github : https://github.com/sovit-123/image-deblurring-using-deep-learning
GitHub - sovit-123/image-deblurring-using-deep-learning: PyTorch implementation of image deblurring using deep learning. Use a s
PyTorch implementation of image deblurring using deep learning. Use a simple convolutional autoencoder neural network to deblur Gaussian blurred images. - GitHub - sovit-123/image-deblurring-using-...
github.com
코드를 토대로 공부하고 작성했습니다.
이 코드는 blur 처리한 이미지와 정답 이미지를 가지고 CNN을 통해 학습해 deblur를 구현하는 내용입니다. 학습을 통해 최대한 원본 이미지와 비슷하게 만드는 모델을 생성하는 것이 목적입니다. 이미지 blur처리는 gaussian blulr를 사용했습니다.
먼저 gaussian blur가 어떤건지 알아보겠습니다.
gaussian blur는 많은 blurring 방식 중 하나입니다. gaussian blur는 gaussian 분포를 갖는 커널로 블러링을 적용한 것을 의미합니다.
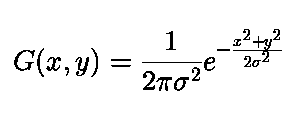
이 식은 2D일 때, 가우시안 형태를 보여주는 식입니다. 여기서 시그마는 표준편차를 의미합니다.
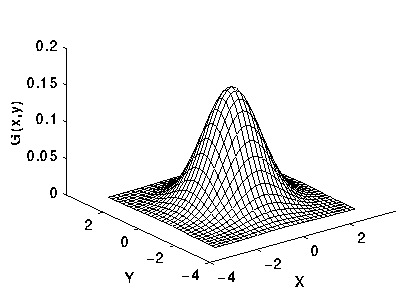
위 그래프는 가우시안 분포를 보여줍니다. 그래프를 보면 중심점에서 멀어질수록 낮은 값을 갖고 가까울수록 높은 값을 갖습니다. 즉 이미지에 이러한 가우시안 블러 처리를 한다면 중심점은 뚜렷하게, 멀어질수록 흐려지는 이미지를 얻게 됩니다.
예를 들어

이와 같은 원본 이미지가 있을 때 이를 gaussian blur 처리하면

이와 같이 흐릿해진 이미지를 얻을 수 있습니다.
먼저 이렇게 이미지를 blur 처리하는 코드 먼저 살펴보겠습니다.
import cv2
import os
from tqdm import tqdm
src_dir = '../input/sharp'
# 원본 이미지 가져오는 directory
images = os.listdir(src_dir)
dst_dir = '../input/gaussian_blurred'
# 블러 처리한 이미지를 저장하는 directory
for i, img in tqdm(enumerate(images), total=len(images)):
img = cv2.imread(f"{src_dir}/{images[i]}")
# add gaussian blurring
blur = cv2.GaussianBlur(img, (51, 51), 0) # kernel size = (51, 51), sigma = 0이면 kernel size에 따라 자동으로 sigma 결정되어 blur 처리
cv2.imwrite(f"{dst_dir}/{images[i]}", blur)
print('DONE')이와 같은 add_gaussian_blur.py 라는 코드가 있습니다. 이 코드를 통해 해당 경로에 존재하는 이미지들을 불러와 gaussian blur 처리해 저장합니다. 이는 train 할 때 쓸 이미지들을 blur 처리한 것입니다.
이러한 원본 이미지가

이와 같이 blur 처리된 것을 볼 수 있습니다.
