https://arxiv.org/abs/2407.12229
Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-to-Speech
People change their tones of voice, often accompanied by nonverbal vocalizations (NVs) such as laughter and cries, to convey rich emotions. However, most text-to-speech (TTS) systems lack the capability to generate speech with rich emotions, including NVs.
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
사람들은 목소리 톤을 변환하며, 종종 웃거나 우는 것처럼 non-verbal vocalization (NVs)을 동반하여 풍부한 감정을 표현합니다. 하지만 대부분의 TTS system은 NVs를 포함한 풍부한 감정 표현을 가지고 있는 speech를 생성하는 능력은 부족합니다. 이 논문은 각 화자의 목소리로 NVs를 포함한 풍부한 감정적 speech를 생성할 수 있는 emotion-controllable zero-shot TTS인 EmoCtrl-TTS를 제안합니다. EmoCtrl-TTS는 arousal and valence value 뿐만 아니라 laughter embedding을 사용하여 flow-matching-based zero-shot TTS에 condition을 제공합니다. high-quality emotion speech generation을 위해, EmoCtrl-TTS는 27,000시간 이상의 expressive data를 가지고 학습했습니다. 종합적인 실험을 통해 EmoCtrl-TTS가 감정 및 화자 특성을 유지하면서도, speech-to-speech translation scenario에서 감정을 효과적으로 모방할 수 있음을 입증하였습니다. 또한 EmoCtrl-TTS는 강하게 감정을 표현하도록 감정을 변화시킬 수 있고 다양한 NVs를 생성할 수 있습니다.
Introduction
사람들은 목소리 톤을 바꾸면서 다양한 범위의 감정을 표현하며, 종종 웃거나 우는 것과 같은 nonverbal vocalization (NVs)를 포함하여 표현하기도 합니다. 최근 emotional TTS system들은 상당한 발전이 있었지만, 여전히 세밀한 감정 control (e.g. 하나의 발화에서 감정 상태가 변화)을 수행하여 emotional speech를 생성하는 능력은 부족합니다. 뿐만 아니라 다양한 type의 NVs를 표현하는 능력도 부족합니다. 추가적으로 emotional TTS system들은 제한된 수의 speaker에 대해서만 학습되며, 단일 화자에 대해서도 학습되기도 합니다. 이러한 TTS model들은 새로운 화자의 emotional speech를 생성할 수 있는 능력이 부족합니다. 하지만 speech-to-speech translation과 같은 application에서는 source audio의 화자와 감정 특성을 유지하는 것이 중요합니다.
이 논문에서 저자들은 새로운 화자에 대해서도 NVs를 동반하는 highly emotional speech를 생성할 수 있는 emotional-controllable zero-shot TS system인 EmoCtrl-TTS를 제안합니다. EmoCtrl-TTS는 audio sample (audio prompt)의 목소리 특징과 감정 표현을 모방해 speech를 생성합니다. EmoCtrl-TTS는 flow-matching-based zero-shot TTS를 기반으로 하며 time-varying emotion characteristic을 모방하기 위해 valence and arousal value를 사용합니다. 그리고 웃음 외에도 다른 NVs를 생성할 때 효과적인 laughter embedding을 사용합니다. 그리고 신중하게 data mining 하여 27k 시간의 highly expressive real-world data를 구축하였고, EmoCtrl-TTS의 robustness를 크게 향상시켰습니다. 종합적인 평가를 통해 EmoCtrl-TTS가 speech-to-speech translation을 수행할 때 여러 언어에서도 audio prompt의 감정을 reproduce 할 수 있음을 보였습니다. 또한 EmoCtrl-TTS가 감정 변화를 capture 할 수 있고 강한 감정을 표현할 수 있으며 다양한 type의 NVs를 생성할 수 있음을 보였습니다. 저자들의 contribution은 다음과 같이 정리할 수 있습니다. 1) flwo-matching-based zero-shot TTS와 NV & emotion embedding을 통합하였습니다. 2) 저자들은 종합적인 실험을 통해 emotion-controllable zero-shot TTS를 평가하였으며, 뛰어난 성능을 입증하였습니다.
Related Work
Controlling emotion in TTS

emotional TTS는 많은 발전을 이루고 있습니다. 위 표는 다양한 TTS system을 보여주고 있습니다.
