https://arxiv.org/abs/2401.08095
DurFlex-EVC: Duration-Flexible Emotional Voice Conversion Leveraging Discrete Representations without Text Alignment
Emotional voice conversion (EVC) involves modifying various acoustic characteristics, such as pitch and spectral envelope, to match a desired emotional state while preserving the speaker's identity. Existing EVC methods often rely on text transcriptions or
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Emotional voice conversion (EVC)는 speaker identity는 유지한 채로 pitch, spectral envelope과 같은 다양한 acoustic characteristic을 변경하여 원하는 감정 상태로 match 합니다. 기존의 EVC method들은 text transcription이나 time-alignment information을 필요로 하며, 가변 길이의 speech duration을 효과적으로 처리하는 데 어려움을 겪습니다. 이 논문에서 저자들은 DurFlex-EVC라는 duration-flexible EVC framework를 제안합니다. 이는 text 또는 alignment information 없이 수행 가능합니다. speech와 discredte unit representing content를 align 함으로써 문맥적 정보를 modeling 하는 unit aligner를 제안하며, 이를 통해 text or speech-text alignment의 필요성을 제거하였습니다. 추가적으로 효과적으로 content와 emotion style을 분리할 수 있는 style encoder를 design 하였으며, 이를 이용해 speech의 emotional characteristic을 정밀히 조작할 수 있습니다. 계층적 stylize encoder를 통해 emotional expressiveness를 향상시켰습니다. 계층적 stylize encoder는 target emotion style을 여러 계층적 level에서 반영하고, 변환된 speech의 표현력과 자연스러움을 향상시키기 위해 stylization process를 세분화하였습니다. subjective and objective 실험 결과를 통해 저자들의 method가 baseline model보다 뛰어남을 보였으며, 길이 변화를 잘 다루고 감정 표현력을 향상시켰습니다.
Introduction
Emotional voice conversion (EVC)는 speaker identity는 유지한 채로 원하는 감정 상태로 변경하기 위해, pitch and spectral envelope과 같은 다양한 음성 characteristic을 수정하는 작업을 포함합니다. 이는 의도된 감정과 align 하기 위해 prosody를 조정하는 과정이 필수적입니다. 억양, 리듬, 에너지를 포함한 prosody element는 emotion을 전달하고 인식하는 데 중요한 역할을 합니다. emotion conversion을 위해 prosody를 control 하는 것의 concept는 직관적으로 appealing 하지만, 각 prosody component를 세밀하게 조정하는 것은 상당히 어려운 과제입니다.
초기 EVC 방식은 GMM을 사용하여 spectrral 및 prosody feature를 변환하여 expressive voice를 생성하였습니다. 이후 autoencoder 기반 방법이 등장하면서 non-parallel data로 학습할 수 있는 data-driven EVC가 등장하였습니다. 이와 함께 VAE-based and GAN-based framework도 등장하였습니다. 그러나 이 방식들은 감정 표현에서 rhythm의 중요성을 간과하여 duration을 유지한 채로 conversion을 수행했습니다.
Sequence-to-Sequence (Seq2Seq) model은 implicit하게 duration을 modeling 할 수 있으며, 중요한 발전으로 주목받고 있습니다. 이러한 model들은 TTS model을 통합한 two-stage learning approach와 같은 방식을 이용해 안정성을 향상시켰습니다. 하지만 Seq2Seq model은 long-term dependency 문제와 repetition 문제가 존재하며, parallel generation이 필요하다는 문제가 존재합니다. parallel generation은 명시적은 duration modeling이 필요한데, 대부분의 voice conversion model들은 TTS model에서 추출한 phoneme length 정보를 활용합니다. 정보를 활용하기 위해선, pretrained autoregressive TTS model이나 external forced alginment tool을 사용해야 합니다.
최근에는 self-supervised learning representation에서 얻은 discrete speech unit을 이용해 parallel generation 문제를 완화하였습니다. 일부 연구에서는 speech emotion conversion을 translation task로 modeling 하여 parallel audio generation을 가능하게 만들었습니다. 하지만 이러한 방법들은 여전히 autoregressive model을 사용하며, fully parallel generation에 대한 한계가 존재합니다.
