해당 자료는 https://m.edwith.org/machinelearning1_17/intro 해당 강의에서 제공합니다.
이번 강의에서는 Optimal classifcation과 decision boundary에 대한 내용입니다.

먼저 supervised learning에 대해서 얘기합니다. supervised learning은 지도 학습으로 정답 label이 주어진 상태로 학습을 하는 경우입니다. classification 또는 regression을 할 때 주로 사용합니다. 예를 들어 positive type인지 negative type인지 분류를 하는 경우가 있습니다. classification model을 잘 만들 수 있다면 regression도 금방 잘 만들 수 있기 때문에 해당 강의에서는 classification에 대해서만 진행한다고 합니다.
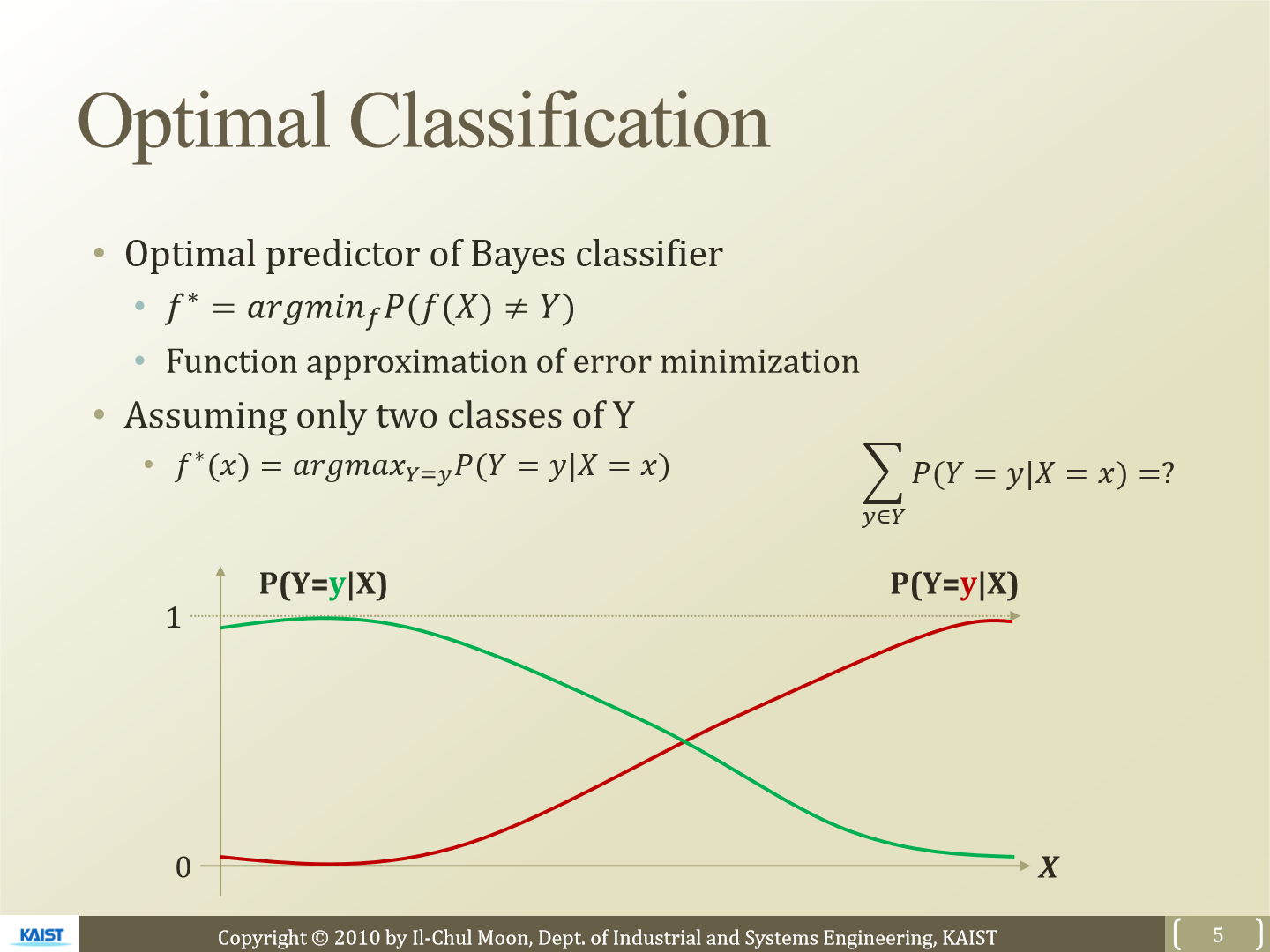
일단 위 그림에 f*를 보겠습니다. 이는 우리가 예측한 값 f(x)가 정답 Y와 다를 확률을 나타내는데 그 확률 값이 최소가 되는 function f를 의미합니다. 만약 2개의 class에 대한 assuming일 경우 이 식은 아래와 같이 argmax로 변경할 수도 있습니다. 아래 그래프는 확률을 의미하는데 X가 왼쪽에 존재할 경우 경우 초록색 값이 더 큰 것을 볼 수 있습니다. 즉 이 경우 우리는 초록색 class로 classification 할 것입니다. 반대로 오른쪽에 존재한다면 빨간색 값이 더 큰 것을 볼 수 있고 이 경우 빨간색 class로 classification 할 것입니다.

