논문] DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better (0) | 2022.09.23 |



