https://arxiv.org/html/2401.11017v1
Revealing Emotional Clusters in Speaker Embeddings: A Contrastive Learning Strategy for Speech Emotion Recognition
License: CC BY 4.0 arXiv:2401.11017v1 [eess.AS] 19 Jan 2024 \useunder Revealing Emotional Clusters in Speaker Embeddings: A Contrastive Learning Strategy for Speech Emotion Recognition Abstract Speaker embeddings carry valuable emotion-related information,
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
speaker embedding에는 valuable emotion-related information이 존재하며, 이 정보는 speech emotion recognition 성능을 향상시키기 위한 promising source로 사용될 수 있습니다. 특히 제한된 labeled data인 경우, 더욱 효과적일 수 있습니다. 일반적으로 emotion information이 speaker embedding에 간접적으로 embed 되어 있다고 여겨지며, 충분히 활용되고 있지 않습니다. 저자들의 연구는 emotion과 SOTA speaker embedding 사이 direct and useful link를 찾아냈습니다. 특히, intra-speaker cluster 형태로 감정 정보가 직접적으로 표현된다는 점을 발견했습니다. 세밀한 clustering 분석을 통해, 저자들은 speaker embedding에서 emotion information을 쉽게 추출할 수 있음을 입증하였습니다. 이 정보를 활용하기 위해, 저자들은 unlabeled data speech emotion recognition을 위한 새로운 contrastive pretraining method를 제안합니다. 저자들이 제안한 방식은 speaker embedding의 intra-speaker cluster 기반 positive and negative example을 sample 하는 방식을 사용합니다. 이를 통해 extensive emotion-unlabeled data에서 SER 성능을 크게 향상시킬 수 있습니다. 뿐만 아니라 multi-task pretraining setting에도 이를 통합할 수 있습니다.
Introduction
speec hemotion recognition은 감정 표현의 complexity와 subjective하다는 특성 때문에 어려운 task이며, labeled emotional data도 부족합니다. SER과 다르게 speaker verification은 충분한 양의 labeled data를 사용할 수 있습니다. speech에서 감정을 인지하는 것과 speaker를 verify 하는 task는 주요 목표가 다르지만, pitch, tone, phonation pattern과 같은 목소리의 기본 특성을 식별하는 것에 중점을 두는 것을 동일합니다. 결과적으로 robust 한 speaker verification technique은 speech emotion recognition system의 performance를 향상시킬 수 있는 promising tool로 여겨지고 있습니다.
speaker feature 안에 있는 감정 정보는 다양한 emotional speech task에서 연구되었습니다. 감정 상태가 일치하지 않는 상태에서는 speaker verification 정확도가 감소했으며, 이는 speaker feature가 emotion state에 민감하게 반응하는 것을 나타냅니다. 또 다른 연구에서는 autoencoder-based reconstruction analysis와 emotion classification을 통해 speaker embedding에 감정 관련 정보가 있다는것이 입증되었습니다. 최근 연구에서는 speaker verification에서 speech emotion recognition으로의 knowledge transfer를 진행하는 deep speaker embedding network도 등장하였습니다. 하지만 emotion information을 encoding 하는 데 있어 d-vector, ECAPA-TDNN과 같은 deep speaker embedding의 잠재력은 아직 충분히 연구되지 않았습니다. 이전 연구들은 감정 정보가 speaker embedding에 직접적으로 encode 되어있지 않다고 가정했으며, supervision이 필요하다고 가정했기 때문에 한계가 존재했습니다. 이 논문에서 저자들은 speaker embedding space에 emotion-related information이 direct 하게 존재하는지 아닌지 탐구하며 해당 information을 SER task에서 효과적으로 사용하는 방법에 대한 탐구를 목표로 합니다.
Wav2vec2.0과 같은 self-supervised speech model은 large unlabeled speech dataset을 이용하여 supervised SER framework의 성능을 향상시켰습니다. 하지만 이러한 pre-training objective는 SER을 위해 설계된 것이 아니며, 대부분은 audio-visual feature를 통합하는 것이 목표인 model들입니다. 그리고 SER에서 사용되는 pretraining task들은 frame-level task이지만, speech emotion은 일반적으로 utterance-level task입니다. 결과적으로 상당한 gap 차이가 발생하며, speech-related feature만 사용하여 SER에 명시적으로 맞춰진 utterance-level unsupervised pre-training strategy가 부족하고, 이 논문의 주요 contribution 중 하나입니다.
