1. ResNet 구조
2015년 ILSVRC에서 우승을 차지한 ResNet은 마이크로소프트에서 개발한 알고리즘입니다. 원 논문명은 "Deep Residual Learning for Image Recognition"입니다. 이 전까지 CNN이 이미지 인식 분야에서 뛰어난 성능을 보여주고 있었고, 네트워크의 layer를 깊이 쌓으며 성능 향상을 이루고 있었습니다. 하지만 실제로 layer를 깊게 쌓게 되면 gradient vanishing / exploding이 일어나고 성능은 더 떨어지는 일이 발생했습니다. 원인은 layer가 깊어지면서 back propagation을 통해 얻어지는 기울기가 너무 작아지거나 너무 커지기 때문입니다. 또 layer가 깊어지면 학습이 어려워지는데 이는 overfitting 때문이 아니라 깊이가 깊어져 training error가 증가하기 때문입니다(파라미터 수가 많아지기 때문).
이러한 문제를 해결하기 위해 사용한 방법이 Residual Learning입니다.
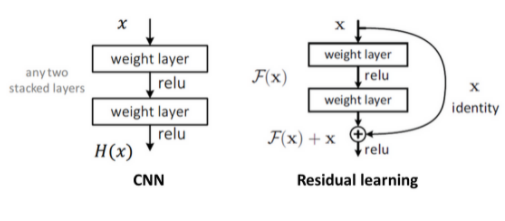
기존 CNN구조는 입력 값 x를 타깃 값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었습니다. 그러나 ResNet은 F(x) + x를 최소화하는 것을 목적으로 합니다. 위 그림은 x가 두 합성곱 계층을 건너뛰어 출력에 바로 연결되어 F(x) + x가 됩니다. 이렇게 스킵 연결을 통해 ResNet은 F(x) + x를 최소화하는 것을 목표로 합니다. 이러한 구조가 쌓이면 ResNet이 됩니다.
CIFAR-10 데이터 셋을 가지고 실험한 결과
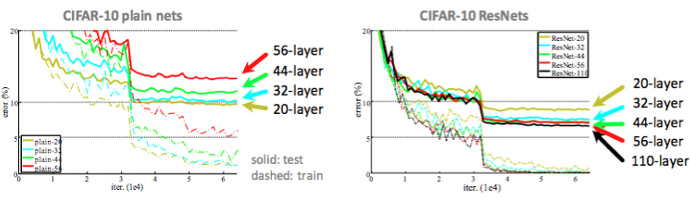
이와 같이 ResNet 구조가 학습이 더 잘 되는 것을 볼 수 있습니다. 특히 층이 깊어져도 ResNet 구조를 사용한 경우 결과가 더 좋아지는 것을 볼 수 있습니다. 즉 ResNet이 효과적이라는 것을 보여줍니다.
2. U-Net 구조
U-net은 2015년 5월 경에 게제되었으며, biomedical 분야에서 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End(입력에서 출력까지 파이프라인 네트워크(전체 네트워크를 이루는 부분적인 네트워크) 없이 한 번에 처리한다는 뜻) 방식의 Fully-Convolution Network 기반 모델로 적은 데이터를 가지고도 더욱 정확한 Segmentation을 낼 수 있습니다.
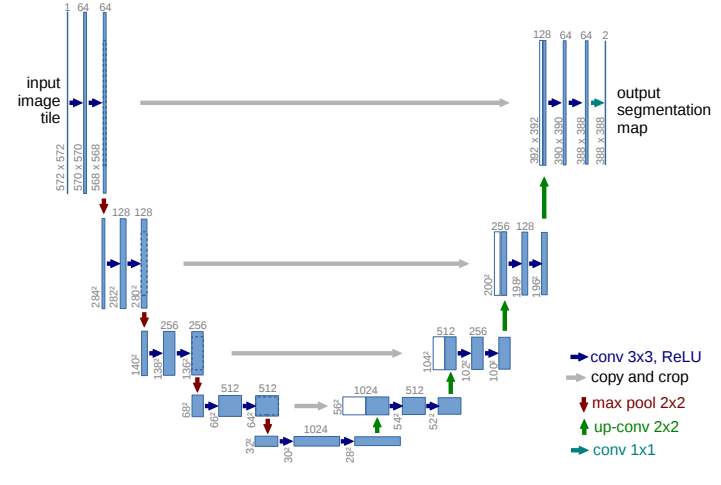
이름이 U-Net인 이유는 위 그림을 보면 알 수 있습니다. 모델이 'U'와 비슷하게 생겨서 U-Net이라 불립니다.
위 network는 두 부분으로 분류할 수 있습니다.
