https://arxiv.org/abs/2309.07592
StarGAN-VC++: Towards Emotion Preserving Voice Conversion Using Deep Embeddings
Voice conversion (VC) transforms an utterance to sound like another person without changing the linguistic content. A recently proposed generative adversarial network-based VC method, StarGANv2-VC is very successful in generating natural-sounding conversio
arxiv.org
해당 논문을 보고 작성했습니다.
Abstract
Voice Conversion (VC)은 linguistic content는 유지한 채로 다른 사람이 말하는 것처럼 utterance를 변환합니다. 최근에 제안된 generative adversarial network-based VC method인 StarGANv2-VC는 자연스럽게 들리는 covnersion을 성공적으로 수행했습니다. 하지만 이 method는 변환된 sample에서 source speaker의 감정을 보존하는데 실패했습니다. 이 논문에서는 StarGANv2-VC가 speaker와 emotion representation을 분리하는 데 실패했다는 것을 보이며, 적절한 감정을 보존하는 것을 실패했다는 것을 보입니다. 구체적으로 학습 과정에서 speaker embedding을 capture 하기 위해 사용했던 reference audio에서 emotion이 leakage 됩니다. 이 문제를 해결하기 위해, 저자들은 새로운 emotion-aware loss와 latent emotion representation을 통해 emotion supervision을 사용하는 unsupervised method를 제안합니다.
Introduction
최근 여러 StarGAN-based non-parallel many-to-many VC framework들이 등장했습니다. StarGAN-v2-VC framework는 fundamental frequency (F0) consistent, natural sounding and highly intelligible converted sample을 생성합니다. 그리고 architecutre design은 매우 scalable하기 때문에, 어떠한 길이의 utterance라도 상관없이 빠르게 변환할 수 있으며 real-tim application에 적합합니다. 하지만 model은 source utterance의 acoustic parameter가 크게 변하는 경우, source speaker의 감정적 상태를 보존하지는 못합니다.
이 논문에서는 StarGANv2-VC가 source speaker의 감정을 보존하지 못하는 이유에 대해 조사합니다. 그리고 이 문제를 피하는 새로운 method를 제안합니다. 이때 latent emotion representationㅇ르 통해 unsupervised emtoion supervision technique을 이용합니다. 그리고 저자들은 speaker embedding을 추출하는 데 사용하는 reference audio에서 emotion이 leakage 되는 것을 막기 위해, speaker와 emotion representation을 disentanglement 하는 데 도움을 주는 loss를 제안합니다.
StarGANv2-VC and Emotion Leakaga
Architecture

StarGANv2-VC의 architecture는 위와 같으며, emotion supervision component가 존재합니다. generator G는 encoder (EN)과 decoder로 구성되어 있으며 ocnverted utterance Xtrg을 생성합니다. generator는 source speaker ysrc의 utterance인 Xsrc와 target speaker ysrc의 speaker style-embedding hsty을 input으로 받습니다. 저자들에 따르면, generator가 pre-trained network로 source F0 embedding hf0를 생성하여 사용하고, 이는 model이 F0 consistent conversion을 수행할 수 있도록 만들어줍니다. speaker-style encoder (SE)는 target speaker ytrg의 reference utterance 중 random 하게 선택한 Xref에서 speaker-style embedding hsty을 생성하며, 이때 target speaker-code를 사용합니다. embedding hsty은 accent와 같은 speaker-style information을 나타냅니다. 따라서 converted sample Xtrg=G(Xsrc,hf0,hsty)은 target speaker의 speaker characteristic을 포함하지만 source utterance의 억양과 linguistic content을 나타냅니다. G가 unique sample을 생성하도록 만들기 위해, separte mapping network (M)도 학습됩니다. 학습할 때, SE와 M이 번갈아 가며 speaker-style embedding을 생성합니다. module M은 normal Gaussian distribution과 target speaker-code로부터 random latent vector를 sample 하여 target speaker embedding을 생성합니다. discriminator는 quality classifier (C)와 speaker classifier (Csp)라는 2가지 adversarial classifier로 구성됩니다. C classifier는 speaker-code를 condition으로 받아 real sample인지 fake sample인지 분류합니다. classifier Csp는 converted sample의 source speaker를 분류합니다.
