해당 자료는 https://m.edwith.org/machinelearning1_17/intro 해당 강의에서 제공합니다.
이번강의에서는 decision tree에 대한 내용을 설명합니다.

우리가 사는 세상에서는 inconsistent 한 data가 존재합니다. 그래서 decision tree를 사용합니다. 하나의 hypothesis에 상응하는 decision tree는 단 하나만 존재합니다.

이번 강의에서는 신용카드 발급 여부에 대한 dataset을 가지고 설명합니다. feature는 15개 존재하고 class attribute C가 있습니다. 한 가지의 feature로 +, -로 예측하거나 여러 가지 feature를 사용해 예측하는 경우는 매우 다릅니다. 그리고 어떤 feature를 사용하는지도 매우 중요합니다.

그래서 어떤 attribute를 사용하는 것이 좋은지 알기 위해 entropy를 사용합니다. entropy는 uncertainty를 측정합니다. entropy 값이 크다면 더 uncertainty 합니다. entropy를 구하는 식은 위 H(X)와 같습니다. 만약 확률을 구하는 공간이 연속적이라면 위 식에서 Σ는 ∫로 변경될 것입니다.
이번에는 조건을 추가해 entropy를 측정하는 식을 보면 위에 H(Y|X)와 같습니다. 어떤 feature가 주어지고 그에 대한 불확실성을 측정하는 것이 목표기 때문에 이 식을 사용할 예정입니다.