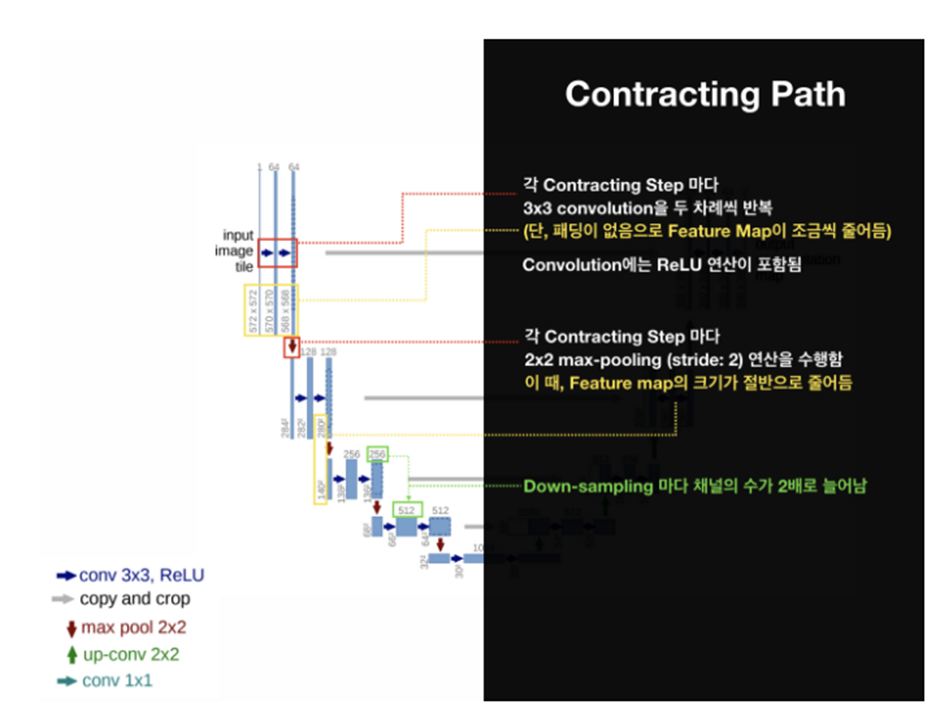
먼저, 이미지의 전반적인 컨텍스트 정보를 얻기 위한 네트워크인 Contracting Path가 있습니다. 여기서 말하는 컨텍스트란 이웃한 픽셀 간의 정보를 의미하고 다시 말해 이미지의 문맥을 의미합니다. Contracting Path는 일반적인 CNN 구조를 따르며, donwsampling(sample의 개수를 줄이는 처리과정)을 위한 stride 2, max pooling 연산과 ReLU를 포함한 두 번의 반복된 3x3 unpadded convolutions 연산을 거칩니다. 즉, 3x3 conv -> ReLU -> 2x2 max pooling -> 3x3 conv -> ReLU -> 2x2 max pooling 과정을 거칩니다. 이렇게 되면 특징 맵의 크기는 감소합니다. downsampling을 할 때마다 채널의 수를 2배 증가시키면서 진행합니다.
이 부분은 간단하게 보면 encoding하는 과정이라 볼 수 있습니다.
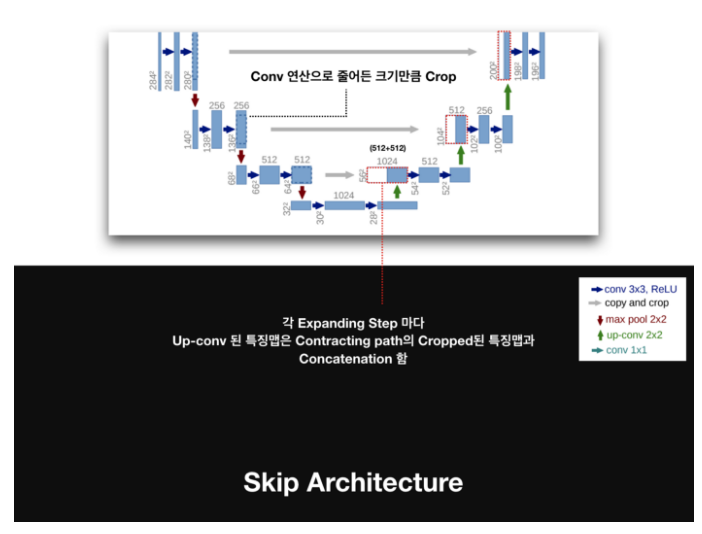
그다음 부분으로 skip architecture가 존재하는데 이는 각 Expanding Step 마다 up-convolution 한 특징맵과 contracting path의 cropped(잘라진)된 특징맵과 붙이는 역할을 합니다.