Emotion Leakage by Speaker Embedding
speaker-style-encoder (SE)는 target speaker의 style-embedding을 추출합니다. emotion-leakage을 확인하기 위해, 저자들은 ESD corpus의 영어 utterance를 가지고 vanilla StarGANv2-VC을 학습시켰습니다. 이후 speaker embedding을 추출했습니다. 저자들은 2명의 화자인 0012(남성), 0016(여성)을 선택했습니다. model은 이 두 화자의 utterance를 이용하여 학습되었습니다. tSNE transformation을 이용하여 speaker embedding을 2D space로 project 하였으며, 결과는 다음과 같습니다.
single speaker의 speaker embedding들은 utterance의 emotion에 상관 없이 compact region space에 위치해야 합니다. 하지만 위 그림을 보면 감정을 기반으로 불필요한 grouping을 형성하는 것을 볼 수 있습니다. 이는 SE가 utterance로부터 target speaker embedding을 생성할 때 reference utterance에서 emotional cues를 분리하는 데 실패했다는 것을 의미합니다. 결과적으로 의도치 않은 감정적 정보가 decoder에 흘러 들어가 target sepaekr의 style representation에 영향을 주게 됩니다. 이는 decoder가 target speaker의 voice를 사용하여 utterance를 생성할 때 혼란을 야기하게 됩니다. 이 leakage는 다음 2가지 이유 때문에 발생합니다. 1) SE가 speaker-dependent and speaker-independent feature 사이 분리를 수행할 수 있도록 encourage 하는 training objective의 부재, 2) vanilla StarGANv2-VC를 학습할 때 사용했던 speaker-style reconstruction loss Lstyle 때문입니다.
위 식은 speaker-style reconstruction loss를 나타냅니다. 이는 generated sample에서도 동일한 style embedding이 regenerate 하도록 만듭니다. 이 loss는 converted sample의 speaking style이 reference sample과 가까워지도록 만들어줍니다. 이는 reference utterance의 emotional cue와 target speaker embedding을 분리하지 못하게 만들며, domain leakage problem을 악화시킵니다. 그러므로 이 loss를 minimize 함으로써, converted speech는 reference의 style을 따라갈 뿐만 아니라 감정도 따라가게 되며, source speech의 감정은 억제하게 됩니다. 이를 통해 vanilla StarGANv2-VC의 emotion preservation 성능이 나빠지게 됩니다.
Methods
많은 양의 good quality emotion label을 사용하기 어렵습니다. 그리고 non-parallel voice conversion의 경우, converted sample의 emotion label을 사용할 수 없습니다. 그러므로 emotion leakage problem을 피하기 위해, 저자들은 emotion representation을 이용하여 unsupervised emotion supervision technique을 제안합니다. emotion representation은 utterance의 감정 상태에 대한 정보를 포함하고 있는 deep-emotion embedding입니다. proposed method는 generator가 source speech의 감정 상태를 보존한 채로 converted sample을 생성하도록 도와줍니다.
Deep Emotion Embedding and Emotion Supervision
source에서 latent emotion representation을 추출하고 converted sample에서도 latent emotion representation을 추출한 다음, 둘 사이 거리를 minimize 하는 것이 emotion supervision을 제공하는 방법 중 하나입니다. 이를 위해, emotion embedding extraction network는 utterance에서 바로 latent emotion representation을 생성할 수 있어야 합니다. emotion embedding extraction network를 생성하기 위해, 저자들은 two-stage approach를 제안합니다.
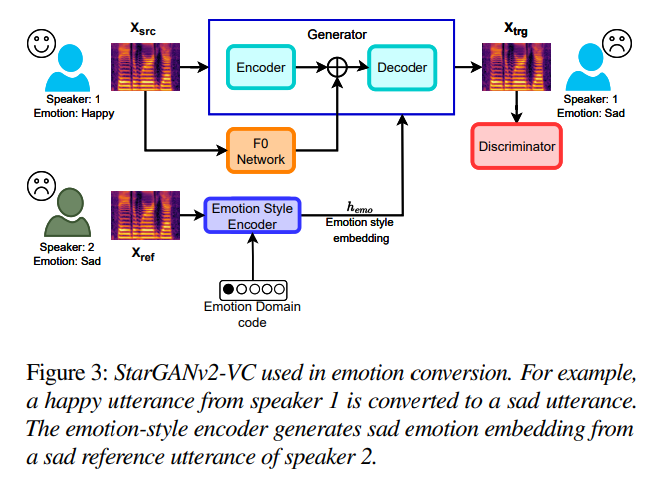
Stage-Ⅰ에서는 speaker 특성 대신 emotion을 변환하는 emotion conversion framework를 학습합니다. 저자들은 vanillia StarGANv2-VC framework를 emotion conversion task에 맞춰 사용하였으며, 구조는 위와 같습니다. 이 경우, style encoder는 speaker 대신 emotion representation을 capture 하게 됩니다.