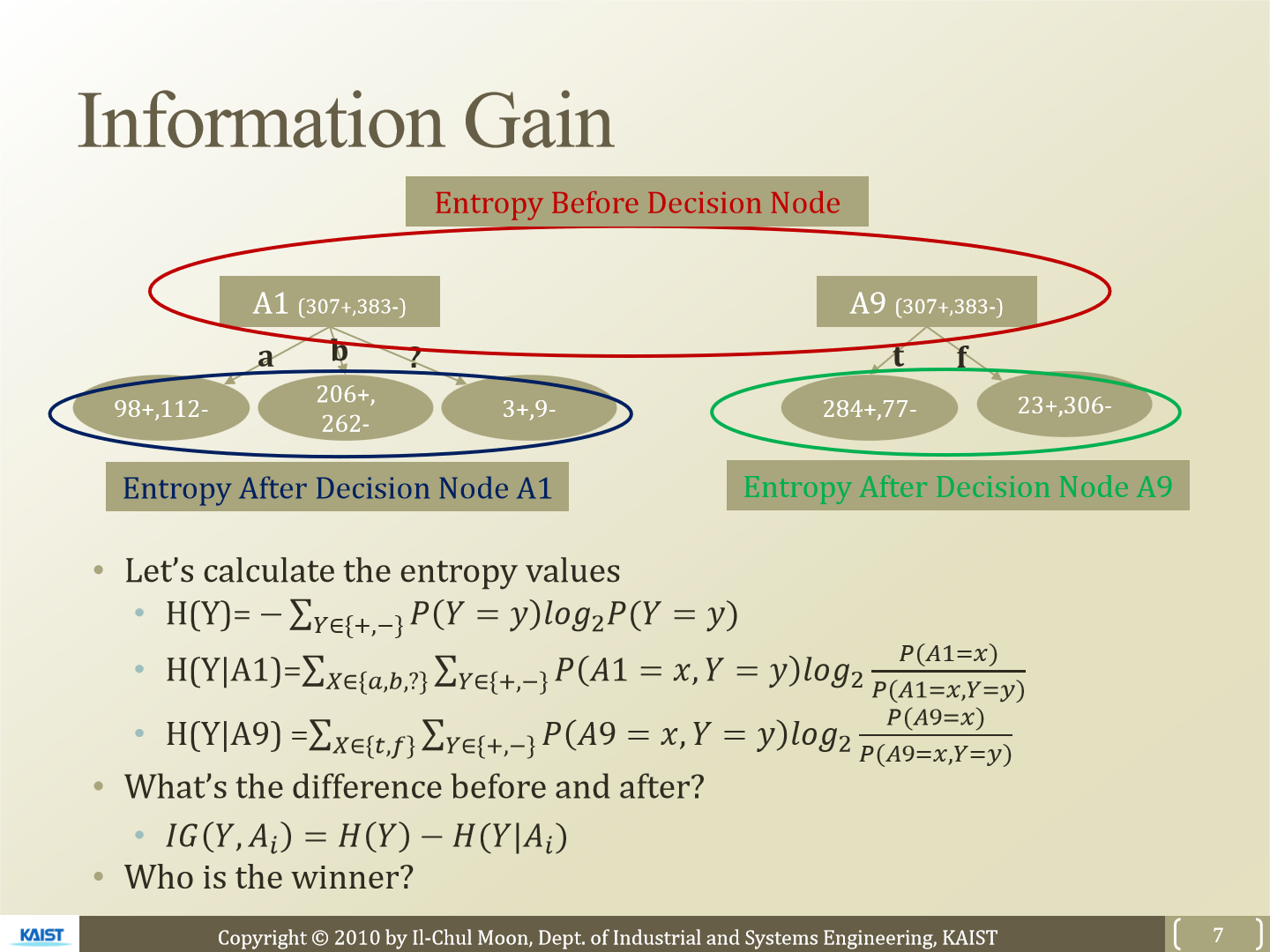
H(Y)는 Y에 대한 불확실성을 측정한 값이 됩니다. H(Y|A1)은 A1이 주어졌을 때 Y의 entropy를 측정한 값입니다. H(Y|A9)는 A9이 주어졌을 때 Y의 entropy를 측정한 값이 됩니다. 아까 확인한 conditional entropy 식에서 -를 이용해 식을 정리하면 위와 같이 됩니다.
이제 우리가 구한 conditional entropy의 값이 original entropy와 얼마나 차이가 있는지 구하는 값이 IG(Information Gain)입니다. H(Y) - H(Y|X)를 통해 IG를 구할 수 있습니다. 위 경우 A1보다 A9이 IG가 더 클 것입니다.