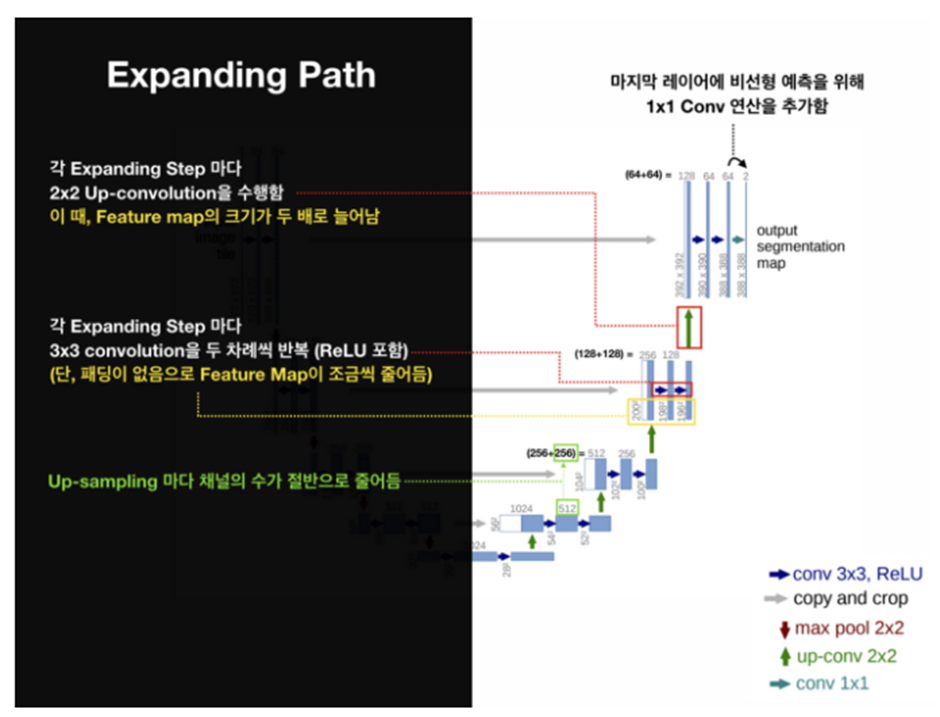
또 다른 부분으로 Expanding Path가 있는데 Contracting Path에서 나온 최종 특징 맵으로부터 높은 해상도의 segmentation 결과를 얻기 위해 여러 번 Upsampling을 합니다. skip architecture에서 얻은 특징맵을 ReLU 연산을 포함한 두 번의 3x3 convolution 연산을 합니다. 이러한 과정을 반복하면 마지막에 class의 개수만큼 필터를 갖고 있는 1x1 convolution layer가 있는데 이 layer를 통과한 후 각 픽셀이 어떤 class에 해당하는지에 대한 정보를 나타내는 3차원 벡터(Width x Height x Class)가 생성됩니다. 간단하게 보면 이 부분은 decoding 하는 과정이라 볼 수 있습니다.
이러한 U-Net은 적은 양의 학습 데이터로도 data augmentation(데이터 증강)을 활용해 우수한 성능을 보이고 속도도 빠르고 이미지의 크기를 줄이면서도 이미지 내의 중요한 정보를 직접 전달해 Expanding path를 진행하기 때문에 선명한 이미지를 얻을 수 있다는 장점이 있습니다.
3. GAN 구조
GAN(Generative Adversarial Network)의 단어 하나하나 뜻을 먼저 살펴보겠습니다. 'Generative'는 '생산적인, 생산하는'이라는 뜻으로, GAN 모델 안에서는 '이미지를 생성한다' 라는 의미를 가집니다. 'Adversarial'은 '적대적인'이라는 뜻으로, 서로 경쟁하면서 무엇인가를 좋게 하는 의미입니다. GAN 모델 안에서는 '이미지를 만들긴 하는데 서로 경쟁하면서 좋게 만든다'라는 의미가 됩니다. 따라서 GAN은 서로 경쟁하면서 가짜 이미지를 진짜 이미지와 최대한 비슷하게 만들어내는 네트워크를 말합니다.
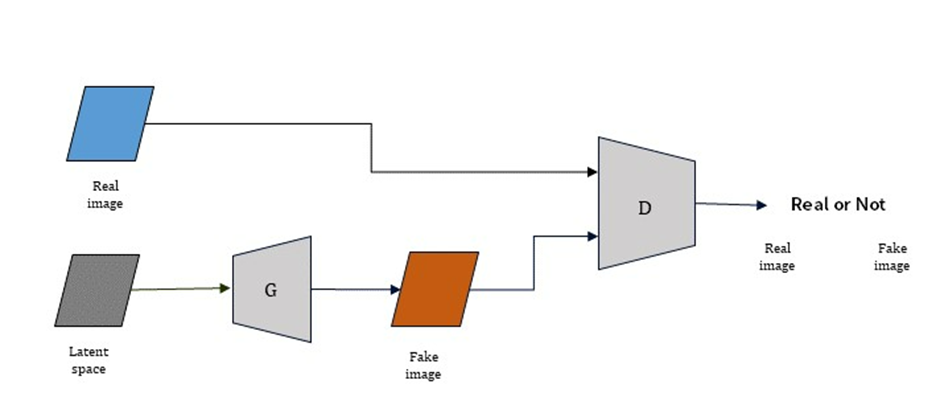
GAN의 구조는 위와 같이 나타낼 수 있습니다. Discriminator(판별기)와 Generator(생성기)로 구성되어 있습니다.