이 논문에서 저자들은 duration-flexible EVC framework인 DurFlex-EVC를 제안합니다. 이는 text나 alignment information을 필요로 하지 않으며 parallel generation이 가능합니다. content를 modeling 하기 위해 discrete speech unit을 사용하고 풍부한 acoustic detail을 표현하기 위해 self-supervised representation을 통합합니다. 저자들의 model은 unit sequence와 그에 대한 duration을 예측하여 flexible duration control이 가능합니다. 저자들의 contribution은 다음과 같습니다.
- DurFlex-EVC라는 duration-flexible EVC framework을 제안합니다. 이는 content modeling을 위해 discrete speech unit을 사용하고, parallel generation을 수행할 수 있고 text나 external alignment information을 필요로 하지 않습니다.
- unit aligner를 이용해 speech feature와 unit sequence 사이 문맥적 관계를 modeling 합니다. 이를 통해 text-based alignment에 의존하지 않고 duration을 효과적으로 control 할 수 있습니다.
- input feature에서 emotion style을 분리하고 reintroduce 할 수 있는 style encoder를 제안하며, 이는 content-style disentanglement를 이용합니다.
- 계층적 stylize encoder를 design 하여 global and local emotional pattern을 capture 하였으며, emotional speech의 표현력을 향상시켰습니다.
- extensive subjective and objective evaluation을 통해, 저자들이 제안한 model의 우수성을 입증하였습니다.
Proposed Method
저자들은 DurFlex-EVC라는 duration-flexible and parallel generation framework를 제안하며, emotional voice conversion을 수행합니다. 저자들은 seq2seq structure 의존성과 external text or alignment information이 필요하다는 이전 연구들의 한계를 극복하였습니다. 저자들의 model의 key component는 다음과 같습니다.
- Feature extractor: raw audio waveform을 acoustic feature로 변환합니다.
- Style autoencoder: input feature에서 emotional style을 분리하고 target emotional style을 이용해 seq2seq dependency 없이도 content-style disentanglement를 수행합니다.
- Unit aligner: stylized feature를 unit-level content로 변환하며, 이를 통해 문맥적 정보를 capture 하고 duration을 조절할 수 있습니다.
- Hierarchical stylize encoder: unit and frame level의 emotional style 둘 다 사용하여 stylistic nuance를 잘 capture 할 수 있도록 만들었습니다.
- Diffusion-based generator: pre-trained vocoder를 통해 speech로 변환될 high-quality Mel-spectrogram을 생성합니다.
Overview

위 그림은 DurFlex-EVC의 overview를 보여줍니다. raw audio waveform을 acoustic feature로 변환하는 feature extractor로 시작합니다. Mel-spectrogram이나 SSL output과 같은 다양한 feature representation이 존재하지만, 저자들은 HuBERT의 마지막 layer representation을 사용하였습니다. speech에 있는 emotion 특징을 정확하게 modeling 하기 위해선 종합적인 acoustic information이 필수적이며, 이를 얻을 수 있는 continuous representation인 HuBERT의 last layer를 선택하였습니다. 그 다음 style autoencoder가 input feature에서 emotional style을 분리하고 desired target emtoion을 적용합니다. 분리를 통해 content와 style을 독립적으로 관리할 수 있게 되며, seq2seq structure 없이도 emotional adaptation을 가능하게 만들어 줍니다. 그 다음 unit aligner가 cross-attention module을 통해 frame level의 문맥적 정보를 aggregate하여 stylized feature를 처리합니다. 이 aggregated representation은 unit level로 압축되고 계층적 style encoder에서 사용됩니다. 계층적 stylize encoder는 unit and frame level 모두 사용하며, emotional style을 다양한 sacle로 refine하여 일관성과 표현력을 향상시켰습니다. 최종적으로 계층적 stylize encoder의 output과 style vector으로부터 diffusion-based generator로 high-quality Mel-spectrogram을 합성합니다. 이 Mel-spectrogram은 pretrained vocoder에 들어가 raw waveform으로 변환되어 emotional voice conversion process가 완료됩니다.
Style Autoencoder
feature extractor는 speech의 content와 style 정보를 포함하는 representation을 생성합니다. context의 경우, context는 linguistic information을 나타내며, style은 emotional expression과 speaker-specific characteristic을 나타냅니다. style을 modeling하기 위해, 저자들은 speaker style과 emotional style을 분리하였습니다. style autoencoder는 input feature에서 source emotional style을 분리하고 target emotional style을 적용하도로 design 되었습니다. 구조는 위와 같으며, de-stylize transformer and stylize transformer로 구성됩니다.
