https://arxiv.org/abs/2106.10132
VQMIVC: Vector Quantization and Mutual Information-Based Unsupervised Speech Representation Disentanglement for One-shot Voice C
One-shot voice conversion (VC), which performs conversion across arbitrary speakers with only a single target-speaker utterance for reference, can be effectively achieved by speech representation disentanglement. Existing work generally ignores the correla
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
single target-speaker utterance를 reference로 사용하여 임의의 화자로 목소리를 변환하는 One-shot voice conversion (VC)는 speech representation disentanglement로 수행될 수 있습니다. 대부분의 기존 방식들은 학습 과정에서 서로 다른 speech representation 사이 correlation을 무시하며, 이를 통해 content information이 speaker representation으로 누출될 수 있고 VC 성능이 저하될 수 있습니다. 이러한 문제를 완화하기 위해, 저자들은 vector quantization을 수행해 content encoding을 진행하며 학습 과정에서 mutual information (MI)를 correlation metric으로 사용합니다. 이를 통해 unsupervised 방식으로 inter-dependency를 줄여서 content, speaker, pitch representation을 적절히 분리합니다. 실험을 통해 저자들의 방식이 disentangled speech representation을 효과적으로 학습할 수 있음을 보였습니다. source linguistic content와 억양의 변화를 잘 유지하면서 target speaker의 characteristic을 잘 capture 합니다.
Introduction
VC는 source speaker의 utterance에 존재하는 준언어적 factor (speaker identity, prosody, accent 등)를 수정하여 target speaker가 말하는 것처럼 변환하는 기술을 의미합니다. 이 논문에서는 임의의 speaker의 one-shot scenario에서 speaker identity를 변환하는 것에 초점을 맞춥니다.
이 논문에서는 vector quantization과 mutual information-based VC (VQMIVC) approach를 제안합니다. mutual information은 서로 다른 representation 사이 의존성을 측정하며, 학습 과정에서 unsupervised 방식으로 학습에서 사용할 수 있습니다. 구체적으로, 저자들은 utterance를 content, speaker, pitch 라는 3가지 요소로 분해합니다. 그다음 4가지 요소로 구성된 VC system을 제안합니다. 1) acoustic feature에서 frame-level content representation을 추출하기 위해 vector quantization with contrastive predictive coding (VQCPC)을 사용하는 content encoder, 2) acoustic feature를 받아서 speaker representation인 single fixed-dimensional vector를 생성하는 speaker encoder, 3) utterance level에서 normalized fundamental frequency (F0)를 계산하는 pitch extractor, 4) content, speaker, pitch representation을 acoustic feature로 mapping하는 decoder입니다.학습할 때, VC system은 VQCPC, loss, reconstruction loss, MI loss를 minimize 하도록 최적화됩니다. VQCPC는 speech의 local strcuture를 explore 하고 MI는 서로 다른 speech representation 사이 inter-dependency를 줄입니다.
Proposed approach

Architecture of the VQMIVC system
위 그림과 같이 VQMIVC system은 content encoder, speaker encoder, pitch extractor, decoder로 구성됩니다. 각각 input voice에서 content, speaker, pitch representation을 추출하고 4번째 module인 decoder는 representation들을 acoustic feature로 mapping 합니다. K개 utterance가 있다고 가정하면, 각 utterance에서 random 하게 선택된 T개 frame에서 mel-spectrogram을 구해 acoustic feature로 사용합니다. kth mel-spectrogram은 Xk={xk,1,...,xk,T}로 표현됩니다.
- Content encoder θc
content encoder는 VQCPC를 이용해 Xk로부터 linguistic content information을 추출합니다. detail한 구조는 위와 같습니다. h-net: Xk→Zk, g-net: ˆZk→Rk, VQ operation q:Zk→ˆZk로 구성됩니다. h-net은 Xk를 받아 dense feature sequence Zk={zk,1,...,zk,T/2}를 구합니다. 이때 sequence의 length는 T에서 T/2로 줄어듭니다. 그다음 quantizer q가 학습 가능한 codebook B를 이용해 Zk를 ˆZk={ˆzk,1,...,ˆzk,T/2}로 discretize 합니다. 여기서 ˆzk,t∈B는 zk,t와 가장 가까이에 있는 vector를 의미합니다. VQ는 불필요한 detail들을 제거하는 information bottleneck을 부여하며, ˆZk가 linguistic information에 연관되도록 만들어줍니다. 그다음 content encoder θc가 VQ loss를 최소화하도록 학습합니다.
