Contrastive Learning for Unpaired Image-to-Image Translation 논문을 보고 좀 더 이해하기 위해 저자들이 제공한 코드를 살펴봤습니다.
https://arxiv.org/pdf/2007.15651.pdf

위 논문에서 제시한 모델인 CUT model을 보기 위해 저자들이 제공한 cut_model.py를 보겠습니다.
import numpy as np
import torch
from .base_model import BaseModel
from . import networks
from .patchnce import PatchNCELoss
import util.util as util
class CUTModel(BaseModel):
""" This class implements CUT and FastCUT model, described in the paper
Contrastive Learning for Unpaired Image-to-Image Translation
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu
ECCV, 2020
The code borrows heavily from the PyTorch implementation of CycleGAN
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix
"""
@staticmethod
def modify_commandline_options(parser, is_train=True):
""" Configures options specific for CUT model
"""
parser.add_argument('--CUT_mode', type=str, default="CUT", choices='(CUT, cut, FastCUT, fastcut)')
parser.add_argument('--lambda_GAN', type=float, default=1.0, help='weight for GAN loss:GAN(G(X))')
parser.add_argument('--lambda_NCE', type=float, default=1.0, help='weight for NCE loss: NCE(G(X), X)')
parser.add_argument('--nce_idt', type=util.str2bool, nargs='?', const=True, default=False, help='use NCE loss for identity mapping: NCE(G(Y), Y))')
parser.add_argument('--nce_layers', type=str, default='0,4,8,12,16', help='compute NCE loss on which layers')
parser.add_argument('--nce_includes_all_negatives_from_minibatch',
type=util.str2bool, nargs='?', const=True, default=False,
help='(used for single image translation) If True, include the negatives from the other samples of the minibatch when computing the contrastive loss. Please see models/patchnce.py for more details.')
parser.add_argument('--netF', type=str, default='mlp_sample', choices=['sample', 'reshape', 'mlp_sample'], help='how to downsample the feature map')
parser.add_argument('--netF_nc', type=int, default=256)
parser.add_argument('--nce_T', type=float, default=0.07, help='temperature for NCE loss')
parser.add_argument('--num_patches', type=int, default=256, help='number of patches per layer')
parser.add_argument('--flip_equivariance',
type=util.str2bool, nargs='?', const=True, default=False,
help="Enforce flip-equivariance as additional regularization. It's used by FastCUT, but not CUT")
parser.set_defaults(pool_size=0) # no image pooling
opt, _ = parser.parse_known_args()
# Set default parameters for CUT and FastCUT
if opt.CUT_mode.lower() == "cut":
parser.set_defaults(nce_idt=True, lambda_NCE=1.0)
elif opt.CUT_mode.lower() == "fastcut":
parser.set_defaults(
nce_idt=False, lambda_NCE=10.0, flip_equivariance=True,
n_epochs=150, n_epochs_decay=50
)
else:
raise ValueError(opt.CUT_mode)
return parser
def __init__(self, opt):
BaseModel.__init__(self, opt)
# specify the training losses you want to print out.
# The training/test scripts will call <BaseModel.get_current_losses>
self.loss_names = ['G_GAN', 'D_real', 'D_fake', 'G', 'NCE']
self.visual_names = ['real_A', 'fake_B', 'real_B']
self.nce_layers = [int(i) for i in self.opt.nce_layers.split(',')]
if opt.nce_idt and self.isTrain:
self.loss_names += ['NCE_Y'] # add NCE_Y loss
self.visual_names += ['idt_B'] # add identity_B
if self.isTrain:
self.model_names = ['G', 'F', 'D']
else: # during test time, only load G
self.model_names = ['G']
# define networks (both generator and discriminator)
self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.normG, not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, opt.no_antialias_up, self.gpu_ids, opt)
# define generator network
self.netF = networks.define_F(opt.input_nc, opt.netF, opt.normG, not opt.no_dropout, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids, opt)
# define feature extraction
if self.isTrain:
self.netD = networks.define_D(opt.output_nc, opt.ndf, opt.netD, opt.n_layers_D, opt.normD, opt.init_type, opt.init_gain, opt.no_antialias, self.gpu_ids, opt)
# define descriminator
# define loss functions
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
self.criterionNCE = []
for nce_layer in self.nce_layers: # nce_layers = 0, 4, 8, 12, 16
self.criterionNCE.append(PatchNCELoss(opt).to(self.device))
self.criterionIdt = torch.nn.L1Loss().to(self.device)
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=opt.lr, betas=(opt.beta1, opt.beta2))
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
def data_dependent_initialize(self, data):
"""
The feature network netF is defined in terms of the shape of the intermediate, extracted
features of the encoder portion of netG. Because of this, the weights of netF are
initialized at the first feedforward pass with some input images.
