https://github.com/KupynOrest/DeblurGAN
GitHub - KupynOrest/DeblurGAN: Image Deblurring using Generative Adversarial Networks
Image Deblurring using Generative Adversarial Networks - GitHub - KupynOrest/DeblurGAN: Image Deblurring using Generative Adversarial Networks
github.com
https://arxiv.org/abs/1711.07064
DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks
We present DeblurGAN, an end-to-end learned method for motion deblurring. The learning is based on a conditional GAN and the content loss . DeblurGAN achieves state-of-the art performance both in the structural similarity measure and visual appearance. The
arxiv.org
토대로 공부하고 작성했습니다.
1. Introduction
이 코드와 논문은 GAN 구조를 이용해 image-to-image deblurring을 합니다. DeblurGAN은 conditional generative adversarial networks와 multi-component loss function을 base로 한 접근 방법입니다. 그리고 DeblurGAN은 gradient penalty와 perceptual loss와 함께 Wasserstein GAN을 사용합니다.
먼저 큰 구조부터 살펴보겠습니다.
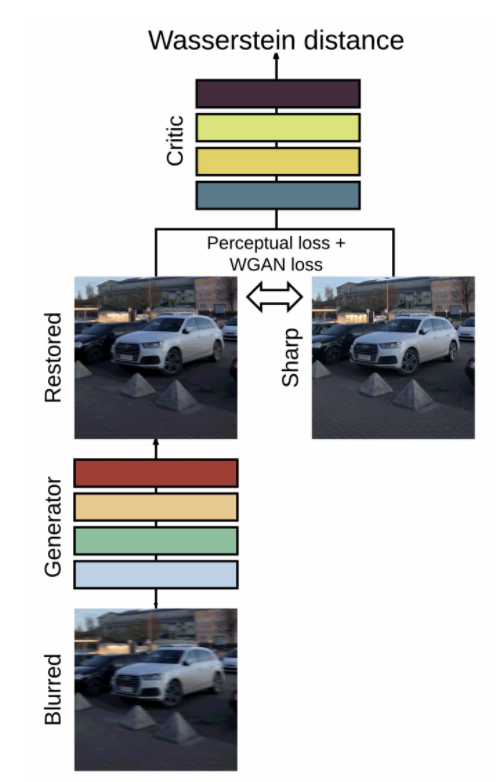
그림으로 나타내면 위와 같습니다. blur 처리된 원본 이미지를 토대로 generator가 복원한 이미지를 만들고 원본 이미지와 복원된 이미지의 오차를 구하는 과정을 거칩니다. critic network에서 복원한 이미지와 원본 이미지를 가지고 서로의 거리를 구합니다. WGAN의 총오차는 critic network에서 구한 값과 perceptual loss의 값을 더한 값이 됩니다(perceptual loss의 값은 원본 이미지와 복원된 이미지의 오차입니다).
2. Related work
■ Image Deblurring
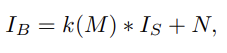
위 식은 이미지를 blur 처리하는 식입니다. I_B가 의미하는 값은 블러처리한 이미지이고, k(M)은 motion field M에 의해서 결정되는(generator에게 blur kernel에 대한 정보는 주어지지 않습니다) blur kernels를 의미합니다. I_s는 원본 이미지를 의미합니다. 마지막 N은 추가되는 노이즈입니다. input으로 주어지는 blurred image I_B로 sharp image(원본 이미지)를 구하는 것이 최종 목표입니다.
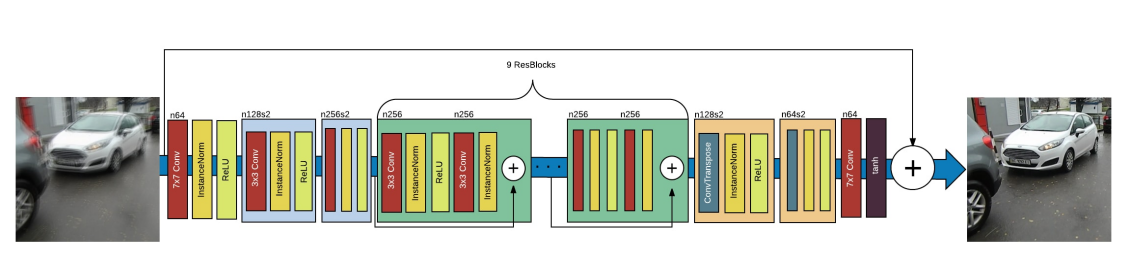
위 그림은 DeblurGAN의 generator의 CNN구조입니다. 2개의 strided convolution block(stride 1/2), 9개의 residual blocks(ResBlocks), 2개의 transposed convolution block을 포함합니다. 각 ResBlock은 convolution layer와 instance normalization layer와 ReLU activation을 포함하고 있습니다. 0.5 비율로 설정한 Dropout regularization을 각각의 ResBlock의 첫 번째 convolution layers 뒤에 추가했습니다.
그리고 ResOut이라고 불리는 global skip connection을 사용했습니다. 이 방법을 이용하면 CNN은 blurred image I_B에 대한 residual correction IR을 학습합니다.

