https://arxiv.org/abs/2006.04558
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Non-autoregressive text to speech (TTS) models such as FastSpeech can synthesize speech significantly faster than previous autoregressive models with comparable quality. The training of FastSpeech model relies on an autoregressive teacher model for duratio
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
FastSpeech와 같은 Non-autoregressive TTS model은 autoregressive model보다 빠르게 speech를 합성할 수 있으며 comparable quality를 보여줍니다. FastSpeech model을 학습할 때, autoregressive teacher model을 통해 duration prediction을 학습하고 knowledge distillation을 이용해 one-to-many mapping problem을 해결합니다. 하지만 FastSpeech는 여러 문제가 존재합니다. teacher-student distillation pipeline은 복잡하고 시간이 필요합니다. teacher model에서 추출한 duration은 정확하지 않으며, teacher model에서 distill 한 target mel-spectrogram은 정보 손실이 발생하여 voice quality에 한계를 유발합니다. 이 논문에서 저자들은 FastSpeech에서 존재하는 문제를 해결하고 one-to-many mapping 문제를 더욱 잘 해결하는 FastSpeech2라는 model을 제안합니다. 이 model은 teacher에서 추출한 simplified output 대신 ground-truth target을 이용해 model을 바로 학습합니다. speech의 더 많은 variation information (e.g., pitch, energy, more accurate duration)을 conditional input으로 사용합니다. 구체적으로 speech waveform에서 duration, pitch, energy를 추출하고 conditional input으로 사용해 학습을 진행합니다. inference 할 때는 predicted value를 사용합니다. 나아가 text에서 waveform을 직접 parallel 하게 생성하는 최초의 model은 FastSpeech 2s도 제안합니다. 실험을 통해 FastSpeech2가 FastSpeech보다 3배 더 빠른 학습 속도를 보이고 FastSpeech 2s는 inference speed까지 빠르다는 것을 보였습니다. FastSpeech2와 2s는 FastSpeech보다 더 뛰어난 quality의 voice를 생성하고 autoregressive model보다 뛰어난 성능을 보이기도 합니다.
Introduction
non-autoregressive TTS method 중 FastSpeech는 가장 성공적인 model 중 하나입니다. FastSpeech는 one-to-many mapping 문제를 완화하기 위해 2가지 방법을 사용합니다. autoregressive teacher model에서 얻은 generated mel-spectrogram을 training target으로 사용하여 target side의 data variance를 줄입니다. teacher model의 attention map에서 추출한 duration information을 이용하여 text sequence를 확장하여 mel-spectrogram sequence의 길이와 맞춥니다. 이러한 구조는 TTS의 one-to-many mapping 문제를 완화하지만, 단점이 존재합니다. two-stage teacher-student training pipeline은 학습 복잡성이 존재합니다. teacher model에서 얻은 target mel-spectrogram의 경우, ground-truth mel-spectrogram과 비교했을 때 정보 손실이 존재하며, 이를 통해 합성된 audio quality가 저하될 수 있습니다. teacher model의 attention map에서 추출한 duration은 충분히 정확하지 않을 수 있습니다.
이 논문에서 저자들은 FastSpeech의 문제를 해결하고 non-autoregressive TTS의 one-to-many mapping 문제를 더 잘 해결하는 FastSpeech 2를 제안합니다. 학습 과정을 단순화하고 teacher-student distillation에서 발생하는 data 단순화 때문에 발생하는 정보 손실을 피하기 위해, 저자들은 FastSpeech 2 model을 학습할 때 ground-truth target을 사용합니다. input text sequence와 target output mel-spectrogram 사이 information gap (input은 target을 예측할 때 모든 정보를 포함하고 있지 않음)을 줄이고 one-to-many mapping 문제를 완화하기 위해, 저자들은 pitch, energy, 더 정확한 duration과 같은 variation information을 사용합니다. 학습할 때 target speech waveform에서 duration, pitch, energy를 추출하고 condition input으로 사용합니다. inference할 때는 FastSpeech 2 model과 동시에 학습되는 predictor가 예측한 value를 이용합니다. speech의 prosody의 경우, pitch가 중요하고 시간에 따라 큰 변화를 보이기 때문에 예측하기 어렵습니다. 그래서 저자들은 continuous wavelet transform을 이용해 pitch contour를 pitch spectrogram으로 변환하고 frequence domain에서 pitch를 예측합니다. 이를 통해 predicted pitch의 정확도를 향상시킵니다. speech 합성 과정을 더욱 간단화하기 위해, 저자들은 mel-spectrogram을 intermediate output으로 사용하지 않고 바로 text를 speech waveform으로 변환하는 FastSpeech 2s도 제안합니다.
