해당 자료는 https://m.edwith.org/machinelearning1_17/intro 해당 강의에서 제공합니다.
이번 강의에서는 우리가 어떻게 더 좋은 hypothesis를 고를 수 있는지에 대한 내용입니다.
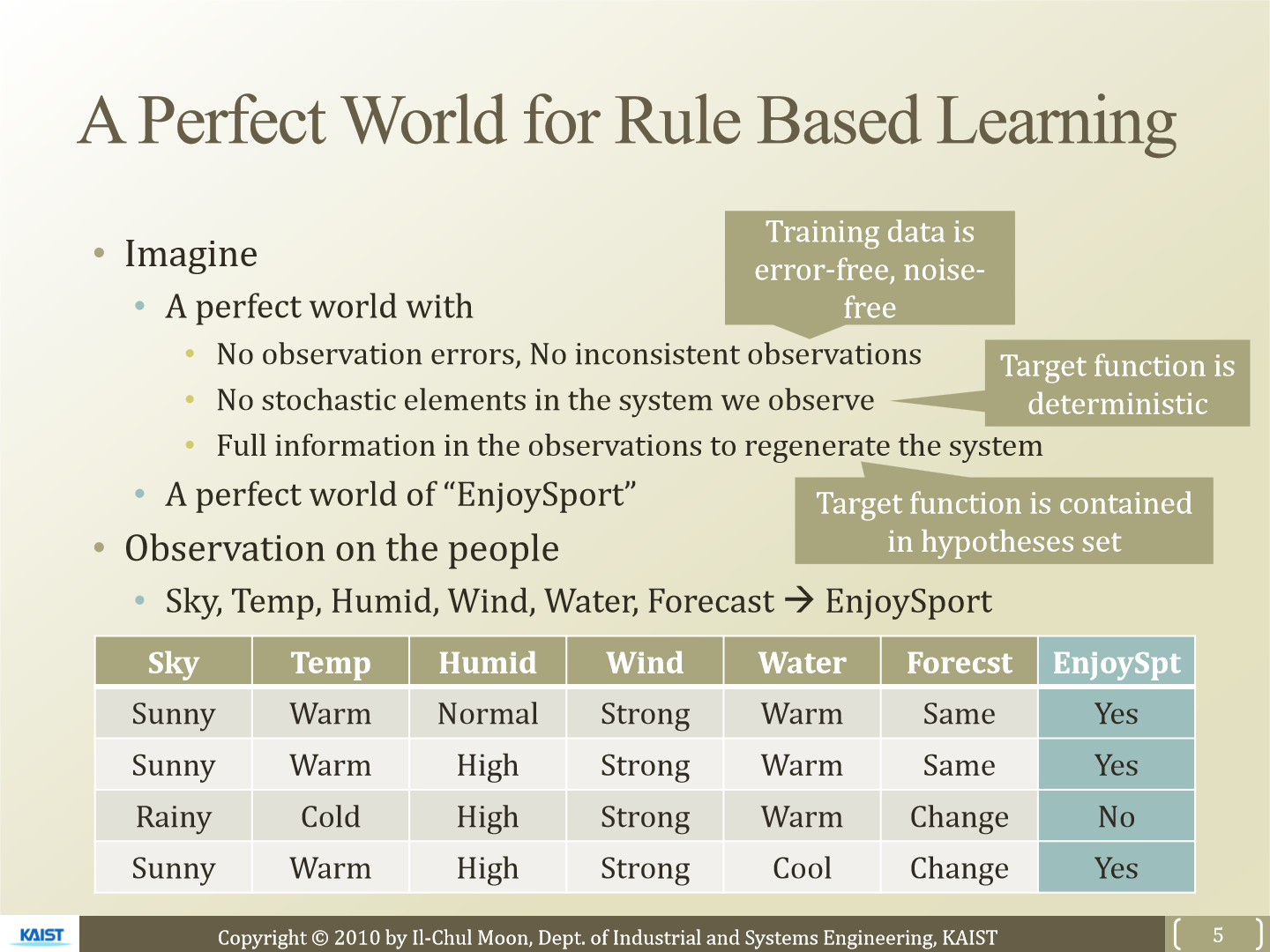
먼저 가정을 둡니다. 관측에 대한 error가 없고 항상 일관적으로 행동한다고 가정합니다. 위 표처럼 sky, temp, humid, wind, water, forecast를 보고 밖으로 나갈지 말지를 예측합니다.

위 그림처럼 instance X는 feature와 label이 있습니다. 우리는 training data D를 가지고 학습해 정확한 hypothesis H를 찾는 것이 목표입니다. X를 Y로 mapping 하는 정확한 hypothesis를 찾는 것입니다.