Layer Normalization (LN)을 각 transformer에서 이용합니다.
LN(z)=z−μσ
식으로 나타내면 위와 같습니다. z는 input vector를 나타내고 μ는 평균, σ는 표준편차를 나타냅니다. LN은 각 layer의 input이 일관된 분포를 가지가 만들어주어 학습의 안정성과 효율성을 보장해 줍니다.
- De-stylize Transformer
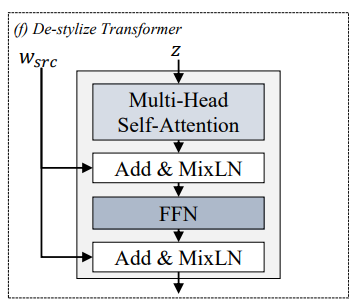
input feature에서 source emotional style을 제거하여 content 정보만 남깁니다. mix-style layer normalization (MixLN)을 이용합니다. 이는 feature와 source style 사이 연관성을 방해하기 위해, shuffled style vector와 original style vector를 혼합합니다. 식으로 나타내면 다음과 같습니다.
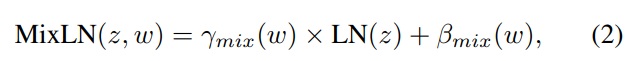
γmix(w)=λγ(w)+(1−λ)γ(˜w),βmix(w)=λβ(w)+(1−λ)β(˜w) 입니다. w는 original style vector이고 ˜w는 shuffled style vector입니다. λ는 beta distribution Beta(α,α)에서 sample 된 parameter입니다. 이를 통해 model이 style-specific feature를 encoding 하는 것을 막아주며, style-independent content를 분리하는데 도움을 줍니다.
- Stylize Transformer
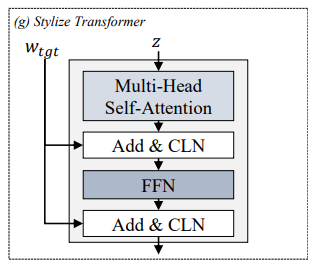
target emotional style을 content feature에 적용하는 역할을 수행합니다. conditional layer normalization (CLN)을 사용하는데, target style vector w 기반 normalized input을 사용합니다. CLN은 다음 식으로 정의됩니다.
CLN(z,w)=γ(w)×LN(z)+β(w)
위 식에서 γ(w),β(w)는 style vector w에서 얻어진 adaptive parameter입니다. CLN은 model이 desired emotional style을 content feature로 통합하도록 만들어줍니다.
style autoencoder는 N개 de-stylize transformer와 N개 stylize transformer로 구성됩니다. source style vector wsrc는 speaker vector ssrc, emotion vector esrc을 결합하여 만들고 target style vector wtgt은 ssrc와 desired emotion vector etgt을 결합하여 만듭니다.
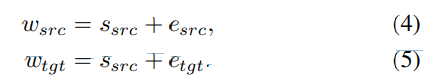
speaker vector s⋆와 emotion vector e⋆는 embedding look-up table에서 얻어집니다. de-stylize transformer는 wsrc을 이용해 input feature에서 source emotional style을 분리합니다. style transformer는 wtgt을 이용해 target emotion style을 feature로 encode 합니다. 이러한 구조는 model이 seq2seq structure에 의존하지 않고 효과적으로 emotional style을 adapt 할 수 있도록 만들어주며, parallel processing과 flexible duration modeling이 가능하게 만들어줍니다.
Unit Aligner
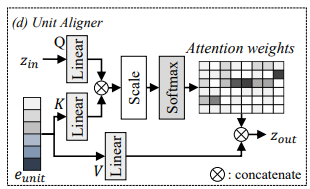
unit aligner는 input speech의 semantic context를 modeling 하여 unit sequence를 예측합니다. 위 그림처럼 unit aligner는 cross attention mechanism을 활용하여 attention weight를 만들어 unit prediction을 guide 합니다.
style autoencoder의 output을 cross-attention의 query (Q)로 사용하고 learnable embedding eunit을 key (K)와 value (V)로 적용합니다. attention weights Aunit은 다음과 같이 구해집니다.
