https://arxiv.org/abs/2404.01805
Improved Text Emotion Prediction Using Combined Valence and Arousal Ordinal Classification
Emotion detection in textual data has received growing interest in recent years, as it is pivotal for developing empathetic human-computer interaction systems. This paper introduces a method for categorizing emotions from text, which acknowledges and diffe
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
textual data에서 emotion detection을 하는 것은 최근 몇 년 동안 주목받고 있으며 empathetic human-computer interaction system에서 중요한 역할을 합니다. 이 논문에서 text에서 emotion을 categorize 하는 method를 제안합니다. 다양한 감정 간의 유사성과 차이를 인식하고 구별하는 방식을 사용합니다. 먼저 transformer-based model을 standard emotion classification 할 수 있도록 학습하여 SOTA 성능을 달성합니다. 저자들은 모든 misclassification이 동일한 중요도를 가지는 것이 아니며, 감정 클래스 간에는 지각적인 유사성이 존재한다고 주장합니다. 그래서 저자들은 traditional classification model을 ordinal classification model로 변환함으로써 emotion label problem을 재정의합니다. 마지막으로 valence and arousal two-dimension space에서 ordinal classification을 수행하는 새로운 method를 제안합니다. 저자들이 제안한 method는 높은 emotion prediction 정확도를 보일 뿐만 아니라 misclassification 시 발생하는 error의 정도를 크게 줄였습니다.
Introduction
traditional classficiation model은 감정을 discrete class로 간주하며, binary 또는 multiclass output을 생성합니다. 하지만 인간의 감정 spectrum을 완전히 capture할 수 없습니다. 이러한 model은 class 별 유사성이 고려되지 않게 됩니다. 예를 들어 슬픔이 기쁨으로 잘못 분류된 것은 슬픔이 우울로 잘못 분류되는 것과 동일한 오류로 간주하게 됩니다. 하지만 TTS와 같은 downstream application에서는 이러한 error가 심각한 왜곡을 초래할 수 있으며, 슬픈 내용을 들뜬 목소리로 발화하는 부자연스러운 결과를 초래할 수 있게 됩니다.
Contribution
이 논문에서 저자들은 Russell의 circumplex model에 따라 감정 class 간의 지각적 거리를 고려하면, SOTA 성능을 달성하는 emotion classification method를 제안합니다. 먼저 RoBERTa-CNN baseline model을 이용해 transformer-based model과 비슷한 성능을 달성합니다. 그다음 model을 ordinal classification으로 확장하여 discrete emotion을 valence value에 따라 순차적으로 배열합니다. 마지막으로 valence and aoursal scale의 two-dimensional emotion space에서 ordinal classification을 수행합니다. 저자들의 method가 높은 정확도뿐만 아니라 더 의미 있는 misclassification을 수행할 수 있음을 증명하였습니다.
Data
저자들은 ISEAR, Wassa-21, GoEmotions dataset을 사용하였습니다. ISEAR은 7666개 sentence로 이루어져 있으며 7가지 감정 label (joy, anger, sadness, shame, guilt, surprise, fear)이 존재합니다. Wassa-21는 뉴스 기사에 대한 반응으로 작성자가 자신의 공감과 고통을 표현한 essay로 구성되어 있습니다. GoEmotions는 58k개의 Reddit 댓글이 포함되어 있습니다. human annotation으로 27개 감정 또는 neutral로 mapping 되어 있습니다.
Baseline Model
저자들은 RoBERTa-CNN model을 개발했으며, standard baseline보다 더 뛰어난 emotion classification 성능을 보였습니다. text classification model은 일반적으로 2가지 part로 구성됩니다. transformer-based model과 classification head 입니다. 기존 연구에서는 text classification task에서 다양한 trasnformer-based model을 비교했으며, RoBERTa가 더 큰 train corpus를 활용한 BERT의 향상된 version으로 우수한 성능을 보인다는 것이 입증되었습니다. 저자들도 BERT, RoBERTa, DistilBERT, XLNet을 활용한 초기 실험을 진행했었으며, 확인하였습니다.
저자들은 classification head에 대한 추가적인 실험도 진행하였습니다. 저자들의 classification head는 two convolution neural network layers with kernel sizes [6, 4] and [1024, 2048] number of filter로 구성됩니다. encoded information은 mean pooling으로 compress된 후 3-layer feedforward neural network (FFNN)와 softmax를 통해 최종 output이 생성됩니다.
SOTA approach를 사용하더라도 model은 오류가 발생할 수 있습니다. 이를 보완하기 위해, 저자들은 ordinal classification 방식을 도입하여 emotion recognition task에서의 misclassification을 줄였습니다.
