해당 자료는 https://m.edwith.org/machinelearning1_17/intro 해당 강의에서 제공합니다.
이번 강의에서는 Naive Bayes Classifier에 대한 내용입니다.

일단 우리가 사용할 dataset이 위 표와 같다고 하겠습니다. EnjoySpt는 Yes, No 두 가지로 이루어진 class Y입니다. sky, temp, humid, wind, water, forecst는 X의 feature입니다. 그리고 각 feature마다 단 2개의 선택지가 있다고 하겠습니다. 이런 경우 몇 개의 parameter가 필요한지 보겠습니다. 먼저 P(Y = y)의 경우 no의 경우일 때 yes 1개만 제외한 k - 1개만 있으면 됩니다. 위 표에서는 k - 1 = 1입니다. P(X = x | Y = y)의 경우에는 (2^d - 1) k개입니다. 각 feature마다 선택지가 2개이기 때문에 2^d가 되고 마지막 combination의 경우는 1에서 여태까지를 빼면 되므로 2^d - 1이 됩니다. k를 곱한 이유는 class의 개수도 곱해야 하기 때문입니다. 위 표의 경우에서는 (2^6 - 1) * 2가 됩니다.

model을 학습하기 위해선 큰 dataset이 필요합니다. 그렇게 된다면 P(X = x | Y = y)에 필요한 parameter는 상당히 커지고 이를 계산할 수 없습니다. x를 feature에 맞춰 vector로 표현할 수 있고 이 vector는 feature 개수 d만큼의 길이를 갖습니다.

parameter 개수를 줄이기 위해 conditional independence를 사용합니다. 각 feature들이 독립적이라고 가정을 해 확률들의 곱으로 표현하는 방식입니다. 이렇게 한다면 parameter수는 줄어들 것입니다. P(x1, x2 | y)는 P(x1|Y) P(x2|Y)로 표현할 수 있게 됩니다. 예시를 보겠습니다. 만약 비가 오고 번개가 칠 때 천둥이 칠 확률이 번개가 칠 때 천등이 칠 확률과 같다면 비가 온다는 것은 천둥이 친다는 것에 conditional indenpendence 하다는 것으로 볼 수 있습니다.
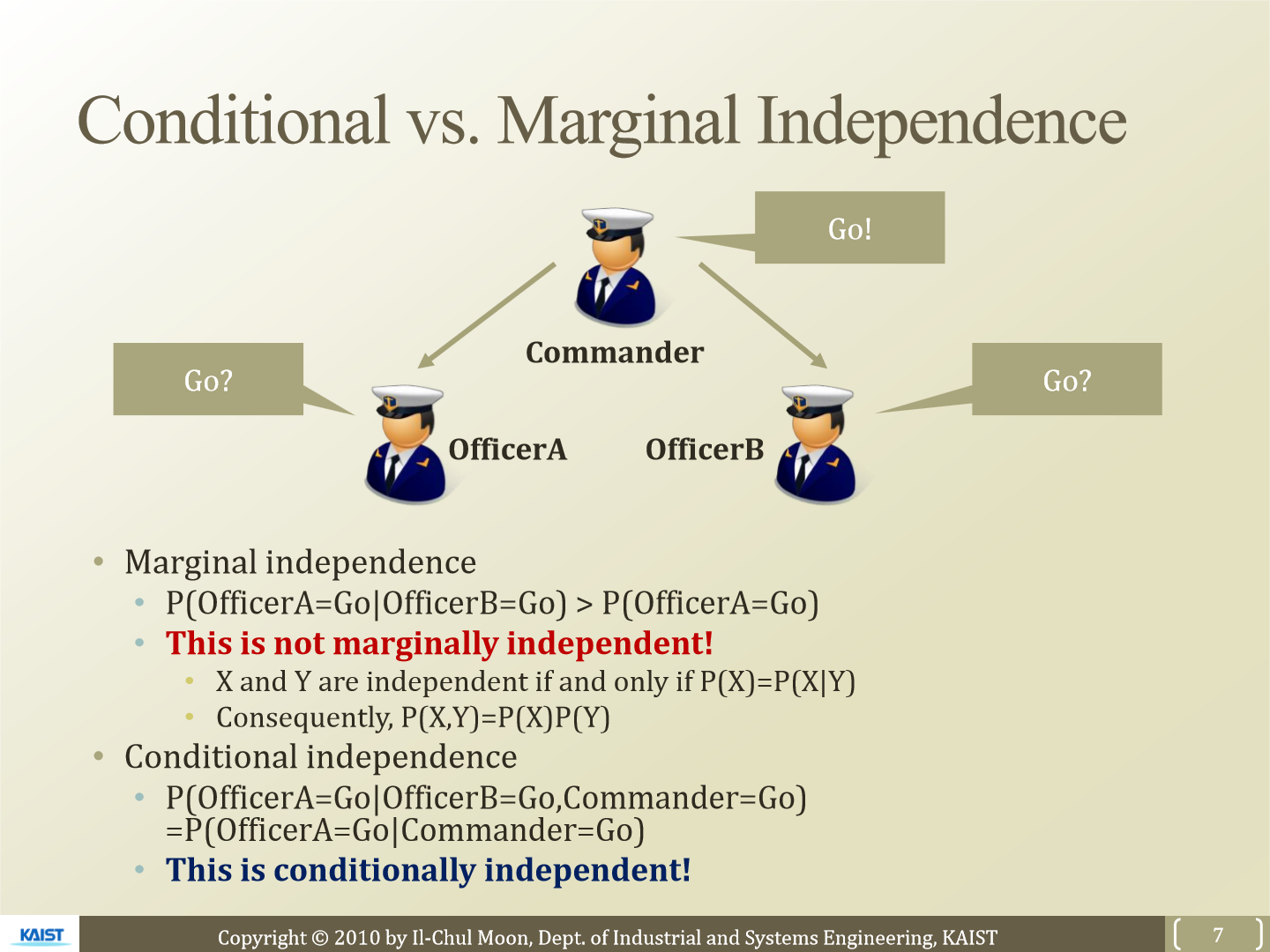
교수님이 수업시간에 설명하신 대로 예시를 들어 보겠습니다. commander가 앞으로 가라고 명령을 내리고 officer A와 B가 하는 행동을 하는 상황입니다. 만약 officer A와 B가 commander의 명령을 듣지 못한 상황입니다. 이 경우 officer A는 officer B가 앞으로 간다면 따라서 갈 것입니다. 즉 P(officer A = Go | officer B = Go) > P(officer A = Go)가 됩니다. 이런 경우 marginally independent라고 볼 수 없습니다. X와 Y가 independet 하기 위해선 P(X) = P(X|Y) 일 경우에만 성립합니다. 즉 P(X) = P(X, Y) / P(Y)가 되고 P(X) P(Y) = P(X, Y)가 됩니다.
그럼 officer A가 commander의 명령도 들었고 officer B가 앞으로 가는 걸 아는 상황에서 A가 앞으로 갈 확률을 보겠습니다. 이 경우 B가 앞으로 가든 말든 A는 앞으로 갈 것입니다. 즉 P(officer A = Go | officer B = Go, commander = Go) = P(officer A = Go | commander = Go)가 됩니다. 즉 latent variable만 officer A의 행동에 영향을 줍니다. latent variable(class variable)과 다른 variable이 주어졌을 때 오직 latent variable만 영향을 준다고 볼 수 있습니다.