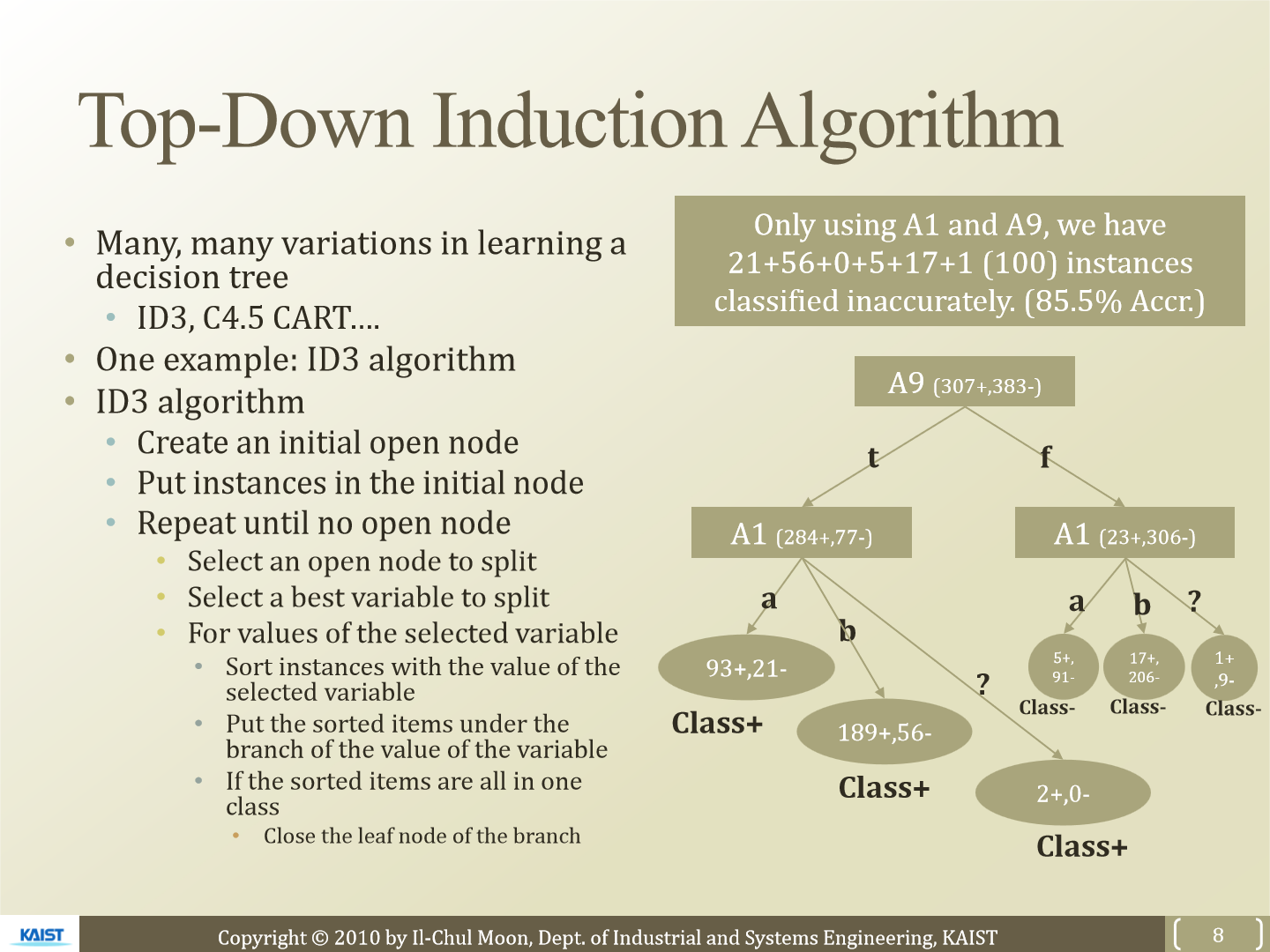
이제 각 attribute에 대한 IG를 구했고 가장 높은 값들을 이용해 decision tree를 생성하면 됩니다. decision tree를 만드는 방식은 매우 여러가지가 있는데 여기서는 ID3 algorithm에 대해 설명합니다. 가장 IG가 높은 attribute를 시작으로 decision tree를 완성하면 됩니다.
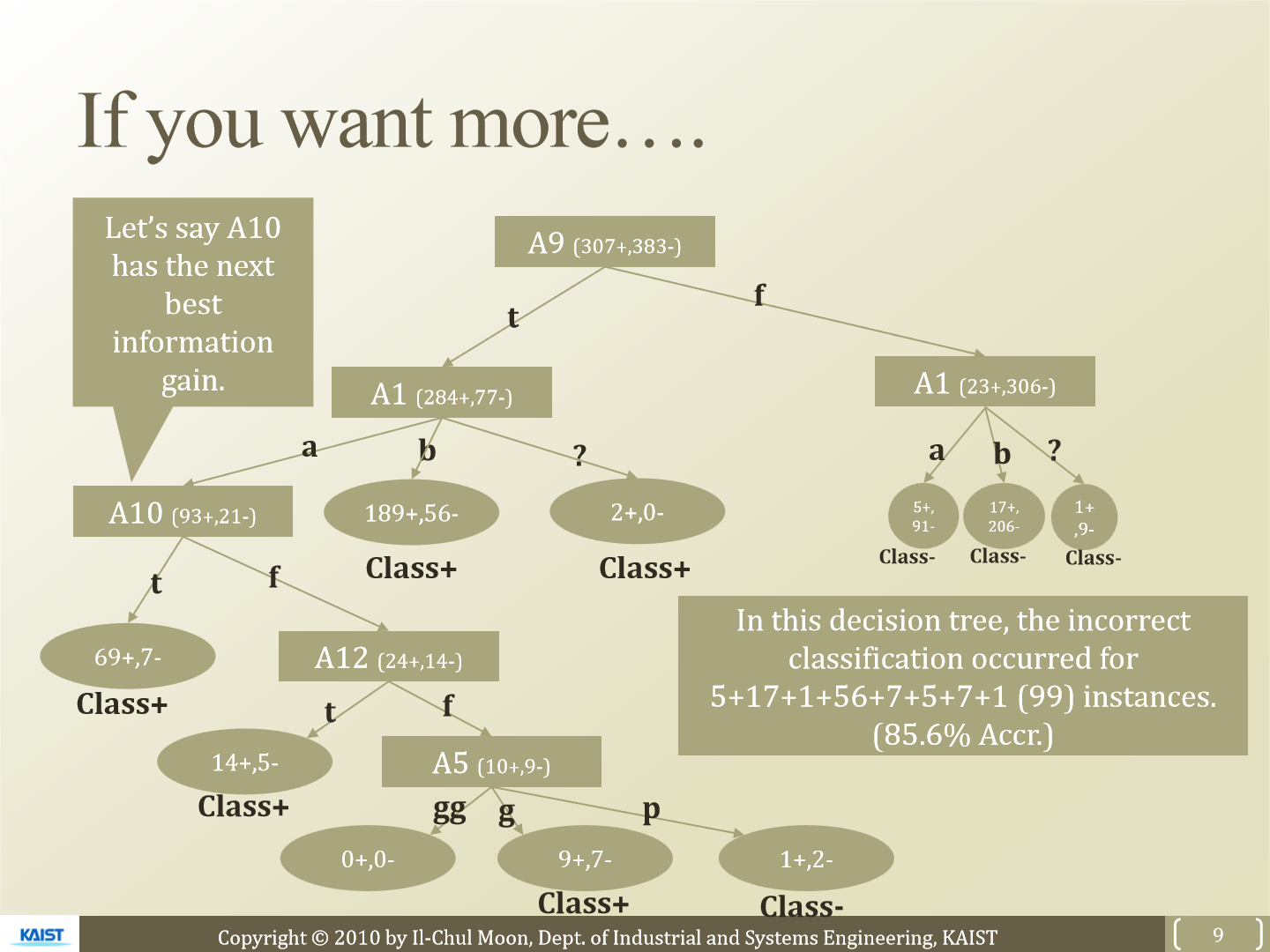
좀 더 진행하면 위와 같은 형태로 만들 수 있습니다.