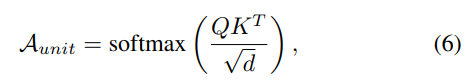
위 식에서 d는 Q,K의 차원을 나타냅니다. 그다음 weight Aunit과 value matrix V를 곱해 attention output zattn을 구합니다.
위 그림은 unit을 예측하기 위해 attention weight를 학습하는 과정과 예측된 unit의 duration을 modeling 하는 것을 보여줍니다. attention module이 semantic information을 학습할 수 있도록 additional loss term을 사용하였습니다. 이는 attention weight Aunit과 target unit sequence y를 align 함으로써 direct classification task를 수행하도록 만듭니다.
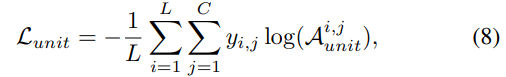
L은 unit sequence length를 나타내고 C는 unit class 수를 나타냅니다. Ai,junit는 u번째 element의 j class에 대한 예측된 확률 값을 나타냅니다. yi,j는 u번째 unit의 j class에 대한 one-hot encoded class label을 나타냅니다. 저자들은 HuBERT unit을 target unit으로 사용했습니다. 이를 통해 input speech의 context보단 target style과 일치하는 context를 반영할 수 있게 됩니다. emotional voice conversion 과정에서 style autoencoder는 input feature에서 source emotion을 제거한 후 target emotion을 적용합니다. unit aligner는 이를 받아 그에 맞는 unit sequence를 예측합니다. 이러한 구조는 model이 context를 효율적으로 변환할 수 있도록 만들어줍니다. seq2seq structure에 의존하지 않고 parallel processing도 가능하게 만들어 줍니다.
Duration Modeling
unit aligner가 unit sequence를 예측하고 난 후, duration modeling component가 각 unit의 duration을 결정합니다. 이때 동일한 unit이 연속적으로 등장하는 횟수를 기반으로 예측을 진행합니다. 이는 model이 생성한 speech length를 target emotional style에 맞춰 조정할 수 있도록 만들어 줍니다. unit sequence ˆy는 각 frame마다 가장 높은 확률 값을 가진 unit에 의해 결정됩니다.
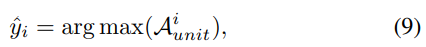
ˆyi는 u번째 predicted unit을 나타내고 Aiunit는 i번째 frame의 attention weight를 나타냅니다. 연속적으로 같은 unit이 반복되는 경우, 중복 제거 연산을 적용하여 각 unit과 duration을 계산합니다.
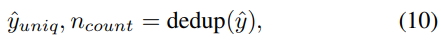
ˆyuniq는 unique unit sequence를 나타내고 ncount는 각 unit이 연속적으로 등장하는 횟수를 나타냅니다. 예를 들어 inptu sequence ˆy=[4,4,2,2,2,2,1,1]이라면, 중복 제거 연산 결과는 ˆyuniq=[4,2,1],ncount=[2,4,2]가 됩니다. 이는 unit 4는 2번 등장하고, 그 뒤에 2가 4번 등장하고 뒤에 1이 1번 등장한다는 것을 의미합니다.
duration predictor는 ncount을 target duration으로 사용하여 학습됩니다. predictor는 unit aligner가 생성한 unit-level representation을 기반으로 연속적인 unit 수를 추정합니다.
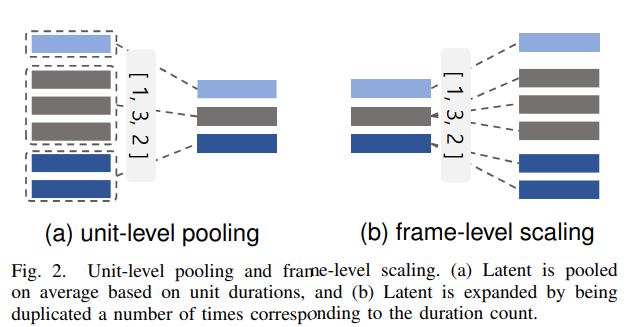
위 그림의 (a)가 unit-level pooling을 나타냅니다. unit aligner의 output zattn은 unit의 durataion을 기반으로 average 되고 unit level에 맞춰 sequence length를 downsampling 합니다. 이를 통해 unit-level pooling이 수행됩니다.