FastSpeech 2 and 2S
Motivation
TTS는 pitch, duration, sound volume, prosody와 같은 speech의 variation 때문에 text sequence에 맞춰 여러 speech sequence를 생성할 수 있으며, 이로 인해 one-to-many mapping 문제가 발생합니다. non-autoregressive TTS에서는 speech의 variance를 에측하기엔 충분하지 않은 정보를 가지고 있는 text만 input information으로 사용합니다. 이 경우 model은 학습 과정에서 target speech의 variation으로 overfit 할 수 있으며, 좋지 않은 일반화 성능을 갖게 됩니다. FastSpeech가 one-to-many mapping 문제를 완화하기 위해 design 되었지만, 여러 문제가 존재합니다. FastSpeech 2는 이러한 문제를 완화하는 것을 목표로 합니다.
Model Overview

model architecture는 위와 같습니다. encoder는 phoneme embedding sequence를 phoneme hidden sequence로 변환하고, variance adaptor는 duration, pitch, energy와 같은 variance information을 hidden sequence에 추가합니다. 최종적으로 mel-spectrogram decoder는 adapted hidden sequence를 mel-spectrogram sequence으로 변환합니다. 저자들은 self-attention layer and 1D-convoltuion stack으로 구성된 feed-forward Transformer block을 encoder와 mel-spectrogram decoder의 basic structure로 사용합니다. FastSpeech는 teacher-student distillation pipeline에 의존하고 teacher model에서 phoneme duration을 예측하지만, FastSpeech 2는 몇 가지 개선을 이뤄냈습니다.
첫째, model을 학습할 때 teacher-student distillation pipeline을 사용하지 않고 target으로 ground-truth mel-spectrogram을 바로 사용합니다. 이를 통해 distilled mel-spectrogram에서 발생하는 정보 손실을 피할 수 있으며 voice quality의 upper-bound를 향상시켰습니다. 둘째, variance adaptor는 duration predictor 뿐만 아니라 pitch and energy predictor도 존재합니다. duration predictor는 forced alignment를 통해 얻은 phoneme duration을 training target으로 사용합니다. 이는 autoregressive teacher model의 attention map에서 추출한 duration보다 더욱 정확합니다. pitch and energy predictor는 one-to-many mapping 문제를 해결할 때 중요한 역할을 할 추가적인 variance information을 제공합니다. 셋째, 학습 pipeline을 더욱 간단화하고 fully end-to-end system을 만들기 위해, 저자들은 text에서 waveform을 바로 생성할 수 있는 FastSpeech 2s를 제안합니다.
Variance Adaptor
variance adaptor는 variant speech를 예측할 수 있는 충분한 정보를 제공하는 variance information (e.g., duration, pitch, energy, etc.)를 phoneme hidden sequence에 더하는 것을 목표로 합니다. 이를 통해 one-to-many mapping 문제를 완화하길 원합니다. phoneme duration은 speech voice가 얼마나 길게 들리는지 나타내는 것이고, pitch는 감정을 전달하는 데 있어 주요한 feature이고 speech prosody에 큰 영향을 주는 feature이며, energy는 mel-spectrogram의 frame-level magnitude를 나타내고 speech의 volume과 prosody에 직접적인 영향을 줍니다. variance adaptor는 duration predictor(i.e., the length regulator as used in FastSpeech), pitch predictor, energy predictor로 구성됩니다. 학습할 때는 input recording에서 추출한 ground-truth duration, pitch, energy를 input으로 사용하여 target speech를 predict 합니다. 동시에 ground-truth duration, pitch energy를 target으로 사용하여 duration, pitch, energy predictor를 학습하고, 이 predictor들을 이용해 inference 할 때 target speech를 합성합니다. 위 그림의 (c)와 같이, duration, pitch, energy predictor는 비슷한 model structure입니다.
- Duration Predictor
duration predictor는 phoneme hidden sequence를 input으로 받아 각 phoneme의 duration을 예측합니다. 이 duration은 몇 개의 mel frame이 해당 phoneme에 대응하는 지 나타내며, 예측을 용이하게 하기 위해 logarithmic domain으로 변환됩니다. duration predictor는 MSE loss로 최적화되며 extracted duration을 training target으로 사용합니다. pre-trained autoregressive TTS model을 이용해 phoneme duration을 추출하는 대신, 저자들은 Montreal Forced Alignment (MFA) tool을 이용해 phoneme duration을 추출합니다. 이를 통해 alignment accuracy를 향상시키고 model input과 output 사이 information gap을 줄입니다.