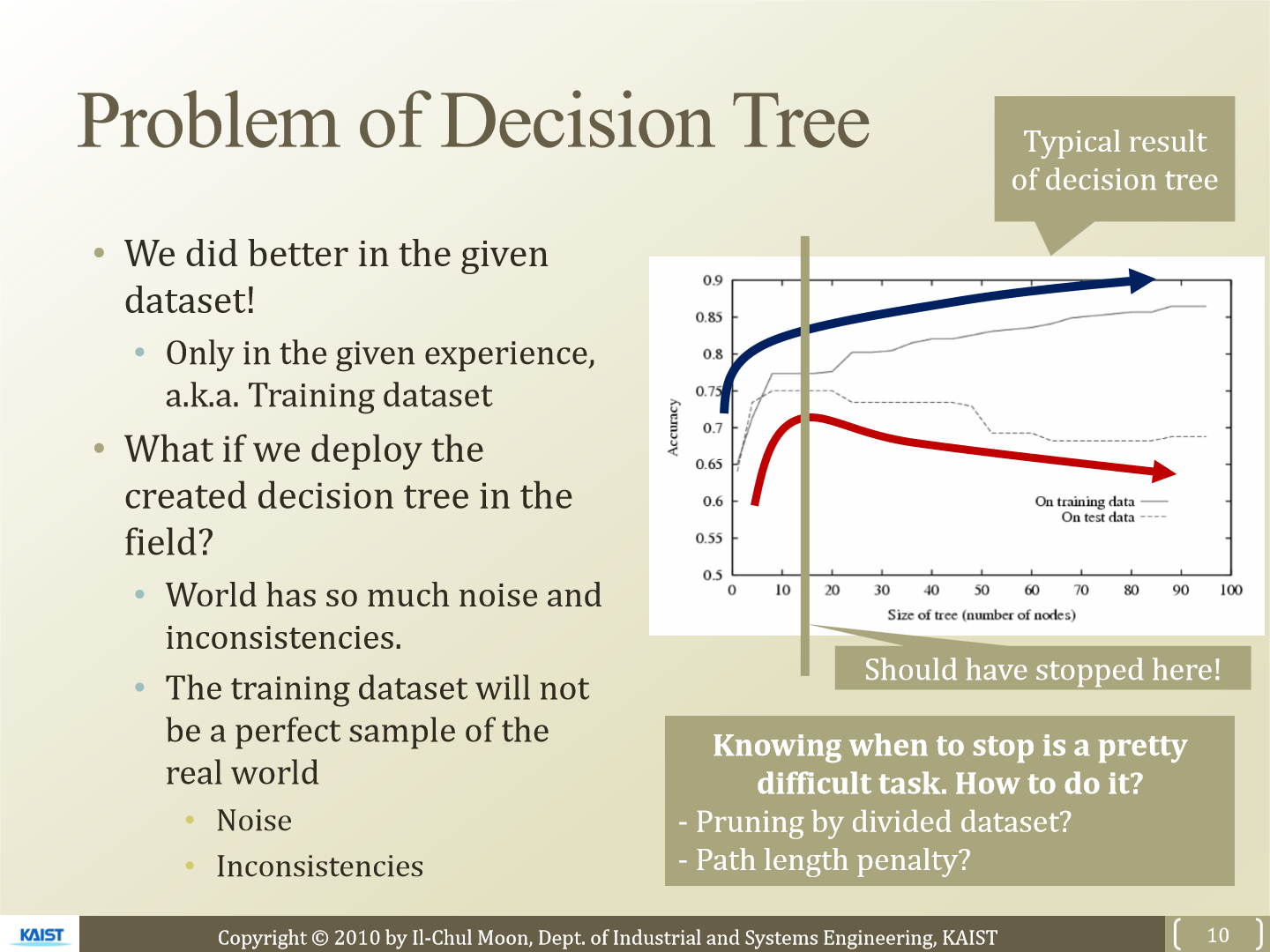
decision tree에도 문제는 존재합니다. 이전에 존재하는 data를 가지고 decision tree를 매우 세세히 만들면 전에 있던 data들에 대해서는 정확도가 매우 높을 것입니다. 하지만 앞으로 우리가 예측해야 하는 값은 inconsistent 합니다. 이러한 error가 존재하기 때문에 너무 decision tree가 전에 존재하는 data에 맞춰져 있다면 앞으로 들어오는 data에 대한 정확도는 오히려 떨어질 수 있습니다. 적당히 만들고 멈추는 것이 좋은데 그 시점을 아는 것은 어려운 문제입니다.
'연구실 공부' 카테고리의 다른 글
| [ML] 6. Naive Bayes Classifier (0) | 2023.03.05 |
|---|---|
| [ML] 5. Optimal Classification And Decision Boundary (0) | 2023.03.05 |
| [ML] 3. Rule Based Machine Learning (0) | 2023.03.03 |
| [ML] 2. MAP (0) | 2023.02.28 |
| [ML] 1. MLE (0) | 2023.02.28 |