Ordinal Classification

저자들은 standard cross-entropy loss를 사용해 model을 fine-tune 하였습니다. cross-entropy loss의 inherent limitation은 misclassification을 단순한 nominal error로 처리한다는 점입니다. 즉, positive를 very positive로 잘못 분류한 것이 very negative로 잘못 분류한 것이랑 동일하게 간주한다는 뜻입니다. 이를 해결하기 위해, 저자들은 감정을 valence에 따라 ordinal 방식으로 arrange 하였습니다.
label 끼리의 gap을 줄이기 위해, 저자들은 discrete one-hot representation을 ordinal representation으로 대체하였습니다. model이 정확한 분류를 수행하는 것 뿐만 아니라, prediction과 target 간의 차이를 최소화하기 위해 MSE loss를 사용하여 학습을 진행하였습니다. 이를 통해 model이 target과 prediction 사이 distance를 줄이는 데 집중할 수 있었습니다.
ordinal classificiation을 통해 저자들의 baseline model이 3개 dataset 모두에서 경쟁력 있는 성능을 보였으며, 모든 경우에서 더 빠르게 수렴하였습니다.
ordinal classification은 예측값과 실제 valence value 사이의 거리가 클수록 더 큰 penalty를 부여하기 때문에, model이 severe mistake를 줄이도록 만들어 줍니다. base model과 accuracy, F1-score가 비슷하더라도, confusion matric에서 ordinal의 효과를 확인할 수 있었습니다. baseline model이 severe misclassification을 더 자주 발생시키는 것을 볼 수 있습니다.
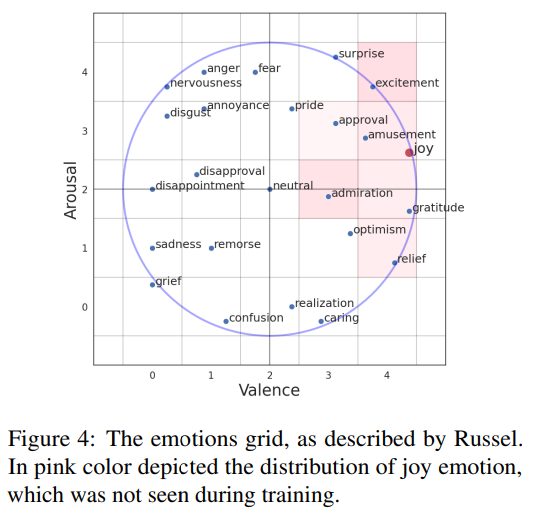
2D Ordinal Classification
단순히 valence levle로 감정을 표현하는 방식에는 한계가 존재합니다. 왜냐하면 특정 감정은 비슷한 valence value를 공유하기 때문입니다. 저자들의 model의 expressiveness를 향상시키기 위해, 저자들은 arousal scale을 도입하였습니다. 2D ordinal classification을 적용하기 위해, 저자들은 emotion space를 5x5 grid space로 나눴습니다. 각 cell은 각 감정을 나타냅니다. 저자들은 valence classifier는 유지한 채로 arousal level을 예측하는 classifier head를 추가하였습니다. 저자들의 model의 두 head는 동시에 학습됩니다. 최종적으로 predicted valence and arousal value가 emotion grid 내 좌표로 활용됩니다.
Conclusion
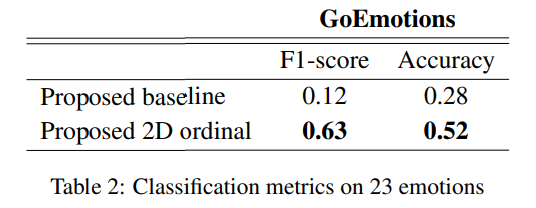
위 표를 보면 알 수 있듯이, 23개 감정에 대한 classification 성능이 2D ordinal에서 더 좋아지는 것을 볼 수 있습니다.
이 논문에서 저자들은 textual data에서 emotion을 예측하는 새로운 approach를 제안합니다. 감정 간의 미묘한 similarity 차이를 고려하여, 기존의 단순한 감정 분류 방식의 한계를 극복하였습니다. RoBERTa-CNN model을 baseline으로 사용했습니다. 그다음 감정을 valence level로 나타내여 traditional classification을 ordinal classification으로 전환하였습니다. 또한 arousal value까지 추가한 2-dim emotional space를 구축하고, 해당 space에서의 ordinal classification을 제안하였습니다. 저자들이 제안한 method가 더 의미 있는 예측을 수행하여 model 성능을 향상시켰습니다.