식으로 나타내면 위와 같습니다. 이러한 방식은 training을 빠르게 만들어 주고, model generalize 결과를 더 좋게 만들어 줍니다.
■ Generative adversarial networks
generative adversarial networks는 Goodfellow에 의해 소개되었고, discriminator와 generator의 경쟁을 하면서 학습하는 구조입니다. generator는 노이즈를 input으로 받고 샘플을 만듭니다. discriminator는 원본 이미지와 generator가 sample 이미지를 받아 구별합니다. generator의 목표는 discriminator가 원본 이미지와 sample 이미지를 구분하지 못하게 속이는 것입니다.
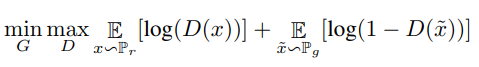
위 식에서 G는 generator, D는 discriminator를 의미합니다. D(x)는 원본이미지로 판단할 확률을 의미하고 D(~x)는 생성한 이미지를 원본 이미지로 판단할 확률을 의미합니다. 즉 discriminator는 log(D(x))의 값을 크게 만들어야 하고 log(1 - D(~x))의 값을 크게, 즉 D(~x)의 값을 작게 만들어야 합니다.
위와 같은 vanilla GAN는 model collapse, vanishing gradients와 같은 문제점들이 존재합니다.
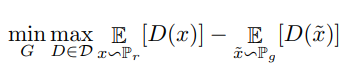
위 식은 WGAN 구조입니다. 이는 Earth-Mover(EM)거리의 근사를 최소화하는 방법을 이용해 wasserstein 거리의 하한을 적용한 모델입니다. 기존 GAN보다 학습 안정성 향상과 generator와 discriminator의 훈련에 있어 균형을 유지할 필요가 없습니다. 하지만 가중치 클리핑으로 인해 샘플 생성 오작동의 단점이 있습니다.

위 식은 WGAN-GP 구조입니다. WGAN에서 가중 클리핑 때문에 샘플을 생성할 때 오작동을 합니다. 이때 gradient vanishing, gradient exploding 이 일어나기 때문에 critic에서 gradient의 norm에 penalty를 적용하는 방식입니다. discriminator의 목적 함수에 페널티를 추가하고 1에서 멀어지면 페널티를 적용합니다.
3. The proposed method
목표는 blur 처리된 이미지를 input으로 원본 이미지와 최대한 똑같이 복원하는 것입니다. Deblurring은 CNN으로 학습된 generator가 진행합니다.
■ Loss function
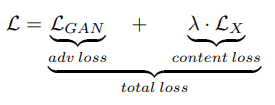
이 논문에서 오차 함수를 content loss와 adversarial loss의 합으로 표현합니다. 위 식에 λ는 모든 실험에서 100을 적용합니다. input과 output 사이의 mismatch를 penalize를 하지 않아도 되기 때문에, discriminator에 따로 condition이 없습니다.
■ Adversarial loss
conditional GAN과 관련된 대부분의 논문에서 loss로 vanila GAN objective를 사용합니다. 하지만, 최근에는 안정적인 GAN을 사용해 안정적이며 고품질의 결과를 생성합니다. 이 논문에서 WGAN-GP loss를 critic function으로 사용했습니다.

이 식은 adversarial loss의 식을 나타냅니다. GAN 요소 없이 학습된 DeblurGAN은 수렴하지만, smooth하고 blurry한 이미지를 만듭니다.
■ Content loss
Content loss의 두 가지 고전적인 방법이 있는데 L1(MAE loss), L2(MSE loss)입니다. 하지만 이 논문에서 deblurGAN은 perceptual loss를 사용합니다. perceptual loss는 간단한 L2-loss이지만, 생성된 이미지와 원본 이미지의 CNN 특징 맵의 차이를 기반으로 합니다.
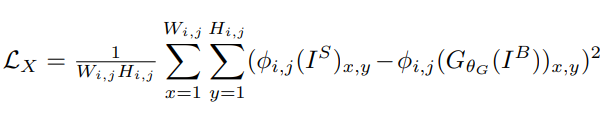
식은 위와 같습니다.
perceptual loss는 일반적인 내용의 복원에 초점이 맞춰져 있지만 adversarial loss는 texture detail에 초첨을 맞추고 있습니다.
논문의 내용은 위와 같습니다. 앞으로 github에 올라온 코드를 분석하고 이미지 deblur를 해보겠습니다.
'연구실 공부' 카테고리의 다른 글
| Image deblurring using DeblurGAN(base_model.py, models.py, test_models.py) (0) | 2022.03.09 |
|---|---|
| Image deblurring using DeblurGAN(data) (0) | 2022.03.09 |
| Image deblurring using DeblurGAN(options, datasets) (0) | 2022.03.09 |
| Resnet, Unet, GAN 구조 (0) | 2022.02.25 |
| image-deblurring-using-deep-learning (0) | 2022.02.21 |