- Pitch Predictor
pitch predictor를 사용하는 neural network 기반 TTS system들은 pitch contour를 예측하였습니다. 하지만 ground-truth pitch의 변동성이 높기 때문에, 예측된 pitch value의 분포는 ground-truth 분포와 매우 다르다는 문제가 존재합니다. pitch contour의 변동성을 더 잘 예측하기 위해, continuous wavelet transform (CWT)을 이용해 continuous pitch series를 pitch spectrogram으로 분해합니다. 이 pitch spectrogram을 training target으로 사용하여 pitch predictor를 학습하며 MSE loss를 사용하여 학습합니다. inference할 때는 pitch predictor가 pitch spectrogram을 예측하고, inverse continuous wavelet transform (iCWT)를 이용해 pitch contour로 변환합니다. pitch contour를 input으로 받기 위해, 각 frame 별 pitch F0를 log-scale 256 possible value로 quantize 하고 pitch embedding vector p로 변환하여 hidden sequence에 더합니다.
- Energy Predictor
각 short-time Fourier transform (STFT) frame의 amplitude를 energy로 사용합니다. 이 energy를 구해 256개 value로 quantize한 후 energy embedding e로 encode 합니다. 그 후 hidden sequence에 더합니다. quantized value 대신 orignal energy value를 예측하도록 energy predictor를 설계했으며, MSE loss로 최적화합니다.
FastSpeech 2S
fully end-to-end text-to-waveform generation이 가능한 FastSpeech 2s를 제안합니다. 이는 text에서 바로 waveform을 생성할 수 있으며, cascaded mel-spectrogram generation & waveform generation 과정이 필요 없습니다. FastSpeech 2s는 intermediate hidden을 condition으로 하여 waveform을 생성하며, inference 과정을 간략화합니다.
Challenges in Text-to-Waveform Generation
TTS를 fully end-to-end framework로 수행하기 위해선 몇 가지 문제점이 존재합니다. 1) waveform은 mel-spectrogram보다 더 많은 variance information (e.g., phase)을 포함하고 있기 때문에, text-to-spectrogram generation에서 발생하는 information gap보다 input과 output 사이 information gap이 더 큽니다. 2) full text sequence의 audio clip을 가지고 학습하는 것은 GPU memory를 많이 소비하게 됩니다. 결과적으로 부분적 text sequence와 그에 대응하는 short audio clip을 가지고 model을 학습해야만 하며, 전체 문맥 간 phoneme 관계를 포착하기 어려워져 text feature extraction 성능이 저하됩니다.
Our Method
위에서 언급한 문제들을 완화하기 위해, 저자들은 waveform decoder에 몇 가지 design을 추가했습니다. variance predictor를 이용하여 phase information을 예측하는 것은 어렵기 때문에, 저자들은 adversarial training 방식으로 waveform decoder를 학습하였습니다. 이를 통해 implicit 하게 phase information을 recover 할 수 있게 됩니다. FastSpeech 2의 mel-spectrogram decoder를 이용하여 text feature extraction을 수행합니다. waveform decoder는 WaveNet 기반 구조입니다. discriminator를 이용해 adversarial training을 수행하며, Parallel WaveGAN과 동일한 구조의 discriminator를 사용합니다. waveform decdoer는 multi-resolution STFT loss와 LSGAN discriminator loss를 이용하여 optimize 됩니다.
Experiments and Results
Results
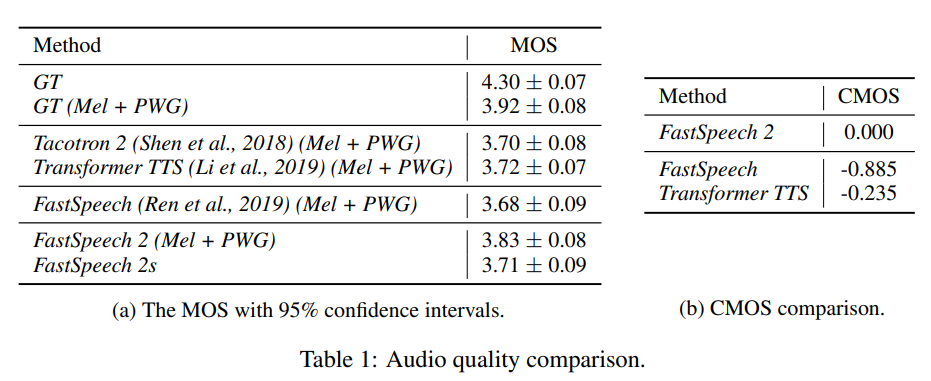
MOS 결과는 위와 같습니다. 저자들이 제안한 FastSpeech 2가 더 좋은 성능을 달성한 것을 볼 수 있으며, FastSpeech 2s도 뛰어난 성능을 보이는 것을 볼 수 있습니다.