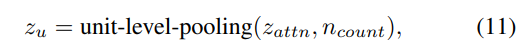
이렇게 unit level representation zu를 생성합니다. 예를 들어 zattn=[0.2,0.2,0.1,0.4,0.5,0.2,0.3,0.5],ncount=[2,4,2]가 주어진다면, unit-level pooling의 결과는 zu=[0.2,0.3,0.4]가 됩니다.
Hierarchical Stylize Encoder
계층적 stylize encoder는 2가지 level인 unit level과 frame level에서 동작합니다. 그래서 unit-level stylize transformer (UST)와 frame-level stylize transformer (FST)로 구성됩니다. UST는 zu를 zus로 처리하며(zus=UST(zu,wtgt)), unit-specific feature에 focus를 맞춥니다. 이 refined variable zu는 length regulator LR을 이용해 frame level로 scaling 됩니다. 위 그림의 (b)와 같습니다.
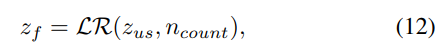
zf는 frame level의 latent variable을 나타냅니다. 예를 들어 zus=[0.1,0.2,0.5],ncount=[2,5,1]인 경우, zf=[0.1,0.1,0.2,0.2,0.2,0.2,0.2,0.5]가 됩니다. FST는 frame-level feature zf를 zfs로 refine 하며, zfs=FST(zf,wtgt)입니다. 이 final output zfs는 Mel-spectrogram generator의 input으로 사용됩니다.
duration predictor는 zus,wtgt를 input으로 받아 unit-level duration ncount를 예측하도록 학습됩니다. emotion-based duration dynamic의 경우, flow-based stochastic duration predictor를 사용하여 duration uncertainty을 추가합니다. duration predictor는 Ldur을 이용해 학습됩니다.
Diffusion-Based Mel-Spectrogram Generator
저자들은 stochastic differential equation (SDE) 기반 diffusion framework를 이용해 감정을 표현하는 high-quality speech를 생성합니다. diffusion-based model은 forward process에서 Mel-spectrogram을 Gaussian noise로 점진적으로 변환하며, reverse process에서 noise로부터 sample을 생성합니다. 저자들은 prior distribution으로 standard normal distribution을 선택했습니다. model은 groound truth noise와 estimated noise 사이 MSE loss Ldiff를 minimize 하도록 학습됩니다. score estimation의 경우, 저자들의 model은 linear attention을 사용하는 U-net architecture 기반 network sθ를 사용하였습니다.
Training Objective
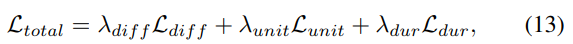
최종적으로 model은 위 loss를 이용해 학습됩니다. λdiff=1.0,λunit=0.1,λdur=0.1로 설정했습니다.
Emotion Voice Conversion Process
input speech의 emotion을 target emotion으로 변환하는 과정은 다음과 같습니다.
- feature extractor를 이용해 input waveform을 input feature로 변환
- style autoencoder를 이용해 feature는 source style vector로부터 de-stylize 되고 target style vector로 stylize 됩니다. source emotion vector와 speaker vector를 통해 source style vector를 얻습니다. target style vector는 target emotion vector와 speaker vector를 통해 얻습니다. source style은 style autoencoder의 MixLN에 의해 분리되며 target style은 CLN을 통해 적용됩니다.
- target style의 Unit-level feature는 unit alginer를 통해 구해집니다.
- hierarchical stylize encoder는 target style을 unit-level과 frame-level의 feature로 adapt 합니다.
- diffusion-based generator는 feature, target style vector를 condition으로 하여 Mel-spectrogram을 생성합니다.
- pre-trained vocoder에 넣어 waveform을 합성합니다.
Experiments
저자들은 ESD dataset을 사용하였습니다. 이 중 각 화자의 각 감정마다 20개 sample을 validation set으로 사용하였습니다. 그리고 각 화자의 각 감정마다 30개 sample을 test set으로 사용하였습니다. neutral에서 다른 감정으로의 변환뿐만 아니라, 가능한 모든 감정 변환에 대한 실험을 진행하였습니다. subjective evaluation의 경우, 5개의 각 감정에서 random으로 10개 sentence를 선택하여 사용하였습니다. 각 sentence들은 4가지 다른 감정으로 변환하는 데 사용하여 총 200개 sample을 생성하였습니다. objective evaluation의 경우, 각각의 1500개 test sample을 다른 4가지 감정으로 변환하여 총 6000개 sample을 생성하였습니다. 이렇게 모든 감정 변환에 대한 model의 성능을 자세히 평가하였습니다.