이전에 우리가 배웠던 MLE, MAP처럼 f* 식도 표현할 수 있습니다. MAP 방식을 이용해 식을 표현하면 위 식과 같습니다.
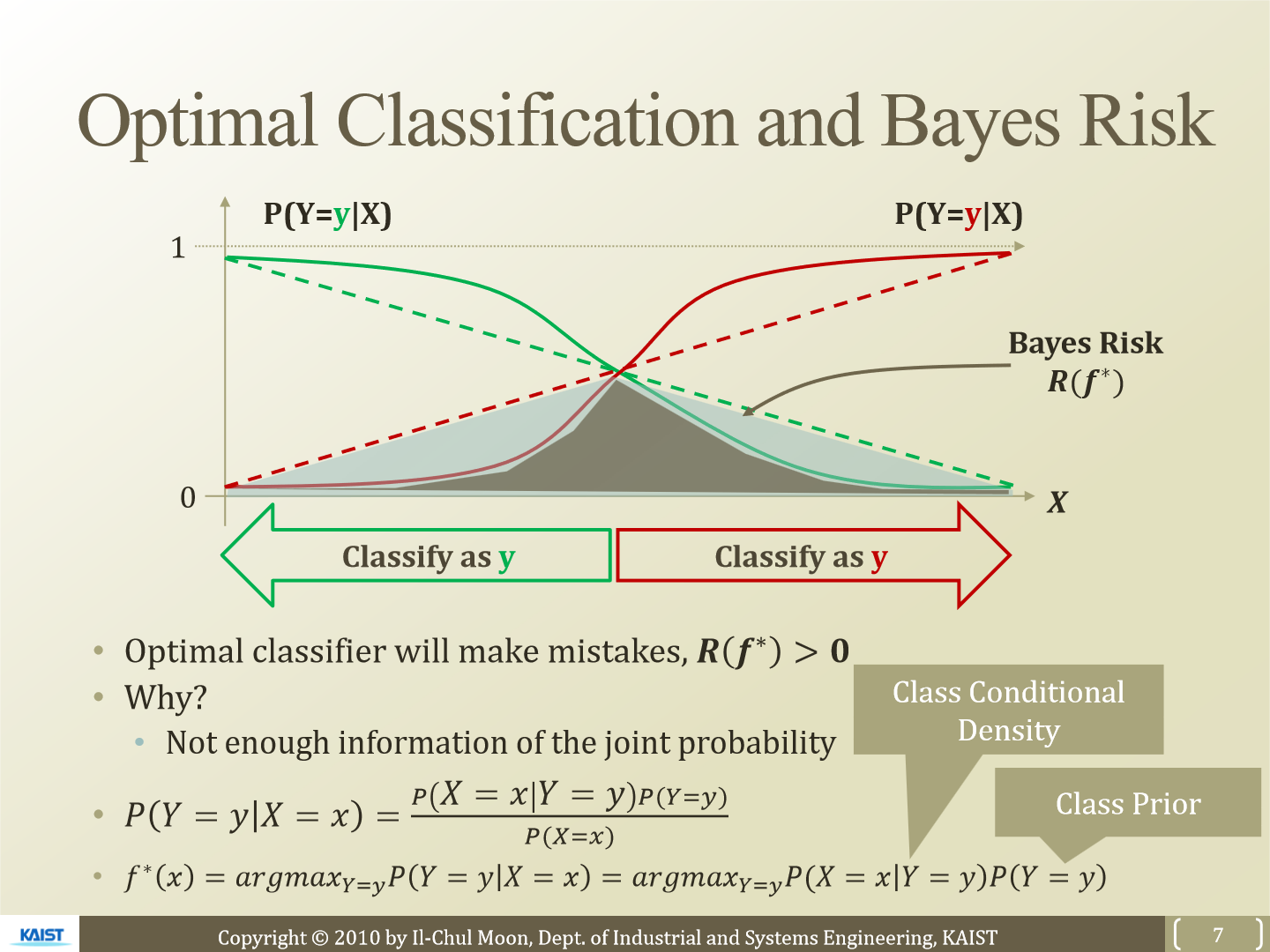
그래프를 보겠습니다. 점선, 실선 두 가지 경우가 있습니다. 두 점선이 겹치는 부분은 초록색 class로 분류할 확률이 0.5인 지점입니다. 우리가 class를 분류할 때 점선을 사용한다면 error값은 더 큽니다. 점선 두개와 X축으로 그려지는 삼각형이 error가 됩니다. 만약 실선으로 우리가 class를 분류한다면 삼각형 안에 곡선으로 이루어진 부분이 error가 됩니다. 즉 실선의 경우가 더 좋다고 볼 수 있습니다.

최적의 classifier를 찾기 위한 식은 f*인데 위와 같이 표현할 수 있습니다. P(X = x|Y = y)는 class conditional density이고 P(Y = y)는 class prior입니다. bayes rule에 의해 가능합니다. 그럼 이 두 값을 알아야 하는데 이 값을 쉽게 구할 수 없습니다. dataset D를 통해 확률들을 구하게 될 텐데 X의 feature가 상당히 많다면 combination 한 결과는 더 많아질 것입니다. 그럼 확률 값을 구하기는 힘들어집니다. 그래서 좀 더 간단하게 표현하기 위해 등장하는 것이 Naive Bayes classifier입니다.
'연구실 공부' 카테고리의 다른 글
| [ML] 7. Logistic Regression (0) | 2023.03.06 |
|---|---|
| [ML] 6. Naive Bayes Classifier (0) | 2023.03.05 |
| [ML] 4. Decision Tree (0) | 2023.03.03 |
| [ML] 3. Rule Based Machine Learning (0) | 2023.03.03 |
| [ML] 2. MAP (0) | 2023.02.28 |