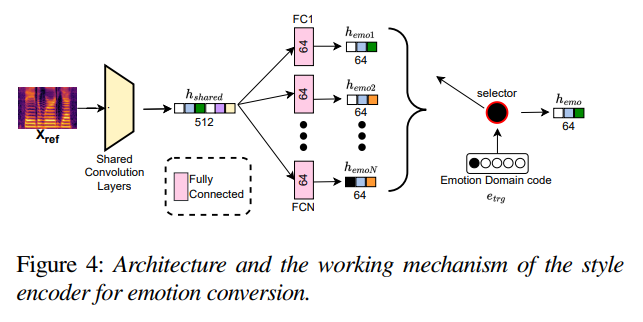
emotion conversion task에서 사용하는 style encoder는 위와 같습니다. shallow shared convolution layer는 reference mel-spectrogram에서 512-dim shared latent representation을 추출합니다. 그다음 fully connected (FC) layer는 이 shared embedding을 emotion-specific 64-dim emotion-style embedding hemo1,...,hemoN으로 project하며, N은 emotion class 수를 나타냅니다. 마지막으로 emotion-code etrg에 맞춰 emotion style-embedding hemo을 선택합니다. emotion-code는 utterance의 emotion class를 나타냅니다. 그러므로 emotion ground truth를 사용할 수 없는 경우, emotion-code를 선택하는 것도 불가능합니다. 이는 emotion ground-truth가 없는 경우, emotion extraction을 이용하여 VC를 수행할 수 없게 됩니다. 그래서 저자들은 emotion ground truth의 이용 가능 여부에 의존하지 않는 mechanism이 필요하며, Stage-Ⅱ에서 수행합니다.
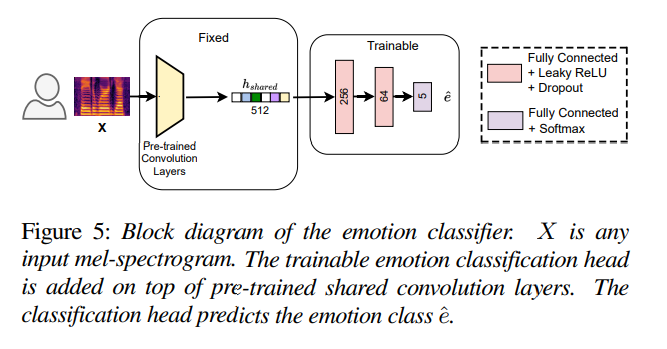
Stage-Ⅱ에서는 pre-trained SE에 존재하는 linear projection FC layer를 제거하고 3개 FC layer로 구성된 classification head를 적용하며, 구조는 위와 같습니다. classifier는 supervised emotion classification task에 맞춰 학습됩니다. 학습 과정에서 shallow pre-trained convolution layer는 fix 하고 classification head weight만 최적화됩니다. Stage-Ⅱ 이후 2번째 FC layer의 64-dim output feature를 latent emotion representation으로 사용합니다. 이를 Figure 1의 emotion embedding extractor module Cemo로 사용합니다. 이를 통해 utterance에서 deep emotion representation을 추출할 수 있게 되며, emtoion ground truth가 없더라도 deep emotion representation을 추출할 수 있게 됩니다. source and converted speech에서 추출한 emotion representation에 대한 loss는 다음과 같이 정의됩니다.
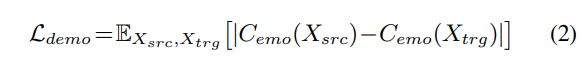
위 Ldemo loss를 minimize 하도록 StarGANv2-VC를 학습시킵니다. 이를 통해 emotion을 보존하면서 refernece utterance에서 emotion이 leakage 되는 것을 막을 수 있게 됩니다.
Style Reconstruction Loss
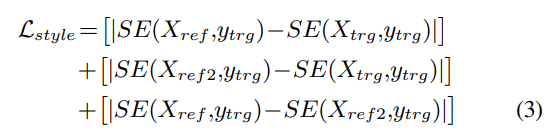
reference utterance에서 의도치 않은 emotion-indicating information과 target speaker의 style embedding 사이 분리를 위해, 저자들은 style reconstruction loss Lstyle을 적용합니다. 식은 위와 같습니다. Xref2는 동일한 화자의 random 하게 선택된 reference utterance를 의미합니다. 이 loss는 model이 Xref와 Xref2에서 추출한 target speaker style embeddin이 가깝게 만들도록 도와줍니다.