Evaluation
- Subjective Metrics
naturalness에 대한 MOS (nMOS), speaker similarity에 대한 MOS (sMOS), emotion mean opinion classification (eMOC)을 진행하였습니다.
- Objective Metrics
predicted mean opinion score, phoneme error rate (PER), character error rate (CER), word error rate (WER), emotion classification accuracy (ECA), speaker embedding cosine similarity (SECS)를 수행했습니다. wav2vec2.0-based phoneme recognition model로 PER을 측정하였습니다. CER, WER은 Whisper model을 이용해 평가하였습니다. SECS의 경우, 저자들은 Resemblyzer를 이용해 target & generated audio에 대한 speaker embedding을 추출했습니다. 그다음 cosine similarity를 구했습니다. pre-trained speech emotion recognition model을 이용해 generatd speech의 emotion을 평가하였습니다. SER model로 emotion2vec+base 를 사용하였습니다. 이는 9가지 감정에 대해 pre-train 된 model이고, 이 중 5가지 감정을 이용해 ESD에 대한 평가를 진행했습니다. 저자들은 emotion embedding cosine similarity (EECS)을 이용해 합성된 speech의 감정을 평가했습니다. 합성된 audio의 emotion embedding과 target emotion을 나타내는 임의의 reference audio의 emotion embedding 사이 cosine similarity를 구해 EECS를 계산했습니다. emotion embedding은 emotion2vec을 이용해 구했습니다. 이는 speaker independent 한 감정 정보를 encode합니다.
위 그림과 같이 speaker independent한 감정 정보를 encode 하는 것을 볼 수 있습니다. 그리고 pitch와 energy에 대한 평가를 위한 root mean square error (RMSE), prosody를 평가하기 위한 difference of duration (DDUR)을 측정하였습니다. parselmouth를 이용해 pitch를 추출하고 L2-norm을 적용해 energy를 추출했습니다.
Result
Comparison of evaluation results for baseline models
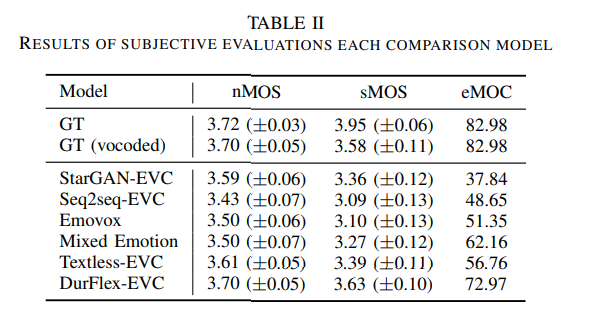
제안한 model의 성능을 평가하기 위해, objective & subjective evaluation을 진행했습니다. subjective evaluation result는 위와 같습니다. 저자들이 제안한 model이 가장 좋은 성능을 보이는 것을 볼 수 있습니다.
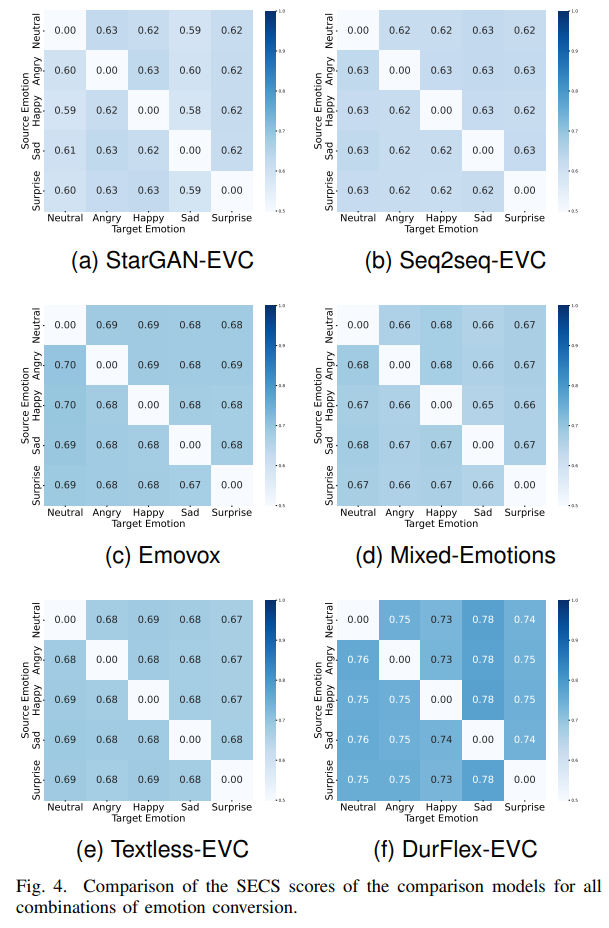
위 그림은 모든 emotion conversion에 대한 SECS를 보여줍니다. 이를 통해 저자들의 model이 다른 model에 비해 더 robust 한 speaker similarity를 보여줍니다.