Please also see PatchSampleF.create_mlp(), which is called at the first forward() call.
"""
bs_per_gpu = data["A"].size(0) // max(len(self.opt.gpu_ids), 1)
self.set_input(data)
self.real_A = self.real_A[:bs_per_gpu]
self.real_B = self.real_B[:bs_per_gpu]
self.forward() # compute fake images: G(A)
if self.opt.isTrain:
self.compute_D_loss().backward() # calculate gradients for D
self.compute_G_loss().backward() # calculate graidents for G
if self.opt.lambda_NCE > 0.0:
self.optimizer_F = torch.optim.Adam(self.netF.parameters(), lr=self.opt.lr, betas=(self.opt.beta1, self.opt.beta2))
self.optimizers.append(self.optimizer_F)
def optimize_parameters(self):
# forward
self.forward()
# update D
self.set_requires_grad(self.netD, True)
self.optimizer_D.zero_grad()
self.loss_D = self.compute_D_loss()
self.loss_D.backward()
self.optimizer_D.step()
# update G
self.set_requires_grad(self.netD, False)
self.optimizer_G.zero_grad()
if self.opt.netF == 'mlp_sample':
self.optimizer_F.zero_grad()
self.loss_G = self.compute_G_loss()
self.loss_G.backward()
self.optimizer_G.step()
if self.opt.netF == 'mlp_sample':
self.optimizer_F.step()
def set_input(self, input):
"""Unpack input data from the dataloader and perform necessary pre-processing steps.
Parameters:
input (dict): include the data itself and its metadata information.
The option 'direction' can be used to swap domain A and domain B.
"""
AtoB = self.opt.direction == 'AtoB'
self.real_A = input['A' if AtoB else 'B'].to(self.device)
self.real_B = input['B' if AtoB else 'A'].to(self.device)
self.image_paths = input['A_paths' if AtoB else 'B_paths']
def forward(self):
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
self.real = torch.cat((self.real_A, self.real_B), dim=0) if self.opt.nce_idt and self.opt.isTrain else self.real_A
if self.opt.flip_equivariance:
self.flipped_for_equivariance = self.opt.isTrain and (np.random.random() < 0.5)
if self.flipped_for_equivariance:
self.real = torch.flip(self.real, [3])
self.fake = self.netG(self.real)
self.fake_B = self.fake[:self.real_A.size(0)]
if self.opt.nce_idt:
self.idt_B = self.fake[self.real_A.size(0):]
def compute_D_loss(self):
"""Calculate GAN loss for the discriminator"""
fake = self.fake_B.detach()
# Fake; stop backprop to the generator by detaching fake_B
pred_fake = self.netD(fake)
self.loss_D_fake = self.criterionGAN(pred_fake, False).mean()
# Real
self.pred_real = self.netD(self.real_B)
loss_D_real = self.criterionGAN(self.pred_real, True)
self.loss_D_real = loss_D_real.mean()
# combine loss and calculate gradients
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
return self.loss_D
def compute_G_loss(self):
"""Calculate GAN and NCE loss for the generator"""
fake = self.fake_B
# First, G(A) should fake the discriminator
if self.opt.lambda_GAN > 0.0:
pred_fake = self.netD(fake)
self.loss_G_GAN = self.criterionGAN(pred_fake, True).mean() * self.opt.lambda_GAN
else:
self.loss_G_GAN = 0.0
if self.opt.lambda_NCE > 0.0:
self.loss_NCE = self.calculate_NCE_loss(self.real_A, self.fake_B) # calculate NCE loss
else:
self.loss_NCE, self.loss_NCE_bd = 0.0, 0.0
if self.opt.nce_idt and self.opt.lambda_NCE > 0.0:
self.loss_NCE_Y = self.calculate_NCE_loss(self.real_B, self.idt_B)
loss_NCE_both = (self.loss_NCE + self.loss_NCE_Y) * 0.5
else:
loss_NCE_both = self.loss_NCE
self.loss_G = self.loss_G_GAN + loss_NCE_both
return self.loss_G
def calculate_NCE_loss(self, src, tgt):
n_layers = len(self.nce_layers) # 0, 4, 8, 12, 16
feat_q = self.netG(tgt, self.nce_layers, encode_only=True)
if self.opt.flip_equivariance and self.flipped_for_equivariance:
feat_q = [torch.flip(fq, [3]) for fq in feat_q]
feat_k = self.netG(src, self.nce_layers, encode_only=True)
feat_k_pool, sample_ids = self.netF(feat_k, self.opt.num_patches, None)
feat_q_pool, _ = self.netF(feat_q, self.opt.num_patches, sample_ids)
total_nce_loss = 0.0
for f_q, f_k, crit, nce_layer in zip(feat_q_pool, feat_k_pool, self.criterionNCE, self.nce_layers):
loss = crit(f_q, f_k) * self.opt.lambda_NCE
total_nce_loss += loss.mean()
return total_nce_loss / n_layers
위 코드가 cut_model.py 코드입니다. 하나하나 살펴보겠습니다.