Conversion Invariant Feature Preservation Loss
vanilla StarGANv2-VC에서는 모든 loss가 generator output에 바로 적용되었습니다. 그래서 encoder의 shallow convolution layer는 conversion invariant feature에 대해선 supervision이 거의 존재하지 않게 되었습니다. content and emotion-related feature와 같은 conversion invariant feature는 preserve 되어야 하며 encoder의 latent output에도 존재해야 합니다. 이를 위해 저자들은 새로운 loss인 Linv를 제안합니다. 이는 encoder EN에 바로 적용되는 loss입니다. 이는 source와 converted sample에서 생성된 latent code 사이 distance를 minimize 하는 loss이며, encoder가 latent output에 more content and emotion-related feature를 보존하도록 만들어줍니다. 이 loss는 speaker-specific feature와 content feature를 분리하는데도 도움을 줍니다.
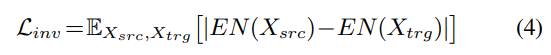
Overall Training Objective
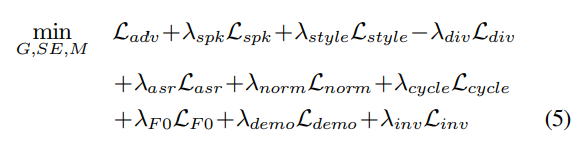
Generator의 overall training objective는 위와 같습니다. Ladv는 typical adversarial loss를 나타냅니다. Lspk는 adversarial speaker classifier loss, Ldiv는 다른 style-embedding이 주어졌을 때 다양한 sample을 생성하도록 도와주는 loss를 의미합니다. Lasr은 linguistic content preservation loss를 나타냅니다. Lnorm은 voiced/unvoiced interval을 보존하기 위한 norm consistency loss를 의미합니다. Lcycle은 generator가 source and target speaker 사이 bijective mapping을 학습할 수 있도록 도와주는 cycle consistency loss이고, LF0는 F0-consistent sample을 생성하도록 도와주는 F0 consistency loss입니다.
Experiments and Results
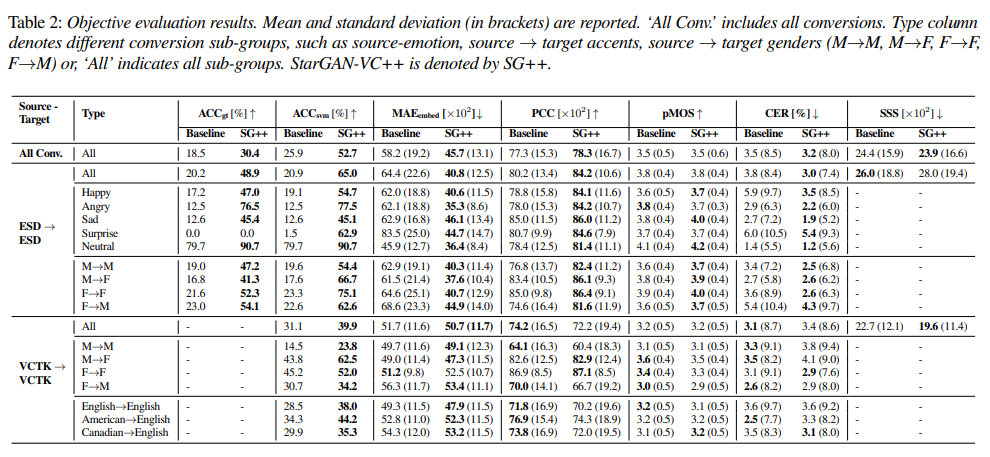
실험 결과는 위와 같습니다. 저자들이 제안한 StarGAN-VC++가 다른 baseline보다 emotion-preservation metric에서 뛰어난 성능을 달성합니다. Baseline은 25.9%의 emotion preservation accuracy를 달성했지만, StarGAN-VC++는 52.7%를 달성합니다. MAEembed 역시 StarGAN-VC++가 낮은 값을 보여줍니다. PCC 또한 더 높은 value를 달성합니다. 즉 억양을 잘 표현하는 것을 나타냅니다.
Conclusion
이 논문에서는 SOTA vc method인 StarGANv2-VC가 emotion preservation을 실패한 원인을 조사합니다. 저자들은 학습 과정에서 target speaker style과 emotion embedding의 분리가 불가능하다는 것을 발견했습니다. 그래서 reference utterance의 emotional content가 decoder에 흘러 들어가 source utterance의 emotion preservation을 방해하게 됩니다. 저자들은 새로운 deep emotion-embedding generation technique과 emotion-aware loss를 제안하며, 이를 통해 source emotion을 보전하는 generator를 구현하였습니다. 실험 결과를 통해, 저자들의 model이 emotion preservation을 잘 수행한다는 것을 보였습니다.