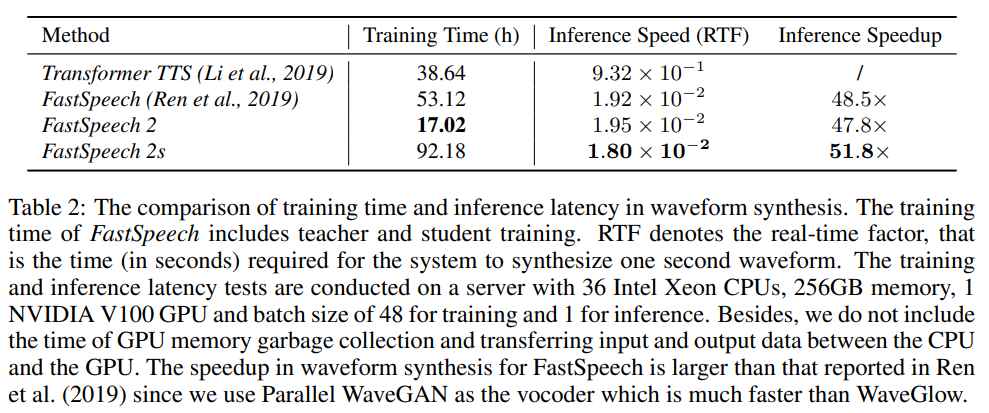
inference speed는 위와 같습니다. FastSpeech 2s가 빠른 inference speed를 보여줍니다.
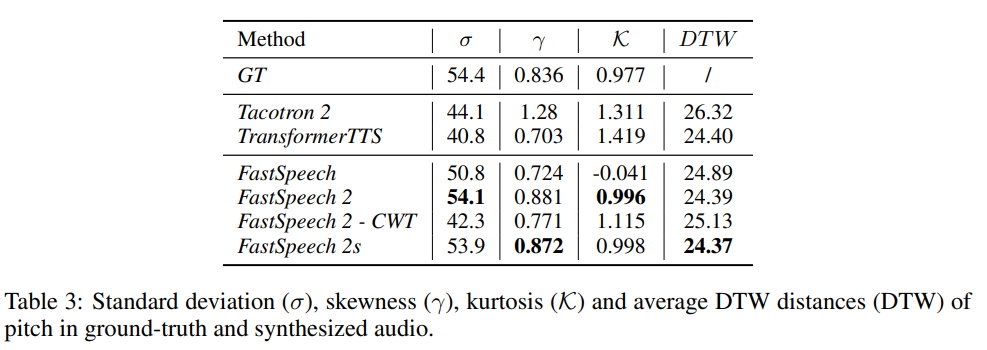
FastSpeech 2, 2s에 pitch와 energy와 같은 추가적인 variance information을 input으로 제공했을 때, 더 정확한 pitch and energy를 나타내는 speech를 합성하는지 측정하였습니다.
pitch의 경우, generated speech와 ground-truth speech의 pitch distribution을 통해 standard deviation, skewness, kurtosis, average dynamic time warping (DTW) distance를 측정했습니다. 결과는 위와 같습니다. FastSpeech와 비교했을 때, FastSpeech 2/2s가 ground-truth와 더욱 유사한 값들을 나타내는 것을 볼 수 있습니다. 그리고 DTW도 더 적은 것을 볼 수 있습니다. 이를 통해 FastSpeech보다 더욱 자연스러운 speech를 합성한다는 것을 볼 수 있습니다.

energy에 대한 결과는 위와 같습니다. 저자들이 제안한 FastSpeech 2/2s가 더욱 뛰어난 성능을 보여줍니다.
Conclusion
이 논문에서는 fast and high-quality end-to-end TTS system인 FastSpeech 2를 제안합니다. 이는 training pipeline을 단순화하기 위해 ground-truth mel-spectrogram을 이용하여 바로 model을 학습하고 FastSpeech에서 존재하는 information loss를 줄였습니다. duration accuracy를 향상하고 pitch와 energy를 포함한 추가적인 variance information을 이용하여 one-to-many mapping 문제를 완화했습니다. 그리고 FastSpeech 2 기반의 FastSpeech 2s도 제안합니다. 이는 text에서 바로 waveform을 생성하는 model이며, inference speed가 더 빠릅니다.