식은 위와 같습니다. 여기서 sg(⋅)은 stop-gradient operator를 의미합니다. ˆZk가 local structure를 capture 하도록 만들기 위해, constrastive predictive coding (CPC)를 이용합니다. RNN based g-net이 ˆZk를 받아 Rk={rk,1,...,rk,T/2}을 생성합니다. rk,t가 주어지면 model은 positive sample과 negative sample을 구분하도록 학습됩니다. m step 이후의 sample인 ˆzk,t+m을 positive sample로 사용하고 set Ωk,t,m에서 negative sample을 추출하여 사용하고, InfoNCE loss를 minimize하는 방식으로 학습됩니다.
T′=T/2−M,Wm(m=1,2,...,M)은 trainable projection matrix을 나타냅니다. probabilistic contrastive loss를 이용하여 future sample을 예측함으로써, local feature (e.g., phonemes)을 ˆZk=f(Xk;θc)로 encode 합니다. 이 content representation을 이용해 정확한 linguistic content를 reconstruct 합니다. set Ωk,t,m은 current utterance에서 random 하게 선택된 sample들로 구성됩니다. 위 식을 통해 future sample에 대해선 정확한 예측을 하면서 negative sample과는 멀어지도록 학습됩니다.
- speaker encoder θs
speaker encoder는 Xk를 받아 vector sk=f(Xk;θs)를 생성합니다. 이는 생성된 speech의 speaker identity를 control하는 global speech characteristic을 capture 합니다.
- Pitch extractor
pitch representation은 intination variation을 포함하지만 content and speaker information은 존재하지 않길 원합니다. 그래서 저자들은 wavefor에서 F0를 추출하고 각 utterance마다 z-normalization을 적용합니다. 저자들은 log-normalized F0을 pk=(pk,1,...,pk,T)로 사용하며, 이는 speaker-independent 하기 때문에 speaker encoder가 speaker information을 제공하도록 학습됩니다.
- Decoder θd
decoder는 content, speaker, pitch representation을 mel-spectrogram을 mapping 합니다. ˆZk에 linear interpolation (x2)를 적용하고 sk에 repetition (xT)를 적용하여 pk와 align 합니다. 그리고 이를 decoder의 input으로 사용하여 mel-spectrogram을 생성합니다. decodoer는 content and speaker encoder와 동시에 학습되며, reconstruction loss를 minimize 하도록 학습됩니다.
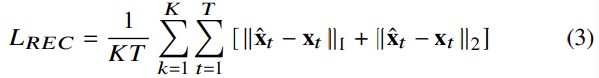
MI minimization integrated into VQMIVC training
random variable u, v가 주어지면, joint and marginal distribution의 KL divergence이 MI가 되며, 식으로 나타내면 I(u,v)=DKL(P(u,v);P(u)P(v))입니다. 저자들은 vCLUB을 이용해 MI의 upper-bound를 구합니다.
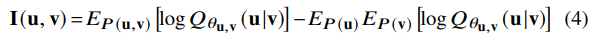
u,v∈{ˆZ,s,p},ˆZ,s,p는 각각 content, speaker, pitch representation을 나타냅니다. Qθu,v(u|v)는 u given v의 ground-truth posterior의 variational approximation을 나타내고, 이를 network θu,v로 parameterize 합니다. 서로 다른 speech representation에 대한 unbiased estimation vCLUB은 다음과 같습니다.
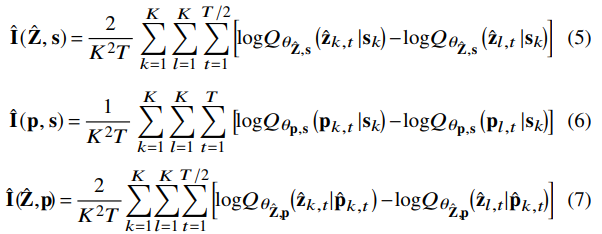
ˆpk,t=(pk,2t−1+pk,2t)/2입니다. 잘 구해진 variation approximation을 이용한다면, 식 (4)는 reliable MI upper-bound가 됩니다. 그러므로 위 식 (5 ~ 7)을 minimize 하여 서로 다른 speech representation들의 correlation을 줄일 수 있게 됩니다.