이번에는 CNN model에 대해서 살펴보겠습니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
# CNN class 선언,
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 128, kernel_size=5, padding=1)
# conv2d(input channel = 3, output channel = 128, kernel size = 5x5, padding = 1)
self.conv2 = nn.Conv2d(128, 64, kernel_size=3, padding=1)
# conv2d(input channel = 128, output channel = 64, kernel size = 3x3, padding = 1)
self.conv3 = nn.Conv2d(64, 3, kernel_size=1, padding=1)
# conv2d(input channel = 64, output channel = 3, kernel size = 1x1, padding = 1)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
# forward 진행 시 convolution 결과를 활성화 함수(relu)에 적용
return x
class SimpleAE(nn.Module):
def __init__(self):
super(SimpleAE, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=5),
nn.ReLU(True),
nn.Conv2d(32, 64, kernel_size=5),
nn.ReLU(True))
# 위에 함수들을 순서대로 encoder에 저장
self.decoder = nn.Sequential(
nn.ConvTranspose2d(64, 32, kernel_size=5),
nn.ReLU(True),
nn.ConvTranspose2d(32, 3, kernel_size=5),
nn.ReLU(True))
# 위에 함수들을 decoder에 순서대로 저장
def forward(self,x):
x = self.encoder(x)
x = self.decoder(x)
return x
# forward 진행 시 encoder, decoder 진행이와 같이 CNN 진행 model을 생성했습니다. 이제 model을 통해 학습하는 코드를 살펴보겠습니다.
import numpy as np
import os
import matplotlib.pyplot as plt
import glob
import cv2
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import time
import albumentations
import argparse
import models
from tqdm import tqdm
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
from torchvision.utils import save_image
from sklearn.model_selection import train_test_split
def save_decoded_image(img, name):
img = img.view(img.size(0), 3, 224, 224) # 이미지가 들어오면 224*224 크기의 이미지로 만들어준다, 3은 rgb의미
save_image(img, name) # decoding된 이미지들을 저장하는 함수
class DeblurDataset(Dataset):
def __init__(self, blur_paths, sharp_paths=None, transforms=None):
self.X = blur_paths
# blur 처리된 이미지들
self.y = sharp_paths
# 원본 이미지들
self.transforms = transforms
def __len__(self):
return (len(self.X))
def __getitem__(self, i):
blur_image = cv2.imread(f"../input/gaussian_blurred/{self.X[i]}")
# 경로에 해당하는 이미지를 읽어온다(blur 처리된 이미지)
if self.transforms:
blur_image = self.transforms(blur_image)
# blur 처리된 이미지들을 transform 적용
if self.y is not None:
sharp_image = cv2.imread(f"../input/sharp/{self.y[i]}")
sharp_image = self.transforms(sharp_image)
# sharp 이미지들도 transform 적용
return (blur_image, sharp_image)
# 여기서 blur_image와 sharp_image 둘 다 읽어와 저장을 한다
else:
return blur_image
def fit(model, dataloader, epoch):
# 모델의 학습 코드
model.train()
running_loss = 0.0
for i, data in tqdm(enumerate(dataloader), total=int(len(train_data) / dataloader.batch_size)):
blur_image = data[0]
sharp_image = data[1]
blur_image = blur_image.to(device)
sharp_image = sharp_image.to(device)
optimizer.zero_grad() # gradient를 0으로 초기화
outputs = model(blur_image) # blur image를 통해 학습
loss = criterion(outputs, sharp_image) # 오차구하기
# backpropagation
loss.backward() # 오차를 이용해 기울기 구하기
# update the parameters
optimizer.step() # 인자들의 값 업데이트
running_loss += loss.item() # 총 오차 구하는 덧셈
train_loss = running_loss / len(dataloader.dataset)