def data_dependent_initialize(self, data):
"""
The feature network netF is defined in terms of the shape of the intermediate, extracted
features of the encoder portion of netG. Because of this, the weights of netF are
initialized at the first feedforward pass with some input images.
Please also see PatchSampleF.create_mlp(), which is called at the first forward() call.
"""
bs_per_gpu = data["A"].size(0) // max(len(self.opt.gpu_ids), 1)
self.set_input(data)
self.real_A = self.real_A[:bs_per_gpu]
self.real_B = self.real_B[:bs_per_gpu]
self.forward() # compute fake images: G(A)
if self.opt.isTrain:
self.compute_D_loss().backward() # calculate gradients for D
self.compute_G_loss().backward() # calculate graidents for G
if self.opt.lambda_NCE > 0.0:
self.optimizer_F = torch.optim.Adam(self.netF.parameters(), lr=self.opt.lr, betas=(self.opt.beta1, self.opt.beta2))
self.optimizers.append(self.optimizer_F)
위 코드가 train.py에서 forward와 backward를 실행시키기 위해 사용하는 함수입니다.
def forward(self):
"""Run forward pass; called by both functions <optimize_parameters> and <test>."""
self.real = torch.cat((self.real_A, self.real_B), dim=0) if self.opt.nce_idt and self.opt.isTrain else self.real_A
if self.opt.flip_equivariance:
self.flipped_for_equivariance = self.opt.isTrain and (np.random.random() < 0.5)
if self.flipped_for_equivariance:
self.real = torch.flip(self.real, [3])
self.fake = self.netG(self.real)
self.fake_B = self.fake[:self.real_A.size(0)]
if self.opt.nce_idt:
self.idt_B = self.fake[self.real_A.size(0):]
fake는 generator network에 real image를 넣어줍니다. real image는 real_A와 real_B를 concat 한 image입니다. fake_B는 fake 중에서 real_A를 generator에 넣어 생성한 image를 의미합니다. 즉 A domain image를 B domain image로 만들어낸 결과입니다. idt_B는 real_B를 generator에 넣어 생성한 이미지를 의미합니다. identity를 유지하기 위해 사용하는 image입니다.
def compute_D_loss(self):
"""Calculate GAN loss for the discriminator"""
fake = self.fake_B.detach()
# Fake; stop backprop to the generator by detaching fake_B
pred_fake = self.netD(fake)
self.loss_D_fake = self.criterionGAN(pred_fake, False).mean()
# Real
self.pred_real = self.netD(self.real_B)
loss_D_real = self.criterionGAN(self.pred_real, True)
self.loss_D_real = loss_D_real.mean()
# combine loss and calculate gradients
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
return self.loss_D
위 코드는 discriminator의 loss를 계산하는 함수입니다. 평소에 우리가 아는 discriminator loss를 구하는 것과 동일합니다.
def compute_G_loss(self):
"""Calculate GAN and NCE loss for the generator"""
fake = self.fake_B
# First, G(A) should fake the discriminator
if self.opt.lambda_GAN > 0.0:
pred_fake = self.netD(fake)
self.loss_G_GAN = self.criterionGAN(pred_fake, True).mean() * self.opt.lambda_GAN
else:
self.loss_G_GAN = 0.0
if self.opt.lambda_NCE > 0.0:
self.loss_NCE = self.calculate_NCE_loss(self.real_A, self.fake_B) # calculate NCE loss
else:
self.loss_NCE, self.loss_NCE_bd = 0.0, 0.0
if self.opt.nce_idt and self.opt.lambda_NCE > 0.0:
self.loss_NCE_Y = self.calculate_NCE_loss(self.real_B, self.idt_B)
loss_NCE_both = (self.loss_NCE + self.loss_NCE_Y) * 0.5
else:
loss_NCE_both = self.loss_NCE
self.loss_G = self.loss_G_GAN + loss_NCE_both
return self.loss_G
이 부분이 논문에서 언급한 PatchNCELoss 를 이용한 모습입니다.