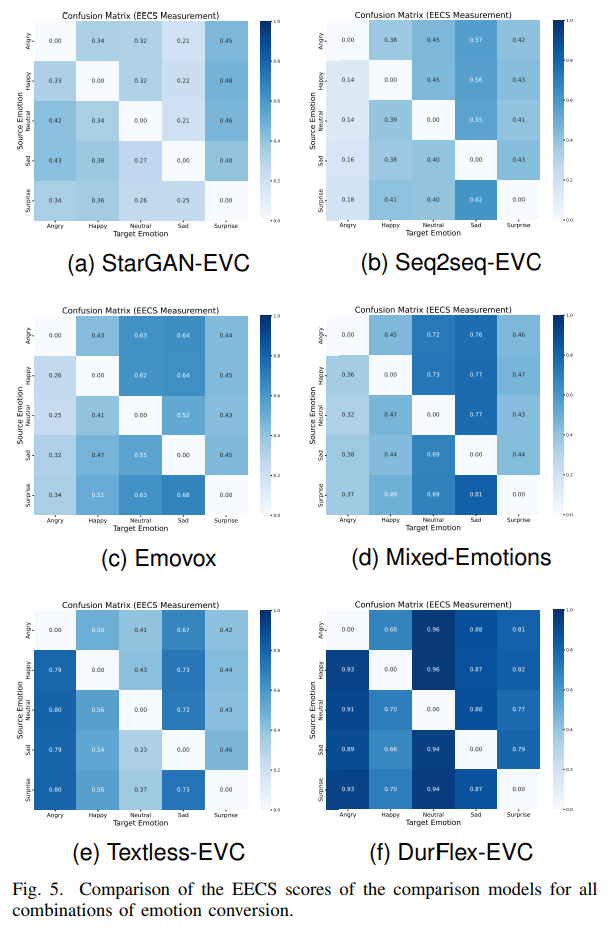
위 그림은 EECS를 보여줍니다. 이를 통해 저자들의 model이 더 높은 emotional similarity를 보여주는 것을 알 수 있습니다.
저자들은 각 model의 연산 효율성을 평가하기 위해, RTF를 사용하였습니다. Seq2Seq-EVC, Emovox, Mixed Emotion, Textless-EVC와 같은 autoregressive model은 StarGAN-EVC와 같은 parallel generation model보다 더 느린 inference speed를 보여줍니다. DurFlex-EVC는 diffusion-based model이며, sampling time step에 따라 RTF가 달라집니다. 4 time step의 경우, DurFlex-EVC는 RTF가 0.1334입니다. 이는 autoregressive model보다 훨씬 빠른 속도입니다. 그리고 autoregressive model보다 더 좋은 performance를 달성했습니다. 하지만 100 time step을 사용한 경우, DurFlex-EVC가 더 좋은 performance를 보여주지만 RTF가 1.92000이 되며, diffusion 과정의 연산량이 늘어나 느려집니다.