print(f"Train Loss: {train_loss:.5f}")
return train_loss
# the training function
def validate(model, dataloader, epoch):
# validate 코드
model.eval()
running_loss = 0.0
with torch.no_grad():
for i, data in tqdm(enumerate(dataloader), total=int(len(val_data) / dataloader.batch_size)):
blur_image = data[0]
sharp_image = data[1]
blur_image = blur_image.to(device)
sharp_image = sharp_image.to(device)
outputs = model(blur_image)
loss = criterion(outputs, sharp_image)
running_loss += loss.item()
# 여기까지 train과 같이 진행
if epoch == 0 and i == (len(val_data) / dataloader.batch_size) - 1:
save_decoded_image(sharp_image.cpu().data, name=f"../outputs/saved_images/sharp{epoch}.jpg")
save_decoded_image(blur_image.cpu().data, name=f"../outputs/saved_images/blur{epoch}.jpg")
val_loss = running_loss / len(dataloader.dataset)
print(f"Val Loss: {val_loss:.5f}")
# 오차를 구함
save_decoded_image(outputs.cpu().data, name=f"../outputs/saved_images/val_deblurred{epoch}.jpg")
return val_loss
# 이를 통해 50번 반복을 하는데 나온 결과들의 이미지가 저장된다
# constructing the argument parser
# parser을 이용해 매개변수들을 작성할 수 있다. 여기서는 integer 형태로 default 값 50으로 “e”, “epochs”라는 두개의 매개변수 생성
parser = argparse.ArgumentParser()
parser.add_argument('-e', '--epochs', type=int, default=50,
help='number of epochs to train the model for')
args = vars(parser.parse_args())
# helper functions
image_dir = '../outputs/saved_images'
os.makedirs(image_dir, exist_ok=True)
# 해당 주소에 폴더를 생성 이 폴더에는 deblur하는 과정들의 이미지를 저장할 것이다
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
# gpu 사용을 위해 선언한 코드
print(device)
batch_size = 2
gauss_blur = os.listdir('../input/gaussian_blurred/')
gauss_blur.sort() # 해당 폴더에 존재하는 파일들을 정렬
sharp = os.listdir('../input/sharp')
sharp.sort() # 해당 폴더에 존재하는 파일들을 정렬
# gauss_blur에 blur처리한 이미지를 저장하고 sharp에는 원본 이미지를 저장
x_blur = []
for i in range(len(gauss_blur)):
x_blur.append(gauss_blur[i])
# x_blur에 blur처리된 이미지 정보 저장
y_sharp = []
for i in range(len(sharp)):
y_sharp.append(sharp[i])
# y_sharp에 원본 이미지 정보 저장
print(x_blur[10])
print(y_sharp[10])
(x_train, x_val, y_train, y_val) = train_test_split(x_blur, y_sharp, test_size=0.25)
# test_size를 0.25로 설정하고 데이터들을 train, valid, test로 분류하는 코드
print(len(x_train))
print(len(x_val))
# define transforms
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# compose를 사용해 transform을 정의, ToPILImage는 Tensor에서 PILImage로 변경, Resize는 224*224로 사이즈 변경, ToTensor는 Tensor 형태로 데이터를 변경
train_data = DeblurDataset(x_train, y_train, transform)
val_data = DeblurDataset(x_val, y_val, transform)
# 전에 분류했던 데이터(train, valid)를 DeblurDataset에 적용해 코드 실행
trainloader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
valloader = DataLoader(val_data, batch_size=batch_size, shuffle=False)
# dataloader를 이용해서 DeblurDataset을 통해 저장된 데이터들을 불러와 batch_size=2, trainloader은 랜덤하게 들어오고 valloader는 일정하게 들어온다
model = models.CNN().to(device)
print(model)
# the loss function
criterion = nn.MSELoss()
# loss함수 정의(Mean Squared Error 사용)
# the optimizer
optimizer = optim.Adam(model.parameters(), lr=0.001)
# optimizer 선언(adam함수 사용, learning rate = 0.001)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer,
mode='min',