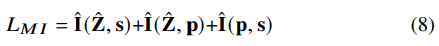
학습할 때, variation approximation network와 VC network는 번갈아 가면서 최적화됩니다. variational approximation network는 log-likelihood를 maximize 하도록 학습됩니다.
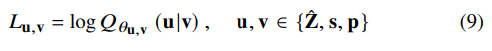
VC network는 VC loss를 minimize 하도록 학습됩니다.
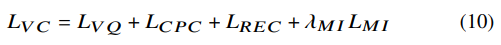
위 식에서 λMI는 MI loss가 disentanglement에 얼마나 영향을 줄지 control 하는 constasnt weight입니다. final training process는 다음과 같습니다.

text transcription이나 speaker label을 학습할 때 사용하지 않기 때문에, fully unsupervised 방식으로 disentanglement를 수행합니다.
One-shot VC
converison 할 때, source speaker의 utterance Xsrc로부터 content and pitch representation을 추출합니다. 그다음 target speaker의 utterance Xtgt로부터 speaker representation을 추출합니다. 그 다음 decoder에 넣어 generated mel-spectrogram을 얻습니다.
Experiments
Experimental setup
저자들은 VCTK corpus를 이용하여 실험을 진행했습니다. testing speaker들은 unseen speaker로 설정하여 one-shot VC 성능을 확인하였습니다.
저자들이 제안한 VC network는 content encoder, speaker encoder, decoder로 구성됩니다. content encoder는 h-net, quantizer q, g-net으로 구성됩니다. h-net은 stride 2인 convolution layer, layer normalization, linear layer, ReLU activation function으로 구성된 4개 block으로 구성됩니다. quantizer는 64-dim learnable 512개 vector로 구성된 codebook을 포함합니다. g-net은 256-dim uni-direciontal RNN layer입니다. CPC의 경우, future prediction step M을 6으로 설정하고 negative sample 수는 10으로 설정했습니다. speaker encoder는 8개 COnvBank layer를 포함하며, long-term information을 encode 합니다. decoder는 1024-dim LSTM layer, 3개 convolution layer, 2개 1024-LSTM layer, 80-dim linear layer로 구성되어 있습니다.
Experimental results and analysis
- Speech representation disentanglement performance
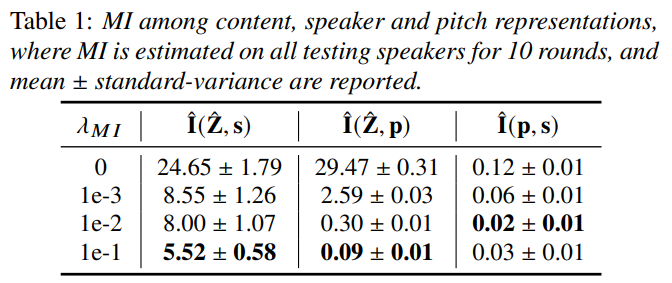
VC loss 식에서 λMI는 서로 다른 representation 간의 상관성을 줄이는 SRD의 성능을 결정하며, 결과는 위와 같습니다. λMI를 증가시킬수록 MI가 서로 다른 speech representation 간의 correlation이 줄어드는 경향을 보여줍니다.
speaker representation에 content information이 얼마나 존재하는 측정하기 위해, 2가지 방식으로 speech를 생성했습니다. 먼저 동일한 utterance에서 content, speaker, pitch representation을 추출하여 speech를 합성합니다. 그다음 방식은 하나의 utterance에서 content, pitch representation을 추출하고 같은 화자지만 다른 utterance에서 speaker reprensetation을 추출한 후 speech를 생성합니다. 그 다음 ASR system을 이용해 CER, WER을 측정합니다. 동일한 utterance를 사용하여 생성한 speech의 CER, WER에서 다른 utterance를 사용하여 생성한 speech의 CER, WER로의 상승 폭을 Δc, Δw로 표기했습니다. 결과는 다음과 같습니다.