이 논문은 SOTA deep speaker emedding에 존재하는 감정 관련 정보의 direct accessibility를 탐구하는 첫 연구입니다. 저자들의 분석을 통해 emotional state를 반영하는 구분된 intra-speaker cluster를 발견했으며, speaker and emotion recogntion 사이 strong link가 있음을 시사합니다.이 정보를 사용하기 위해, 저자들은 large-scale, emotion-unlabeled data를 이용하는 새로운 pretraining strategy를 제안합니다. 이 방식은 emotion label 없이 speaker embedding cluster를 기반으로 positive-negative pair를 생성하여 contrastive learning을 수행합니다. 이 strategy는 pretraining의 주요 objective로 사용될 뿐만 아니라, 기존 pretraining training strategy에 추가하여 multi-task setting으로 사용할 수 있습니다. 저자들의 contribution은 다음과 같이 요약될 수 있습니다.
- speaker embedding에서 쉽게 활용 가능한 emotion information을 발견했습니다.
- emotion label 없이 SER을 수행할 수 있는 unique,utterance-level contrastive learning approach를 제안합니다.
- multi-task setting에서 pretraining task를 결합하는 것이 SER 성능을 향상시킨다는 것을 입증하였습니다.
- 저자들이 제안한 training strategy를 통해, wav2vec2.0의 emotion recognition 성능을 향상시켰습니다.
Revealing Emotion Clusters in Speaker Embeddings
speaker embedding space에서 emotion discrimination을 탐구하기 위해 speaker embedding에 cluster analysis를 수행했으며, embedding의 intra-speaker cluster와 emotion category 사이 direct link를 확립합니다. 이 connection은 다양한 SER application에서 상당한 potential를 가지고 있으며, 특히 대규모 unlabeled emotion data를 활용할 때 더욱 그렇습니다. 저자들의 분석은 voice characteristic을 capture 하기 위해 design된 speaker embedding은 서로 다른 감정 상태에 따른 화자의 목소리 변화에 sensitive 하다고 가정합니다. 이는 서로 다른 감정적 context에 맞춰 구분된 speaker pattern이 존재한다는 연구에서 영감을 받았습니다.
Dataset, speaker embeddings and evaluation metrics
저자들은 각 화자마다 최대 320개 utterance를 사용하여 length-normalized speaker embedding을 얻어 k-means clustering을 수행했습니다. 이때 neutral, happiness, sadness, anger라는 4가지 감정에 맞춰 고정된 수의 cluster를 사용하여 align 하였습니다. 저자들은 널리 사용되는 IEMOCAP, ESD, CREMA-D, RAVDESS dataset을 이용하였습니다. 저자들은 d-vector와 ECAPA-TDNN을 speaker embedding network로 사용하였으며, 둘 다 voxceleb2 dataset, generalized end-to-end loss and angular margin softmax loss와 같은 metirc-based objective를 이용하여 학습되었습니다. intra-speaker cluster label과 emotion category 사이 alignment를 평가하기 위해 Normalized Mutual Information (NMI), Adjusted Rand Index (ARI), Purity Score, Sulhouette Score과 같은 metric을 이용하였습니다. 모든 metric은 speaker 별로 평균을 구했으며, 값이 클수록 더 강한 alignment를 의미합니다.
Cluster and Evaluation

clustering 결과는 위와 같습니다. ESD dataset은 일관성 있게 높은 결과를 보였습니다. utterance가 very clean 하고 linguistic content가 감정 category에 상관없이 normalize 된 경우, 감정 강도가 높기 때문에 이러한 결과를 보입니다. 다른 dataset은 ESD만큼 높은 결과를 보이진 않지만, 의미 있는 연관성은 존재합니다. IEMOCAP dataset은 reverberawtion, overlapping speech와 같은 challenge가 존재하기 때문에 가장 낮은 결과를 보였으며 speaker embedding에 variance이 적용되었을 수 있기 때문입니다.