하나의 utterance에서 세밀한 감정 특성을 control 할 수 있는지 여부가 첫번째 중요한 요소입니다. 예를 들어 speech-to-speech translation에서는 번역된 음성에서도 감정 변화의 뉘앙스를 그대로 유지하는 것이 중요합니다. 하지만 대부분의 이전 연구들은 utterance-level emotion을 control 하는 것을 목표로 하며, 시간에 따른 감정 변화를 다루는 연구는 거의 없었습니다. MsEmoTTS는 음절 단위 감정 강도를 예측하는 local emotional strength predictor를 사용하여 생성된 음성의 감정 강도를 조절하는 방식을 사용하였습니다. ELaTE는 flow-matching-based zero-shot TTS에 laughter representation을 condition으로 적용하여 웃음을 생성에 있어 뛰어난 controllability를 보였습니다. 하지만 여전히 감정 상태를 완전히 제어할 수 있는 기능은 부족합니다.
두 번째로 중요한 것은 NVs를 생성하는 능력입니다. 대부분의 emotional TTS 연구들은 NVs를 생성하지 못합니다. ELaTE는 자연스러운 웃음을 생성할 수 있지만 울음과 같은 다른 NVs에 대해서는 연구하지 않았습니다.
세 번째 point는 학습 data의 양입니다. supervision이 존재하는 high-quality emotional training data를 개발하는 것이 어렵기 때문에, 대부분의 연구들은 100시간보다 적은 양의 학습 데이터를 사용했습니다. ELaTE는 웃음이 포함된 460시간의 음성을 사용했지만, data 양은 여전히 500시간 미만으로 제한되어 있습니다. 저자들이 알기론, large-scale emotional data를 활용하여 emotional TTS training의 효과를 연구하는 첫 시도입니다.
네 번째 point는 화자 수입니다. 대부분의 emotional TTS system은 100명보다 적은 수의 화자 목소리를 이용합니다. 저자들의 data는 익명화되어 정확한 화자 수를 공개할 순 없지만, 대규모 데이터를 활용함으로써 다양한 speaker variation이 가능할 것으로 예상됩니다. 이를 통해 zero-shot TTS 성능이 향상될 것입니다.
마지막으로 emotional training data가 staged data인지 real data에 해당되는지에 대한 여부입니다. 대부분의 연구들은 학습 과정에서 staged data를 활용하였으며, speech 다양성에 한계가 발생하게 됩니다. 예를 들어 speech-to-speech translation scenario에서 source language speaker가 전문적인 배우가 아닐 가능성이 높으며, 연출된 감정과 실제 감정의 차이가 존재할 수 있습니다. 대규모 학습 data를 사용하여 저자들은 zero-shot TTS scenario에서 감정 전달 성능을 극대화하였습니다.
ELaTE
ELaTE는 세밀한 controllability를 가지고 자연스러운 웃음이 존재하는 speech를 생성할 수 있습니다. laughter detector에서 얻어낸 frame-level laughter representation을 flow-matching-based zero-shot TTS의 contion으로 사용하여 기존 model보다 더 높은 quality이면서 제어 가능한 웃음 음성을 생성할 수 있습니다. 하지만 ELaTE는 laughing speech에 대해서는 실험을 진행하였으며, 다른 NVs에 대해서는 조사하지 않았습니다. 저자들은 ELaTE가 audio prompt에 울음과 같은 다른 NVs가 존재하지만 laughing speech를 생성하는 것을 확인하였습니다. 저자들은 더 다양한 NVs를 생성하고 감정을 더욱 잘 제어할 수 있는 것을 목표로 ELaTE를 확장하였습니다.
EmoCtrl-TTS
Overview
- Model Training
위 그림의 (a)는 EmoCtrl-TTS의 학습 과정을 보여줍니다. training audio sample s와 transcription y가 주어졌을 때, mel-filterbank feature ˆs∈RF×T을 구합니다. 여기서 F는 feature dimension을 나타내고 T는 sequence length를 나타냅니다. 추가적으로 frame-wise phoneme embedding a∈RDphn×T을 얻기 위해 force alignment와 phoneme embedding layer를 사용합니다. 여기서 Dphn은 phoneme embedding dimension을 나타냅니다. phoneme embedding layer는 audio model의 일부이며, 동시에 학습됩니다. 그리고 NV h∈RDNV×T과 emotion e∈RDemo×T을 나타내는 frame-wise embedding을 추출합니다. DNV는 NV embedding dimension을 나타내고 Demo는 emotion embedding의 dimension을 나타냅니다. embedding h는 pre-trained NV detector에서 추출되고 e는 pre-trained emotion detector를 이용해 추출됩니다.
저자들은 speech infilling task를 이용해 audio model을 학습시킵니다.