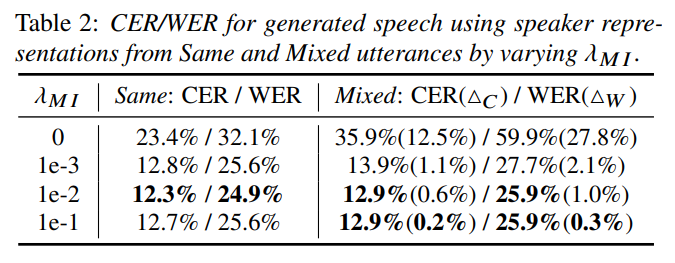
speaker representation을 생성할 때만 다른 speech를 사용했으며, 변화폭이 크다면 content information이 speaker representation에 흘러들어 갔다고 볼 수 있습니다. λMI 값이 클수록 상승폭이 작아지는 것을 볼 수 있으며, MI loss를 통해 효과적으로 분리한 것을 볼 수 있습니다.
추가적으로 저자들은 ˆZ,s를 input으로 받는 2가지 speaker classifier를 설계하였습니다. 그리고 1개 predictor를 설계하여 ˆZ를 받아 p를 infer하도록 만들었습니다. classifier랑 preidctor는 4 layer fully-connected network로 구성됩니다. 높은 speaker classification accuarcy는 ˆZ,s 둘 중 한 곳에 speaker information이 더 많이 존재한다는 것을 의미하며, prediction loss가 높다면 ˆZ에 pitch 정보다 적게 존재한다는 것을 의미합니다. 결과는 다음과 같습니다.
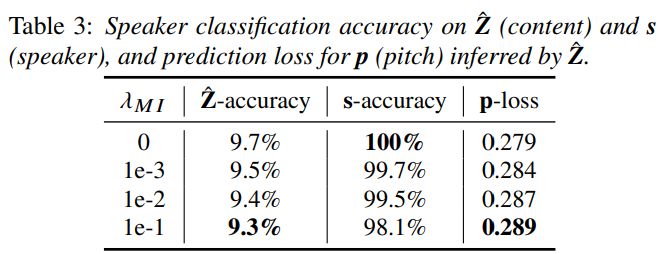
λMI 값이 증가함에 따라 더 낮은 정확도를 보이고 더 높은 pitch loss를 보이며, 이를 통해 ˆZ이 더 적은 speaker and pitch information을 포함하고 있다는 것을 확인하였습니다. 저자들은 λMI 값이 너무 커지면 s에서도 speaker 정보가 사라지는 경향을 확인하여, λMI를 1e-2로 설정하였습니다.
- Content preservation and F0 variation consistency
converted voice에 linguistic content와 intonation variation이 존재하는지 아닌지 평가하기 위해, 저자들은 converted speech의 CER/WER을 구하고 source F0와 converted F0 사이 Pearson correlation coefficient (PCC)를 계산했습니다. PCC는 -1 ~ 1 사이 값이며, 높을수록 converted voice가 source voice와 일관성 있는 F0 variation을 보인다는 것을 의미합니다. 실험 결과는 다음과 같습니다.
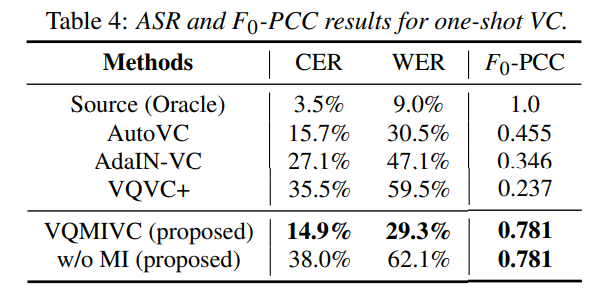
저자들의 model이 가장 좋은 성능을 달성한 것을 볼 수 있습니다.
Conclusion
저자들은 VQCPC와 MI를 결합하여 unsupervised SRD-based one-shot VC system을 제안하였습니다. content, speaker, pitch representation에 대한 적절한 disentanglement를 위해, VC model은 reconstruction loss를 minimize 할 뿐만 아니라 VQCPC loss, MI loss도 최소화하는 방식으로 학습되었습니다. 실험을 통해 저자들의 method가 효과적으로 disentanglement를 수행하는 것을 확인할 수 있었습니다.



