해당 자료는 https://m.edwith.org/machinelearning1_17/intro 해당 강의에서 제공합니다.
저번에는 MLE에 대해서 배웠고 이번에는 MAP에 대한 강의입니다.
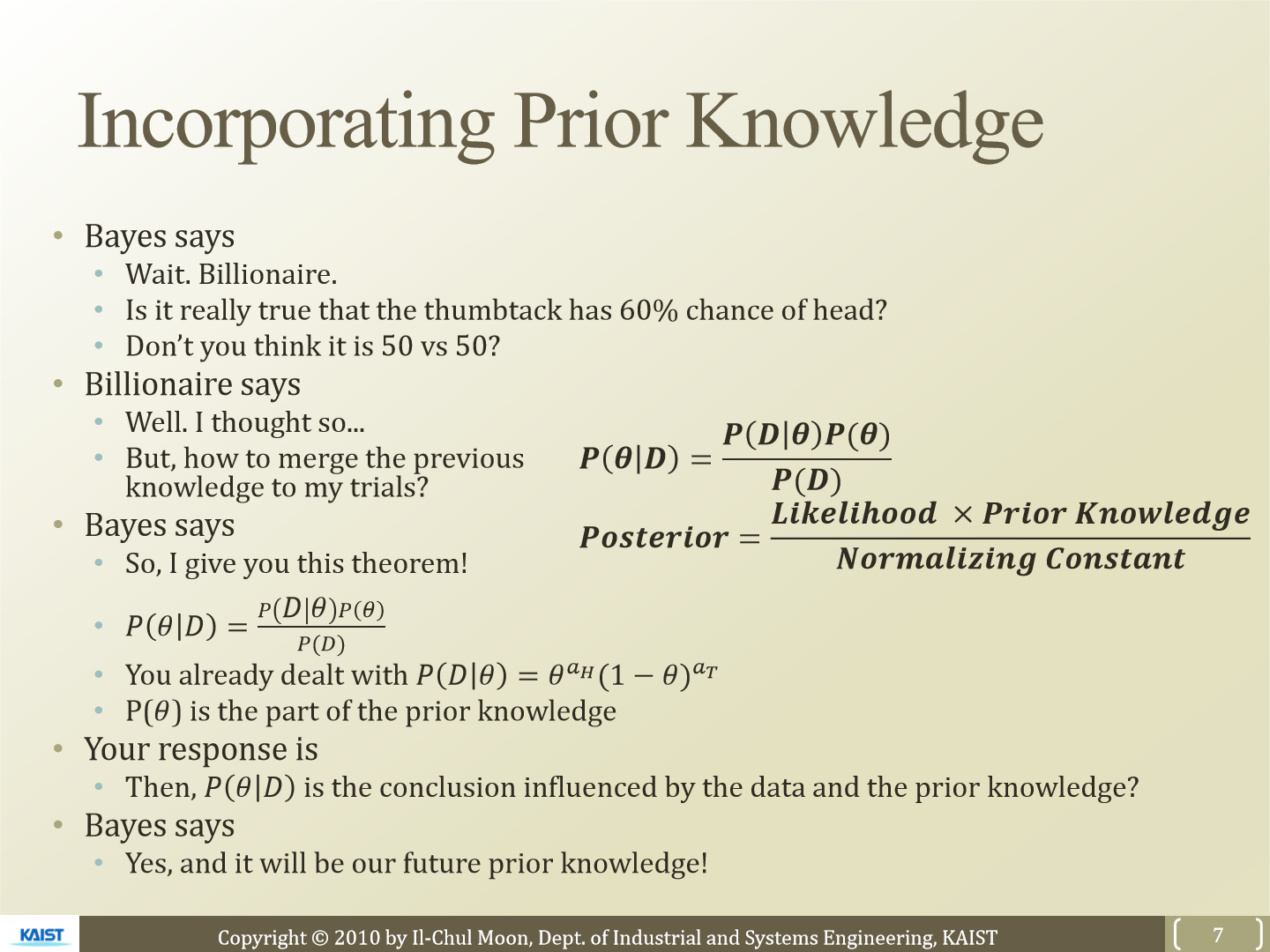
이번에는 사전정보를 가미해서 확률을 구해봅니다. 여기서 말하는 사전정보는 Θ가 됩니다. Θ가 60% 인지 50% 인지 등이 될 수 있습니다. 베이즈 정의를 통해 P(Θ|D) 식을 구하면 위와 같습니다. P(Θ|D)는 posterior, P(D|Θ)는 likelihood입니다. MLE는 이 likelihood 값을 최대로 하는 Θ를 찾는 것이 목표였습니다.