- Inference
위 그림의 (b)는 EmoCtrl-TTS의 inference 과정을 보여줍니다. inference할 때, model은 text prompt ytext, speaker prompt audio sspk, NV prompt audio sNV, emotion prompt audio semo를 input으로 받습니다. text prompt는 생성된 speech의 content를 나타냅니다. speaker, NV, emotion prompt는 생성된 speech의 speaker, NV, emotion 특성을 control 합니다. speech-to-speech translation scenario에서는 source audio sspk,sNV,semo와 text prompt ytext를 사용합니다. translated speech는 source speaker의 목소리 특성과 감정적 특성을 유지합니다.
speaker prompt sspk는 mel-filterbank feature ˆsspk로 변환됩니다. 그리고 speaker prompt sspk에 automatic speech recognition (ASR)과 phoneme embedding layer를 적용해 phoneme embedding aspk를 얻습니다. NV detector와 emotion detector에 speaker prompt sspk를 넣어 NV embedding hspk와 emotion embedding espk를 얻습니다.
text prompt ytext는 phoneme embedding layer의 output에 phone duration model을 적용해 text prompt embedding atext로 변환됩니다. NV detector와 emotion detector로부터 NV prompt embedding hNV와 emotion prompt embedding eemo을 추출합니다. hNV와 hemo의 길이가 atext의 길이와 다르다면, atext에 맞도록 linear interpolation을 수행합니다. flow-matching-based audio model을 이용해 mel-filterbank features ˜s를 생성합니다. 이 과정에선 학습된 분포 P(˜s|[aspk;atext],[hspk;hNV],[espk;eemo])를 사용하며, ;는 concatenate를 의미합니다. 생성된 ˜s를 vocoder에 넣어 최종적으로 speech signal을 생성합니다.
NV embeddings
다양한 NV의 특성을 나타낼 수 있는 적절한 embedding을 사용하는 것이 필수적입니다. ELaTE에서는 off-the-shelf laughter detection model을 사용해 embedding을 추출했었습니다. ELaTE는 이를 이용해 zero-shot TTS에서 laughter를 control 하였습니다. 이 논문에서는 laughter dectector-based embedding이 laughter 뿐만 아니라 광범위한 다른 NV type을 capture할 수 있다는 것을 발견하였습니다. 적절히 laughter-detector-based embedding을 사용하여 울음, 신음과 같은 다양한 NVs를 생성할 수 있습니다. 그러므로 이 논문에서는 laughter detection model에서 추출한 32차원 embedding을 NV embedding으로 사용합니다.
Emotion embeddings
감정은 2가지 방식으로 표현할 수 있습니다. 첫번째로, 감정은 행복과 슬픔과 같은 명확한 카테고리로 구분하는 방식입니다. 두 번째는 감정을 arousal, valence, dominance라는 value로 나타내는 것입니다. arousal은 감정의 세기 또는 activation 정도를 나타냅니다. valence는 감정이 얼마나 긍정적인지, 부정적인지 나타냅니다. dominance는 감정을 얼마나 통제하는지 나타냅니다.
emotion embedding은 중요한 역할을 수행합니다. 저자들은 사전 실험에서 8가지 감정 category를 사용했었습니다. 이때 각 감정 category들은 학습된 emedding을 통해 표현되고 espk로 사용하였습니다. 이때 TTS model이 효과적으로 감정적 speech를 생성하는데 어려움을 겪는다는 것을 발견했습니다. 그리고 저자들은 FACodec의 prosody encoder를 사용하였습니다. 하지만 prosody encoder의 output이 phonetic information을 포함하고 있으며, text prompt보다 emotion prompt의 content를 따라 speech를 합성하는 경향을 보였습니다.
그래서 저자들은 pre-trained arousal-valence-dominance extractor를 이용해 arousal valence value를 추출했습니다. 이 extractor는 wav2vec2 model을 기반으로 하며 MSP-PODCAST data로 fine-tune 되어 arousal, valence, dominance value를 예측합니다. chunk-wise arousal-valence value (Demo=2)는 window size = 0.5 sec, hop size = 0.25 sec로 설정한 sliding window를 통해 구해집니다. extractor가 0.0 ~ 1.0 사이 값을 추출하기 때문에, -0.5 ~ 0.5 사이 값을 갖도록 조절했습니다. linear interpolation을 통해 phoneme embedding의 길이에 맞춰 value를 조절했습니다. 이를 통해 발화 내에서 nuanced emotional variation을 더욱 잘 capture 하였습니다. 사전 실험에서 dominance value를 사용하면 audio quality 저하가 발생하는 것을 발견했으며, 본 연구에서는 사용하지 않았습니다.