논문에서 이와 같이 식을 정의했습니다.
다시 코드로 돌아가 먼저 discriminator에 fake_B를 넣어주고 예측한 값을 얻습니다. 이를 이용해 Gan loss를 구합니다. 그다음 loss_NCE를 구하는데 이 부분은 real_A와 fake_B를 이용해 구합니다. 이 값이 위 식에서 가운데에 존재하는 값입니다. loss_NCE를 구하는 calculate_NCE_loss 함수는 나중에 보겠습니다.
loss_NCE를 구하고 난 후 identity를 위해 만들었던 image idt_B와 real_B를 이용해 loss_NCE_Y를 구합니다. 이 부분이 위 식에서 제일 마지막에 존재하는 값입니다.
Gan loss와 (loss_NCE + loss_NCE_Y) * 0.5 를 더해 최종 generator에 대한 loss를 구합니다.
def calculate_NCE_loss(self, src, tgt):
n_layers = len(self.nce_layers)
feat_q = self.netG(tgt, self.nce_layers, encode_only=True)
if self.opt.flip_equivariance and self.flipped_for_equivariance:
feat_q = [torch.flip(fq, [3]) for fq in feat_q]
feat_k = self.netG(src, self.nce_layers, encode_only=True)
feat_k_pool, sample_ids = self.netF(feat_k, self.opt.num_patches, None)
feat_q_pool, _ = self.netF(feat_q, self.opt.num_patches, sample_ids)
total_nce_loss = 0.0
for f_q, f_k, crit, nce_layer in zip(feat_q_pool, feat_k_pool, self.criterionNCE, self.nce_layers):
loss = crit(f_q, f_k) * self.opt.lambda_NCE
total_nce_loss += loss.mean()
return total_nce_loss / n_layers
위 코드가 loss_NCE를 구하는 함수입니다. 저자가 제공한 코드 그대로 사용한다면 self.nce_layers = [0, 4, 8, 12, 16]입니다. 즉 해당 순서의 layer를 사용하게 됩니다. 그리고 src, tgt에 전달되는 값은 (real_A, fake_B) 또는 (real_B, idt_B)입니다. feat_q는 generator network에 tgt와 self.nce_layers를 전달합니다. return 된 값은 nce_layers에 해당하는 feature, 즉 각 순서에 맞는 5개의 feature가 구해집니다. feat_k는 src가 전달된 것 빼고 차이점은 없습니다.
그다음 netF에 feat_k와 num_patches가 전달되고 return 된 값은 feat_k_pool, sample_ids에 저장됩니다. 여기서 netF는 논문에서 언급한 feature extraction network입니다. netF를 거친 feat_k_pool은 각 layer 순서에 맞춰 256 크기의 feature들이 구해집니다. netF 내부를 보면 mlp가 존재하고 mlp를 거치고 거쳐 feature를 뽑아냅니다. 그리고 sample_ids는 patch_id 값을 의미합니다.
이번에는 netF에 feat_q 값을 전달해 feat_q_pool을 구합니다. 이제 이 두 값을 이용해 loss를 구합니다. critic은 PatchNCELoss를 의미하는데 이 함수를 보면 positive와 negative를 구한 다음 두 값을 concat 한 후 crossentropy loss를 적용해 loss를 구합니다. negative를 구하는 부분이 약간 복잡하지만 순차적으로 따라가다 보면 이해할 수 있습니다.
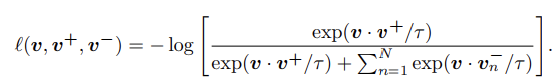
위 식이 논문에서 제시한 식이고 이를 PatchNCELoss로 구현한 모습입니다. 이렇게 loss들을 구해 backward를 하고 학습을 진행합니다.
'연구실 공부' 카테고리의 다른 글
| [ML] 1. MLE (0) | 2023.02.28 |
|---|---|
| KL Divergence, Jensen-Shannon Divergence (0) | 2023.02.18 |
| CycleGAN 논문 코드 (0) | 2023.02.07 |
| AutoEncoder(AE), Variant AutoEncoder(VAE) (0) | 2023.02.06 |
| [논문] Contrastive Learning for Unpaired Image-to-Image Translation (0) | 2023.01.03 |