위 그림은 t-SNE plot 결과를 보여줍니다. ESD dataset에서는 잘 분리된 결과를 보여주며 IEMOCAP dataset에서는 몇몇 분리된 분포를 보여줍니다. clustering 결과는 speaker embedding이 embedding space에서 서로 다른 emotional state에 따라 group을 만드는 경향이 있다는 것을 입증합니다. 이상적이지 않은 경우에서는 speech signal의 다른 요소들의 영향 때문에 emotion category랑 intra-speaker cluster 사이 correspondenc의 limit이 존재할 수 있습니다. 제한된 정확도의 cluster라도 학습에 효과적으로 사용될 수 있다는 것이 입증되었으며, 여기에서 영감을 받아 저자들은 emotion category가 intra-speaker에서 cluster 되는 경향을 활용한 contrastive learning strategy를 제안합니다.
Contrastive Learning for SER
이 연구에서는 emotion label을 사용하지 않은 새로운 contrastive pretraining strategy를 제안합니다. 이는 speaker embedding 내의 intra-spekaer cluster 형태로 존재하는 감정 관련 정보를 활용하는 방식입니다. learning objective는 positive pair의 similarity는 maximize 하고 negative pair의 similarity는 minimize 하는 것입니다. 동일한 intra-speaker cluster에서 sample 한 utterance는 positive pair이고, 이는 동일한 감정을 공유할 가능성이 높습니다. negative example은 동일한 화자의 다른 intra-speaker cluster에서 추출되며, 서로 다른 감정을 나타낼 가능성이 높습니다.
Contrastive Pretraining
speaker-embedding 내의 intra-speaker cluster 형태로 존재하는 감정 관련 정보를 활용합니다. variant NT-Xent loss를 사용하며, 다음 식과 같습니다.
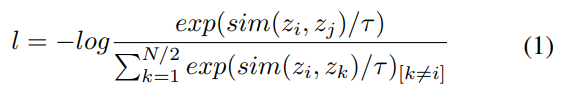
위 식에서 zi,zj는 positive pair를 나타내고, zi,zk는 negative pair를 나타냅니다. similarity function sim(x,y)=xTy/||x||⋅||y||은 cosine similarity를 구합니다. τ는 temperature parameter를 나타냅니다.
- Soft-sampling
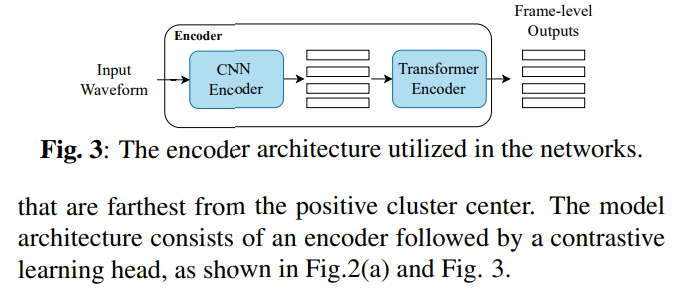
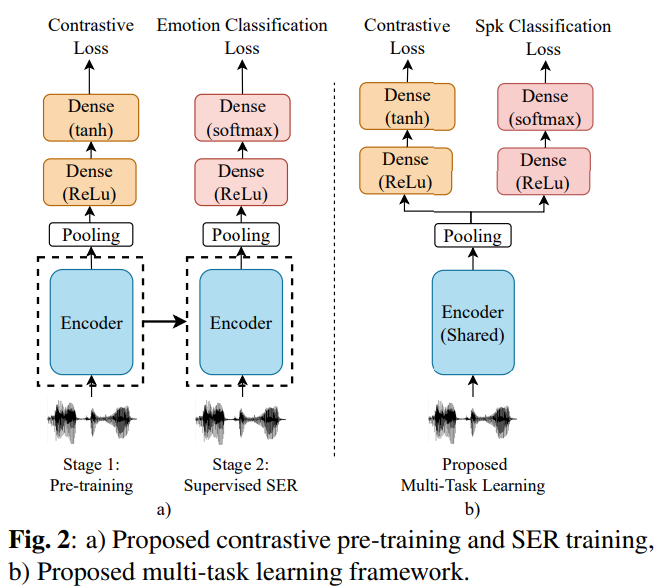
각 utterance마다 저자들은 intra-speaker cluster label에 맞춰 1개 positive utterance와 N/2가 negative utterance를 선택합니다. negative example을 선택할 때 rough clustering이기 때문에, 저자들은 soft-sampling strategy를 사용합니다. positive cluster의 centre에서 가장 먼 cluster에서 하나씩 선택하는 방식입니다. model 구조는 encoder와 contrastive learning head로 구성되며, 위와 같습니다.