Collection large-scale emotional data with pseudo-labeling
학습 data의 quantity와 quality는 중요한 요소입니다. 하지만 emotional speech를 녹음하거나 recording의 manual annotation을 기록하는 것은 cost가 많이 들며, 100시간 이상의 data size를 만드는데 어려움이 발생하게 됩니다.
저자들은 In-house Emotion Data (IH-EMO)라는 27k 시간 highly emotional data를 사용합니다. 이는 200k 시간의 in-house unlabeled 익명 English audio를 이용하여 구했습니다. data curation 과정은 다음과 같습니다. 먼저 emotion2vec model을 이용해 emotion confidence score를 얻습니다. predicted emotion이 {angry, disgusted, fearful, sad, surprise}이거나 {neutral, happy}이면서 confidence score가 1.0인 data들만 채택하였습니다. 그다음 DNSMOS을 수행해 OVLR score가 3.0보다 큰 sample들만 선택했습니다. 마지막으로 in-house speaker change dectetion model을 사용하여 speaker 변화가 detect 된 sample들은 제거했습니다. 결과적으로 27k 시간의 emotional audio가 수집되었습니다. 그다음 off-the-shelf speech recognition model을 이용해 transcription을 생성하였습니다.
Experiments
Data
저자들은 Libri-light, LAUGH, IH-EMO를 사용하였습니다. Libri-light를 이용해 NV and emotion embedding이 없는 audio model을 pre-train 하였습니다. LAUGH와 IH-EMO를 이용해 NV와 emotion embedding을 사용한 audio model을 fine-tune 하였습니다.
Evaluation metrics
저자들은 word error rate, Speaker SIM-o, AutoPCP, Emo SIM, Aro-Val SIM을 사용하였습니다. Speaker SIM-o는 generated audio와 audio prompt 사이 speaker similarity를 평가합니다. 이때 두 speaker embedding의 cosine similarity를 측정하여 구합니다. WavLM-large-based speaker verification model을 이용해 embedding을 구합니다. AutoPCP는 두 speech sample의 utterance-level prosody similarity를 평가합니다. Emo SIM은 emotion2vec model을 이용해 emotion embedding을 추출합니다. 이를 이용해 time-varying emotion state similarity를 평가합니다. Aro-Val SIM은 또 다른 time-varying emotion state를 평가하는 metric입니다. arousal-valence value를 이용합니다.
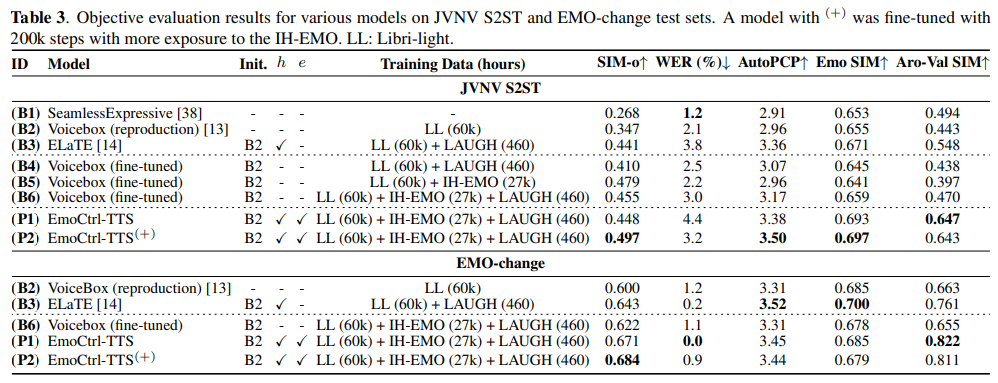
Results and discussion
위 표는 objective evaluation result를 보여줍니다. EmoCtrl-TTS은 baseline보다 AutoPCP, EmoSIM, Aro-Val SIM에서 뛰어난 모습을 보여줬습니다.
Conclusions
이 논문에서 저자들은 EmoCtrl-TTS라는 emotion-controllable zero-shot TTS model을 제안합니다. 이는 어떠한 화자든 상관 없이 NVs를 나타내는 highly emotional speech를 생성할 수 있습니다. EmoCtrl-TTS는 arousal and valence value 뿐만 아니라 laughter embedding을 이용해 NVs을 포함한 emotional speech의 time-varying characteristic을 control 할 수 있습니다. 실험을 통해 EmoCtrl-TTS가 source audio의 voice characteristic과 nuance를 유지하면서 NVs를 나타내는 emotional speech를 생성할 수 있음을 보였습니다.