patience=5,
factor=0.1,
verbose=True
)
# 학습을 할 때 더 이상 성능 향상이 없으면 learning rate를 감소하는 코드, mode = ‘min’으로 값이 감소하는 것을 의미, patience = 5는 epoch 5만큼 학습이 되지 않아도 참는다는 것을 의미, factor = 0.1은 learning rate 감소 범위를 의미
train_loss = []
val_loss = []
# 위에 선언한 함수들을 통해 오차를 구할 것인데 그 오차들을 저장할 list 생성
start = time.time()
# 프로그램이 시작되는 현재 시간을 start에 저장
for epoch in range(args['epochs']):
# 처음에 args를 선언했고 이는 50으로 저장되어 있다. 즉 반복을 50번 진행
print(f"Epoch {epoch + 1} of {args['epochs']}")
train_epoch_loss = fit(model, trainloader, epoch)
val_epoch_loss = validate(model, valloader, epoch)
train_loss.append(train_epoch_loss)
val_loss.append(val_epoch_loss)
scheduler.step(val_epoch_loss)
# train, validate 둘 다 진행하고 오차를 저장, scheduler도 진행
end = time.time()
# 학습이 종료된 시간 end에 저장
print(f"Took {((start - end) / 60):.3f} minutes to train")
# 걸린 시간 출력
# loss plots
plt.figure(figsize=(10, 7))
plt.plot(train_loss, color='orange', label='train loss')
plt.plot(val_loss, color='red', label='validataion loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.savefig('../outputs/loss.png')
plt.show()
# 오차를 그래프로 그림
# save the model to disk
print('Saving model...')
torch.save(model.state_dict(), '../outputs/model.pth')
이와 같이 학습을 하는 코드가 있습니다. 학습한 결과

이와 같이 이미지들이 학습되는 것을 볼 수 있습니다. 이렇게 학습한 model을 통해 test를 해보겠습니다.
import numpy as np
import os
import matplotlib.pyplot as plt
import glob
import cv2
import models
import torch
from torchvision.transforms import transforms
from torchvision.utils import save_image
def save_decoded_image(img, name):
img = img.view(img.size(0), 3, 224, 224)
save_image(img, name)
device = 'cpu'
# load the trained model
model = models.CNN().to(device).eval()
# eval을 통해 자동 학습 off
model.load_state_dict(torch.load('../outputs/model.pth'))
# 학습한 모델(매개변수 및 학습 결과가 dictionary 형태로 저장) 불러오는 코드
# define transforms
transform = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# transform 정의, Tensor에서 PILImage로 변경, Resize = 224x224, 그 후 Tensor로 다시 저장
name = 'image_1'
image = cv2.imread(f"../test_data/gaussian_blurred/{name}.jpg")
# 해당 경로에 존재하는 이미지를 불러온다
orig_image = image.copy()
orig_image = cv2.resize(orig_image, (224, 224))
# 불러온 이미지 크기를 224x224로 변경
cv2.imwrite(f"../outputs/test_deblurred_images/original_blurred_image_2.jpg", orig_image)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 해당 경로 이미지를 불러와 BGR 형식이 아닌 RGB 형식으로 변환해서 저장, 이렇게 하는 이유는
# OpenCV에서는 BGR 형식으로 저장을 하기 때문에 이와 같이 변경해주어야 한다
image = transform(image).unsqueeze(0)
print(image.shape)
with torch.no_grad():
outputs = model(image)
save_decoded_image(outputs.cpu().data, name=f"../outputs/test_deblurred_images/deblurred_image_2.jpg")
이러한 test.py를 통해 결과를 얻을 수 있고

위 이미지는 gaussian blur 처리를 통해 얻은 image이고

model을 통해서 만든 deblurred image입니다.
'연구실 공부' 카테고리의 다른 글
| Image deblurring using DeblurGAN(base_model.py, models.py, test_models.py) (0) | 2022.03.09 |
|---|---|
| Image deblurring using DeblurGAN(data) (0) | 2022.03.09 |
| Image deblurring using DeblurGAN(options, datasets) (0) | 2022.03.09 |
| Image deblurring using DeblurGAN (0) | 2022.03.07 |
| Resnet, Unet, GAN 구조 (0) | 2022.02.25 |