Contrastive Pretraining for Multi-Task Design
speaker recognition에서 SER로의 transfer learning이 성공적으로 가능했기 때문에, 저자들은 available speaker label을 이용하는 multi-task learning (MTL) strategy을 제안합니다. proposed multi-task framework는 shared enocder layer with two separte head를 포함합니다. 각 head는 contrastive learning head와 speaker classification head입니다. contrastive learning head는 contrastive pretraining 과정에서 학습되며, speaker classification head는 speaker label에 cross-entropy loss를 적용해 학습됩니다.
Speech Emotion Recognition
large-scale emotion-unlabeled dataset으로 pretraining을 진행한 후, model을 categorical emotion albel이 존재하는 smaller dataset으로 supervised manner training을 진행합니다. supervised training 과정에서 pre-trained encoder layer 뒤에 새롭게 초기화되는 classification head를 추가합니다. 이 classification head는 average pooling layer, dense projection layer with ReLU activation, dense output layer with softmax activation으로 구성됩니다. cross-entropy loss and emotion label을 이용해 pre-trained layer와 classification head를 fine-tune 합니다.
Experiments
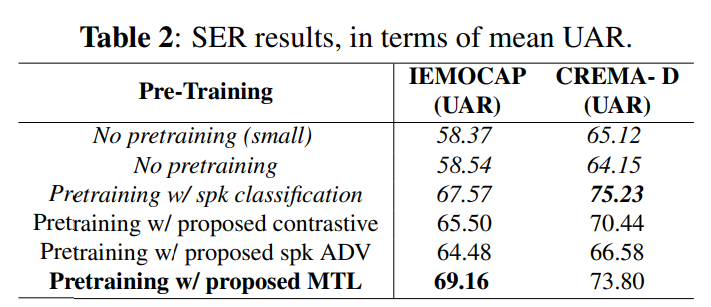
Pretraining w/ proposed contrastive로 표기된 저자들의 contrastive strategy이 pretraining을 하지 않은 case보다 더 뛰어난 SER 성능을 달성했습니다. supervised speaker classification으로 pretraining 한 경우도 뛰어난 성능을 달성했습니다. proposed multi-task learning approach는 speaker and emotion recognition 사이 inherent connection을 이용하여 intra-speaker variation을 고려하며, IEMOCAP에서 가장 좋은 성능을 달성했습니다.
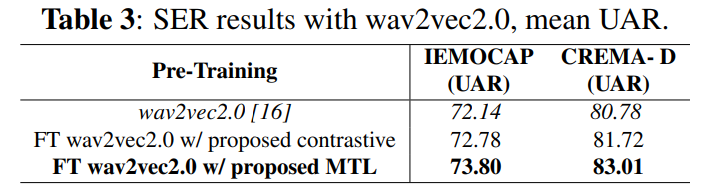
위 표를 통해 저자들의 fine-tuning wav2vec2.0 with multi-task setting이 가장 좋은 성능을 보인다는 것을 입증하였습니다.
Conclusion
저자들은 speaker embedding을 이용하여 SER task를 수행하는 potential을 보였습니다. intra-speaker cluster를 통해 SOTA speaker embedding과 emotion embedding 사이 direct link를 수립하였습니다. 저자들의 emotion unlabeled dataset에 대한 새로운 contrastive pretraining approach는 SER 성능을 크게 향상시킵니다. 저자들의 연구는 speaker embedding과 emotion embedding에 대한 이해뿐만 아니라 data가 부족한 경우에 대한 SER의 실용적인 solution을 제안합니다.