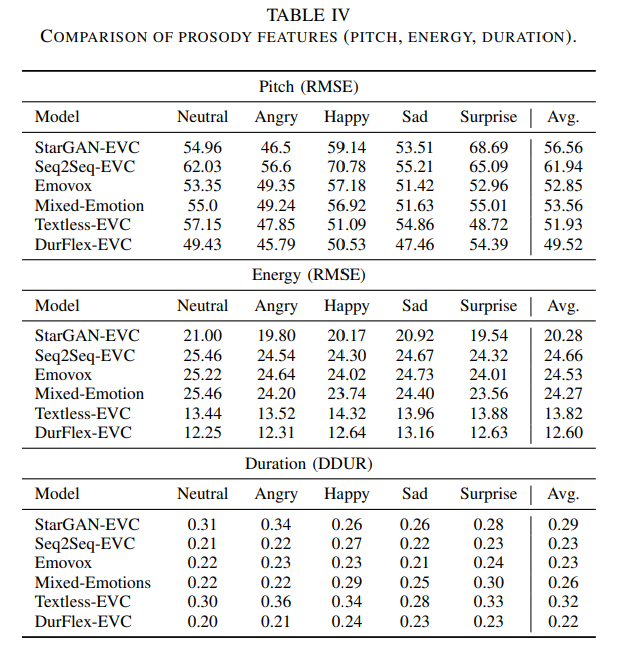
prosody에 대한 실험 결과는 위와 같습니다. 저자들의 model이 다른 model들의 prosody evaluation보다 더 높은 점수를 달성했습니다.
Unseen Speaker Emotion Conversion
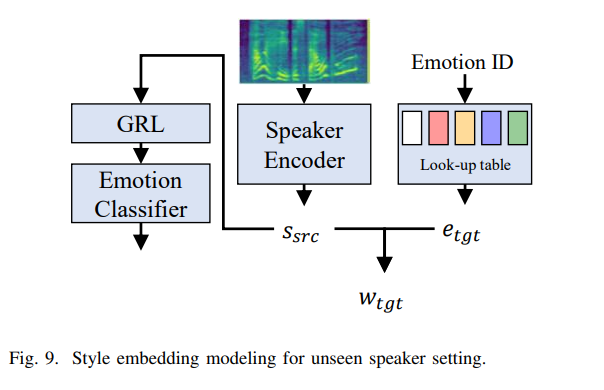
저자들은 unseen speaker scenario에서도 실험을 진행했습니다. 이를 위해, 저자들은 model이 speaker ID를 사용하는 대신 reference audio에서 speaker embedding을 encode 하여 speaker 정보를 제공하도록 수정하였습니니다. Meta-StyleSpeech의 style encoder 구조를 speaker encoder로 사용하였습니다. gradient reversal layer (GRL)과 linear layer를 사용하여 speaker encoder가 감정 정보를 학습하지 않도록 만들었습니다. linear layer는 emotion classification task를 수행하고, 감정 정보를 반대로 학습시켜 speaker encoder가 감정과 무관한 정보만 학습하게 만들었습니다. 이렇게 위 구조로 style embedding을 model 하였습니다. 저자들은 ESD dataset으로 model을 학습시켰습니다. unseeen speaker test를 위해, 저자들은 VCTK datset에서 random 하게 각 화자의 5개 sentence를 선택하였습니다. neutral emotion state에서 다른 emotion state로 변환하는 test를 진행했습니다.
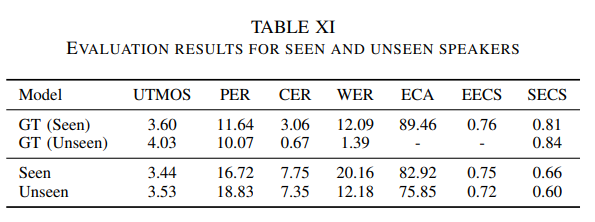
실험 결과는 위와 같습니다. original version보다 저자들이 새로 수정한 model이 UTMOS, CER, WER에 있어서는 더 나은 성능을 보였지만, ECA, EECS, SECS에서는 더 좋지 않은 모습을 보였습니다. 이는 reference audio에서 얻은 추가적인 encoded information이 합성 quality와 발음에 있어 긍정적인 영향을 준다는 것을 의미합니다. 하지만 style disentanglement의 부족으로 인해, speaker-related metric에 있어서는 성능 저하가 발생했습니다. unseen speaker에 대한 결과를 통해 quality 손실 없이도 unseen speaker에 대한 변환을 수행할 수 있음을 확인하였습니다.
Discussion
emotional pronunciation을 modeling 하는 framework를 제안합니다. unit level에서 SSl feature를 변환하는 것에 초점을 맞추고 있습니다. 저자들의 method는 predicted unit에 의존하지 않고, cross-attention의 output을 model의 input으로 사용합니다. model은 Mel-spectrogram을 생성하며, 이는 waveform을 바로 생성하는 것보다 더 효율적입니다.