먼저 Discrimantor는 Generator에서 만든 fake image와 원본 이미지(real image)를 입력으로 받아 진짜 이미지인지 가짜 이미지인지 0과 1로 판별하는 역할을 합니다.
Generator는 latent sample(노이즈)를 통해, 가짜 데이터를 생성하는 역할을 합니다.
Generator는 노이즈를 통해 완벽하게 알지 못하는 원본 데이터의 분포를 통해 진짜 이미지와 비슷한 가짜 이미지를 계속 만들어 최대한 Discriminator를 속이는 것이 목표이고 Discriminator는 최대한 정확하게 이미지를 판별하는 것이 목표입니다. 이렇게 Generator와 Discriminator는 학습이 되어 점차 성능이 개선되고 궁극적으로 Discriminator가 실제 데이터와 가짜 데이터를 구분하지 못하게 만드는 것이 목표입니다.
학습 순서를 보면
- 훈련 데이터(원본 이미지)를 가지고 Discriminator를 학습시킵니다. 이를 통해 데이터의 분포를 얻게 되고 판별기는 원본 데이터를 진짜로 분류하고 가짜 데이터는 가짜로 분류하는 학습을 합니다.
- latent를 통해 노이즈된 값을 Generator에 주고 Generator는 가짜 이미지를 생성합니다. 학습이 진행될수록 점점 원본 이미지와 비슷한 가짜 이미지를 생성합니다.
- 생성된 이미지는 Discriminator에 전달되고 Discriminator는 가짜 데이터와 진짜 데이터를 구별(확률을 구한다)하게 되고 오차 역전파를 통해 Generator를 좀 더 진짜 데이터로 만들 수 있는 방향으로 학습하게 됩니다.
- 이러한 과정을 반복
위와 같은 과정을 반복하면
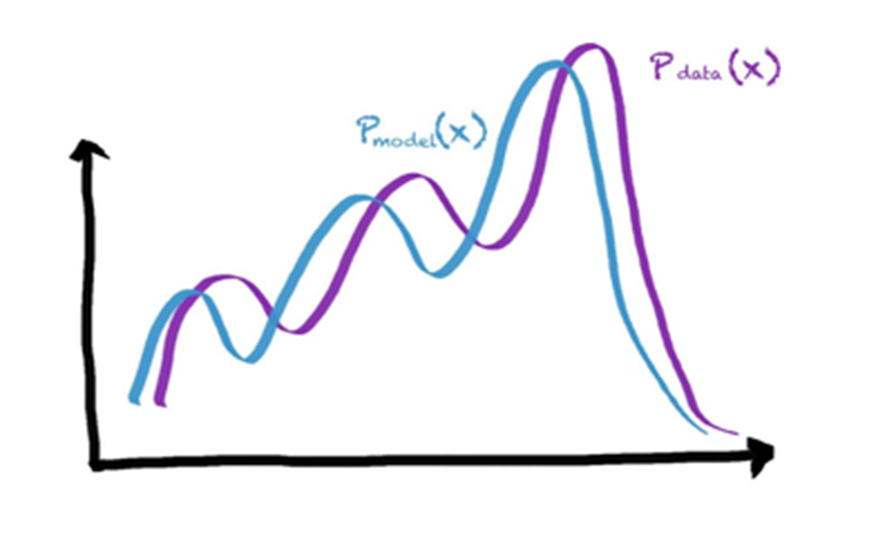
Generator에서 생성한 데이터의 분포는 Discriminator에서 원본 데이터를 통해 얻은 분포를 유사하게 따라가는 형태가 됩니다.
이러한 GAN 구조는 새로운 개념의 이미지 생성 방법이라는 장점이 있습니다. 하지만 데이터의 분포를 따라가다 보니, 어떤 데이터가 나올지 모른다는 문제가 있습니다.
'연구실 공부' 카테고리의 다른 글
| Image deblurring using DeblurGAN(base_model.py, models.py, test_models.py) (0) | 2022.03.09 |
|---|---|
| Image deblurring using DeblurGAN(data) (0) | 2022.03.09 |
| Image deblurring using DeblurGAN(options, datasets) (0) | 2022.03.09 |
| Image deblurring using DeblurGAN (0) | 2022.03.07 |
| image-deblurring-using-deep-learning (0) | 2022.02.21 |