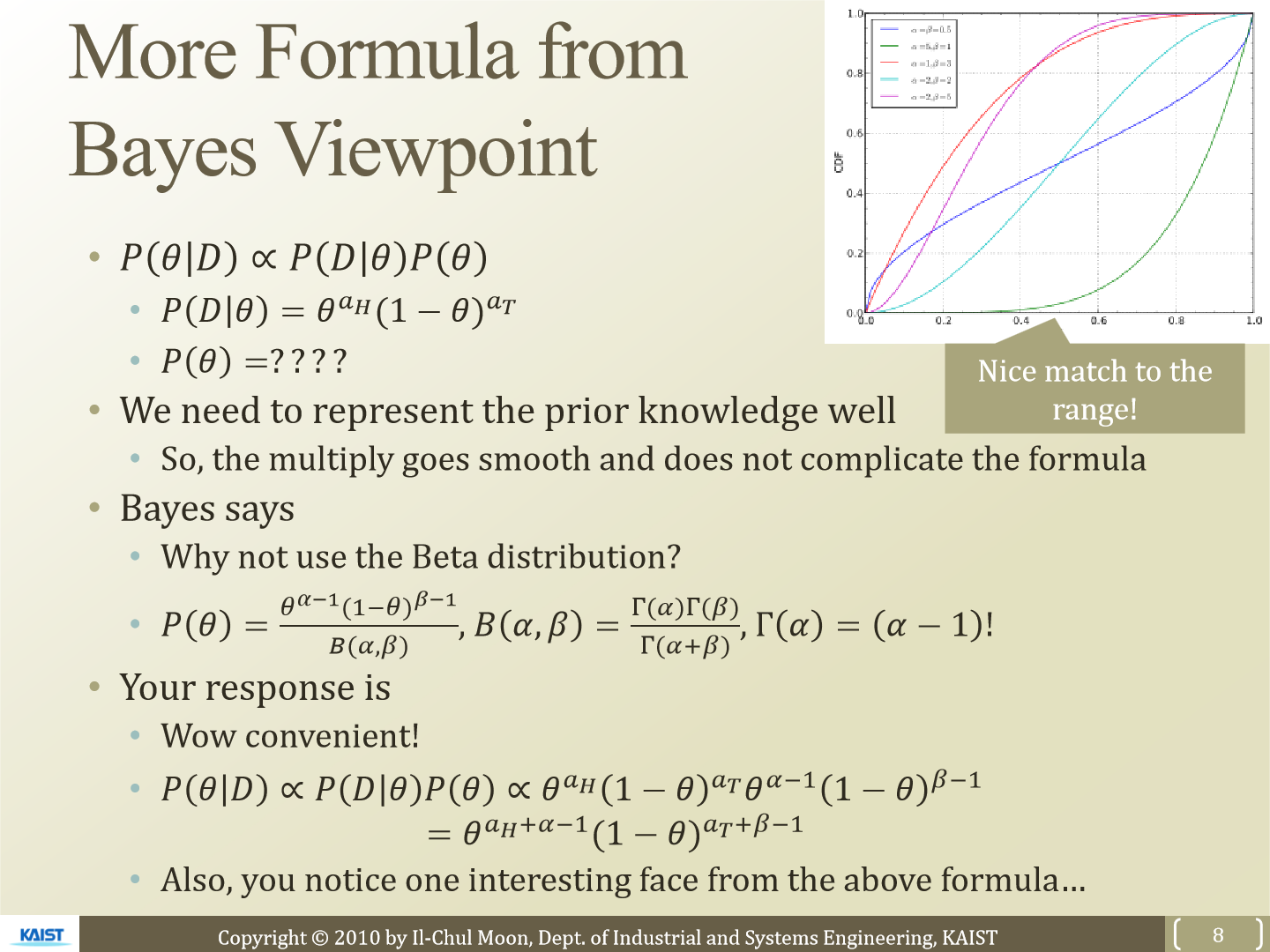
posterior는 위와 같이 비례식으로 표현 가능합니다. P(D)는 이미 관측된 데이터로 만들어진 확률이기 때문에 비례식을 위와 같이 표현가능합니다. posterior는 likelihood와 사전정보 P(Θ)의 곱으로 표현하게 됩니다. 사전정보 P(Θ)를 잘 표현하기 위해 beta distribution을 사용합니다. 우측 상단에 있는 그래프를 보면 0 ~ 1 사이의 값으로 잘 표현되는 것을 볼 수 있습니다. likelihood에서는 binomial distribution을 사용했었습니다. P(Θ)를 beta distribution을 사용해 표현하면 위와 같습니다. beta distribution은 α와 β라는 parameter를 사용합니다.
이제 이를 풀어서 표현하면 P(Θ|D)는 Θ^(α_H + α - 1) x (1 - Θ)^(α_T + β - 1)로 표현가능해집니다. B(α|β)는 Θ와 무관하기 때문에 이렇게 비례식으로 표현 가능합니다.

MLE에서 Θ'를 구할 때 미분을 사용한 것처럼 P(Θ|D)를 미분해 P(Θ|D)가 최대가 되는 Θ'을 찾을 수 있습니다. α, β를 조절하면서 사전 정보를 포함한 Θ'를 구하는 방식이 MAP(Maximum A Posterior)입니다.

MLE와 MAP 방식을 사용해 구한 Θ'는 위와 같습니다. MAP로 구한 Θ' 식을 보겠습니다. 만약 압정을 던지는 횟수가 매우 많아진다면 우리가 정한 α, β의 값은 의미가 사라집니다. 결국 MLE와 MAP 방식으로 구한 Θ'는 같은 값을 갖게 됩니다. 반대로 시행 횟수가 작다면 당연히 MAP와 MLE로 구한 Θ'의 값은 다릅니다. MAP에 사전정보로 이상한 값을 넣는다면 잘못된 값을 얻게 됩니다.
'연구실 공부' 카테고리의 다른 글
| [ML] 4. Decision Tree (0) | 2023.03.03 |
|---|---|
| [ML] 3. Rule Based Machine Learning (0) | 2023.03.03 |
| [ML] 1. MLE (0) | 2023.02.28 |
| KL Divergence, Jensen-Shannon Divergence (0) | 2023.02.18 |
| Contrastive Learning for Unpaired Image-to-Image Translation 논문 코드 (0) | 2023.02.13 |