conditional independent를 보기 전에 P(X = x | Y = y)를 구하기 위해 필요한 parameter는 (2^d - 1)k개였습니다. conditional independent를 이용해 parameter 개수를 확인하면 (2 - 1) dk개가 됩니다. 한 feature마다 2개의 경우의 수가 존재하기 때문에 (2 -1)이 됩니다. 개별 feature들의 곱으로 P(X = x | Y = y)가 표현됩니다.

사실 이러한 방식은 현실세계에서 올바르지 않습니다. feature들이 서로 독립적으로 본다는 것 자체가 문제가 있습니다. 그렇기 때문에 이러한 방식으로 classifier하는 것을 naive bayes classifier라는 이름으로 부릅니다.
naive bayes classifier function은 위와 같은 식으로 표현합니다.

이러한 naive bayes classifier의 문제점들에 대해 보겠습니다. 현실에서는 variable들이 서로 연관이 있기 때문에 이렇게 독립적으로 두고 측정하는 방식은 올바르지 않습니다. MLE 관점에서는 관측되지 않은 값에 대해서는 제대로 estimation 하지 못합니다. 한 번도 관측되지 않은 값의 확률은 0입니다. 그래서 MAP를 사용해 사전정보라도 주어서 측정을 하는 방식을 사용합니다. 우리의 dataset이나 prior를 측정한 값이 충분히 좋은지에 대한 문제가 있습니다. 사실 우리가 두 번째로 언급만 문제는 항상 존재합니다. 하지만 첫 번째로 언급한 문제는 naive bayes classifier의 문제입니다.
'연구실 공부' 카테고리의 다른 글
| [논문] FIFO: Learning For-invariant Features for Foggy Scene Segmentation (0) | 2023.03.26 |
|---|---|
| [ML] 7. Logistic Regression (0) | 2023.03.06 |
| [ML] 5. Optimal Classification And Decision Boundary (0) | 2023.03.05 |
| [ML] 4. Decision Tree (0) | 2023.03.03 |
| [ML] 3. Rule Based Machine Learning (0) | 2023.03.03 |