위 그림은 hypothesis H를 이용해 mapping한 결과를 그림으로 보여준 모습입니다. h1의 경우 Sunny, Warm만 해당된다면 yes라고 예측합니다. h2는 Sunny, Warm, Same이기만 하면 yes라고 예측합니다. general 한 hypothesis일수록 더 넓은 범위의 instance space를 포함하고 specific 한 hypothesis는 더 좁은 범위의 instance space를 포함합니다.

정확한 hypothesis를 찾기 위한 방법으로 find-S algorithm이 등장합니다. dataset D에서 instance x를 가져와 우리가 만든 hypothesis와 feature를 비교해 instance x를 포함할 수 있도록 hypothesis를 수정해나가는 방식입니다. 위 그림처럼 instance x1, x2, x4가 있을 때 진행해 보겠습니다. 먼저 아무것도 yes라고 예측하지 않는 hypothesis h0를 준비합니다. h0와 x1을 비교해 x1을 포함하도록 h0를 수정합니다. 그럼 h0는 h1처럼 수정됩니다.
이번에는 x2를 포함할 수 있도록 h1을 수정하면 위와 같이 h1, 2, 3가 됩니다. 남은 x4까지 진행하면 h1, 2, 3, 4와 같이 변경됩니다. 이렇게 정확한 hypothesis를 구하는 방식이 find-S algorithm입니다. 이 방식은 너무 많은 hypothesis가 생성되고 하나의 convergence로 모아진다고 보기는 힘들다는 문제가 있습니다.

이번에는 Version Space(VS)를 먼저 설명합니다. VS는 가능한 hypothesis의 집합입니다. 먼저 general boundary G, specific boundary S를 설정합니다. 그리고 data를 이용해 S와 G를 수정해가며 그 사이의 hypothesis들의 집합을 생성하면 됩니다. 이 집합이 VS가 됩니다.

이제 생성한 VS에서 하나씩 제거하는 방식이 candidate elimination algorithm입니다. 아무것도 yes로 예측하지 않는 S0를 생성하고 모든걸 yes로 예측하는 G0를 생성합니다. dataset에서 가져온 X의 label이 yes인 경우 S를 수정합니다. X를 cover 할 정도로만 S를 generalize 합니다. 그리고 우리가 생성한 hypothesis들 중 instance x를 받지 못한다면 제거합니다.
만약 X의 label이 no인 경우는 G를 수정합니다. X를 exclude할 정도로만 G를 specialize 합니다.

위 그림은 진행 과정을 보여줍니다. S0와 G0를 먼저 정의합니다. instance x1을 cover 할 정도로 generalize 해 S1이 생성됩니다. instance x2를 cover할 정도로 S1을 generalize해 S2를 구합니다.

이번에는 instance x3가 들어옵니다. x3의 label은 no입니다. 그렇기 때문에 G를 수정합니다. x3의 feature를 보고 그에 맞춰 G3를 specialize 합니다.

이번에는 마지막 instance x4를 보고 S3를 수정해 S4를 생성합니다. instance x4의 forecast를 보면 change입니다. 하지면 G3에 <?,?,?,?,?, Same>은 이를 cover 하지 못하기 때문에 이 hypothesis는 제거합니다.
이러한 방식으로 hypothesis를 제거하고 좁혀가는 방식이 candidate elimination algorithm입니다. 하지만 여전히 많은 hypothesis들이 존재합니다.

<sunny, warm, normal, strong, cool, change>라는 instance는 G와 S에 만족합니다. 하지만 <sunny, warm, normal, light, warm, same>의 경우 G를 만족하지만 S는 만족하지 않습니다. 이런 경우는 train data가 모자라기 때문이라고 볼 수 있습니다. 만약 이런 경우에는 VS에 있는 hypothesis에 다 비교해 결과를 얻어낼 수도 있습니다.

이러한 방식들이 존재하는데 여기서 문제는 우리가 사는 세상은 noise가 항상 존재합니다. 관측이 정확하지 않을 수도 있고 inconsistent 할 수 있습니다. 그리고 예외의 경우가 존재해 맞는 hypothesis가 제거될 수도 있습니다. 100% 확신을 갖고 yes or no라고 대답하는 것은 불가능합니다.
이를 어느 정도 해결하기 위한 방법들이 등장합니다.
'연구실 공부' 카테고리의 다른 글
| [ML] 5. Optimal Classification And Decision Boundary (0) | 2023.03.05 |
|---|---|
| [ML] 4. Decision Tree (0) | 2023.03.03 |
| [ML] 2. MAP (0) | 2023.02.28 |
| [ML] 1. MLE (0) | 2023.02.28 |
| KL Divergence, Jensen-Shannon Divergence (0) | 2023.02.18 |



